分布式训练推理
nn.DataParallel 和 nn.distributedataparallel,前者是单机多卡,后者是多机多卡。
- DistributedDataParallel 支持模型并行,而 DataParallel 并不支持,这意味如果模型太大单卡显存不足时只能使用前者;
PyTorch分布式训练简明教程(2022更新版) - 知乎
DistributedDataParallel 通过多进程在多个 GPUs 间复制模型,每个 GPU 都由一个进程控制,GPU 可以都在同一个节点上,也可以分布在多个节点上。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程或者说 GPU 之间只传递梯度,这样网络通信就不再是瓶颈。
从操作上来说,一般是一个 master 节点和 n 个 worker 节点,n 个 worker 节点只需要指定了 master 节点的 ip 地址那么框架层比如 Pytorch 就可以通信了。
MPI 协议 / Open MPI
MPI:很容易混淆成 Multi-process inter-connect。其实是 Message Passing Interface。
MPI 是一个通信库,或者说是一套通信原语协议,程序通过 include <mpi.h> 来进行通信。更多详细的内容可以看 [[#mpirun]]。
mpirun
现代高性能的 MPI 实现(如 Open MPI 和 Intel MPI)在配合 mpirun 启动应用时,能够并且通常会积极地自动探测底层的网络拓扑,并优先利用像 RDMA 这样的高性能网络。这是 MPI 在现代 HPC 和 AI 集群中实现低延迟和高带宽通信的关键能力。
mpirun 调用的程序里面也是要感知到 MPI 的存在的,mpirun 只是负责方便地在不同的机器间启动程序,负责设置底层通信环境(例如,告诉每个进程如何连接到其他进程,给它们分配唯一的排名 MPI_RANK 和通信域大小 MPI_SIZE,通常通过环境变量传递)。主要是一些初始化的东西。它通常会 wait 所有它启动的工作进程退出,然后自己也退出。mpirun 本身不进入你的 MPI 程序的通信域,不参与 MPI 通信,不协调 MPI 通信的进度!所以,运行 mpirun -n 4 ./your_mpi_program,总共会创建 5 个进程,1 个 mpirun 启动器进程。4 个 your_mpi_program 工作进程。
不过,mpirun 有一些配置项可以干预到进程间通信的一些参数,比如使用什么网卡。例如,mpirun -n 4 -x UCX_NET_DEVICES=mlx5_0 ./app 启动 4 个 ./app 进程,环境变量 UCX_NET_DEVICES=mlx5_0 会被传递给每个进程,进程内的 UCX 通信库在初始化时读取该变量,绑定到 mlx5_0 网卡建立 RDMA 连接。
使用 mpirun(或其等效命令如 mpiexec)运行的程序通常必须本身就是一个 MPI 程序,这意味着它需要:
- 包含 MPI 头文件: 在源代码中包含如
#include <mpi.h>(C/C++) 或 use mpi (Fortran)。 - 链接 MPI 库: 在编译链接阶段链接到 MPI 库(如
-lmpi,-lmpich,-lopenmpi等)。 - 调用 MPI 初始化/终止函数: 在程序中调用
MPI_Init(或MPI_Init_thread)来初始化 MPI 环境,并在结束前调用MPI_Finalize来终止。 - 使用 MPI 通信原语: 程序内部使用
MPI_Send,MPI_Recv,MPI_Bcast,MPI_Reduce等函数在进程间进行通信或同步。
这就是为什么直接运行 mpirun -n 4 ./ls 不行。从 MPI 的角度看,MPI_Init 从未被调用,所以 MPI 通信层实际上没有被激活或正确使用。你可能会看到类似 MPI_ABORT invoked… 或其他警告信息,因为 MPI 运行时检测到环境已创建但未被程序初始化,导致在程序退出时无法正确清理。也可能没有任何错误提示,但绝对没有并行协作发生。
一个典型的运行方式:
mpirun \
--mca plm_rsh_no_tree_spawn 1 \
# 指定能够使用的网卡
-mca btl_tcp_if_include eth0 \
-bind-to socket \
-mca pml ob1 \
# 这个表示
-mca btl '^uct' \
-x NCCL_IB_HCA=mlx5_ \
-x NCCL_IB_DISABLE=0 \
# NCCL 控制面(非数据面)
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_DEBUG=INFO \
--allow-run-as-root \
-H 192.168.0.5:8,192.168.0.5:8 \
/root/nccl-tests/build/all_reduce_perf -b 1G -e 8G -f 2 -g 1
mpirun 参数:
-
-mca btl_openib_if_include(当然也有 exclude 版本的) 指定进程间如果使用 RDMA 通信时以使用的网卡列表(如果不指定,就是所有网卡),在 Open MPI 中,当同时指定btl_tcp_if_include和btl_openib_if_include时,MPI 库通信会优先使用 RDMA(通过btl_openib_if_include指定的网卡),而非 TCP;FAQ: Tuning the run-time characteristics of MPI TCP communications -
-mca btl_tcp_if_include(当然也有 exclude 版本的):指定进程间如果使用 TCP 通信时可以使用的网卡列表,TCP 模式下(例如无 RDMA 环境),这个参数直接控制数据流; -
-mca btl:比如-mca pml ob1 -mca btl '^uct'使用默认点对点通信层(ob1),并禁用 UCX 传输(^uct表示排除)。
分布式训练通信后端
任何分布式训练的主干都基于一组彼此知晓且可以使用后端相互通信的进程。 对于 PyTorch,通过在所有分布式进程(共同构成一个进程组)中调用 torch.distributed.init_process_group 来创建进程组。
torch.distributed.init_process_group(backend='nccl', init_method='env://', ...)
常用的通信后端有 gloo,mpi,nccl。
这篇文章写的不错:分布式训练的通信后端是什么?举一个生活里的例子?_gloo通信后端-CSDN博客
Batch size in Pytorch DataLoader
Worker numbers in Pytorch DataLoader
num_workers 指定 DataLoader 使用多少个子进程并行加载数据。每个进程负责:
- 从存储(磁盘、内存等)读取数据。
- 执行数据预处理(如数据增强、归一化等)。
- 将数据组装成 batch 并送入 GPU。
每个 GPU 对应一个独立的进程,每个进程有自己的一个 DataLoader,每一个 DataLoader 都有自己的 num workers。总并行数据加载的进程数为 num_workers × num_gpus。
增大 num_workers 可提高数据预取和预处理的并行度,减少 GPU 等待数据的空闲时间(避免 CPU 成为瓶颈)。但过多的 num_workers 可能导致:如果 CPU 核心数不足,进程间的切换开销会增大。
因此,理想情况下,总 num_workers × num_gpus 应接近可用 CPU 核心数(需留部分核心给系统和其他任务)。例如:
- 8 核 CPU + 4 GPU → 每个 DataLoader 的 num_workers=2(总 8 进程)。
- 176 核 CPU + 8 GPU → 每个 DataLoader 的 num_workers=22(总 8 进程)。
如何知道 Pytorch 分布式训练使用了 RDMA?
Pytorch 不直接和网卡交互,而是使用了通信后端库比如 NCCL, GLOO 等等,NCCL 可能使用 RDMA 来互相通信。
export NCCL_DEBUG=INFO
python your_training_script.py
使用 RDMA 的迹象:
net_ib : Using [X]mlx5_0:1/IB ; OOB eth0:192.168.1.10
关键词 IB、mlx5、mlx4 表示使用 InfiniBand/RDMA。如果查看 log 发现有类似下面这些行 via NET/IB/0 那么表示使用的是传统的 RDMA;如果发现了下面这些行 via NET/IB/0/GDRDMA 那么其实使用的就是 GPUDirect RDMA。
使用 TCP 的迹象:
net_socket: Using [0]eth0:192.168.1.10<0>
关键词 socket 或 TCP 表示回退到传统网络协议。
如何进行分布式训练?
分布式训练涉及到使用 RDMA,使用 GDR 等等,可以参考下面的脚本进行容器中的分布式训练。
# privileged for getting the access to IB devices
# -v /dev/infiniband:/dev/infiniband for passthroughing the RDMA devices to container
docker run --privileged -d --ulimit memlock=-1 --ulimit stack=67108864 --gpus all --ipc=host --security-opt seccomp=unconfined --cap-add=ALL --shm-size=100G --network=host -v /root/p/mmyolo/data/coco:/dji-test/Test1 -v /dev/infiniband:/dev/infiniband -v /var/run/nvidia-topologyd/:/var/run/nvidia-topologyd/ --name mmyolo mmyolo:latest
# 创建之后后续的运行
docker start mmyolo
# 登录容器
docker exec -it mmyolo sh
# 运行测试
cd /root/code/mmyolo
## 单机 8 卡测试
bash tools/dist_train.sh configs/yolov8/yolov8_n_syncbn_fast_8xb16-500e_coco.py 8
## 多机多卡测试(TCP/IP,不使用 RDMA)
### 第一台机器上(master 节点上)
cd /root/code/mmyolo
export MLP_WORKER_NUM=2
export MLP_ROLE_INDEX=0
# 不要留空,留空的话会被设置为 127.0.0.1,无法识别 master 节点
export MLP_WORKER_0_HOST=192.168.0.24
export MLP_WORKER_0_PORT=29500
export NCCL_DEBUG=INFO # 查看 NCCL 通信详细信息 (debug RDMA)
export NCCL_IBEXT_DISABLE=1
export NCCL_IB_DISABLE=1
bash tools/dist_train.sh configs/yolov8/yolov8_n_syncbn_fast_8xb16-500e_coco.py 8
### 第二台机器上(worker 节点上)
cd /root/code/mmyolo
export MLP_WORKER_NUM=2
export MLP_ROLE_INDEX=1
export MLP_WORKER_0_HOST=192.168.0.24
export MLP_WORKER_0_PORT=29500
export NCCL_IBEXT_DISABLE=1
export NCCL_IB_DISABLE=1
bash tools/dist_train.sh configs/yolov8/yolov8_n_syncbn_fast_8xb16-500e_coco.py 8
## 多机多卡测试(with RDMA,使用 GDR)
### 第一台机器上(master 节点上)
cd /root/code/mmyolo
export MLP_WORKER_NUM=2
export MLP_ROLE_INDEX=0
# 不要留空,留空的话会被设置为 127.0.0.1,无法识别 master 节点
export MLP_WORKER_0_HOST=192.168.0.24
export MLP_WORKER_0_PORT=29500
export NCCL_DEBUG=INFO # 查看 NCCL 通信详细信息 (debug RDMA)
export NCCL_IB_GID_INDEX=3
export NCCL_IBEXT_DISABLE=0
export NCCL_IB_DISABLE=0
# 使用 GDR
export NCCL_NET_GDR_LEVEL=SYS
bash tools/dist_train.sh configs/yolov8/yolov8_n_syncbn_fast_8xb16-500e_coco.py 8
### 第二台机器上(worker 节点上)
cd /root/code/mmyolo
export MLP_WORKER_NUM=2
export MLP_ROLE_INDEX=1
export MLP_WORKER_0_HOST=192.168.0.24
export MLP_WORKER_0_PORT=29500
export NCCL_IB_GID_INDEX=3
export NCCL_IBEXT_DISABLE=0
export NCCL_IB_DISABLE=0
# 使用 GDR
export NCCL_NET_GDR_LEVEL=SYS
bash tools/dist_train.sh configs/yolov8/yolov8_n_syncbn_fast_8xb16-500e_coco.py 8
分布式推理中的各种并行模式 / 并行策略
序列并行
相对于训练,大模型推理的序列并行要复杂很多。
分布式训练中的各种并行模式 / 并行策略
参考文档:
- 大模型分布式训练并行技术(一)-概述 - 知乎
- The Ultra-Scale Playbook - a Hugging Face Space by nanotron Hugging Face 的,写的非常全非常详细。
数据并行(DP, Data Parallel)
各自用不同的数据集训练,最后把训练得到的梯度进行聚合。
专家并行(Expert Parallelism, EP) / MoE 架构
原来的模型,比如 LLAMA3, Qwen 等等都是 Dense 模型,但是后面 Mistral AI 首次推出了 MoE 模型:Mistral AI 8 个专家 -> DeepSeek R1 256 个专家。
MoE 是一种模型架构设计,将大模型拆分为多个子网络(专家),每个专家专注于处理输入数据的不同部分。通过动态路由机制(如门控网络),每个输入样本仅激活少数专家(例如 1-2 个),其余专家保持静默。这种方式能在不显著增加计算量的前提下,大幅提升模型参数量。
EP 一种分布式训练策略,专为 MoE 架构设计。其核心是将不同的专家分配到不同的计算设备(如 GPU/TPU)上,每个设备独立处理分配给它的专家计算,同时通过路由机制协调数据流动。这种并行方式解决了 MoE 模型中专家数量庞大时的计算与存储瓶颈。
大 EP
- 多个 Expert 在同一个 GPU 上:将 MoE 层的所有专家划分为若干组,每个 GPU 负责计算其中一组专家。
大 EP 其实就是:
- 专家多:比如 DeepSeek R1 有 256 个专家;
- 每个专家占的卡多,比如一个专家占 4 张卡。
大 EP 会让 All-to-All 显著变慢,因为 All-to-All 需要所有 GPU 和其他所有的 GPU 都建立连接,一起参与。
序列并行(SP, Sequence Parallel)
Colossal-AI 序列并行
背景:self-attention 的内存需求是输入长度(context length)的平方($O(n^2)$)。见 context length^。
序列并行是一种内存高效的并行方法,可以帮助我们打破输入序列长度限制,在 GPU 上有效地训练更长的序列;同时,该方法与大多数现有的并行技术兼容(例如:数据并行、流水线并行和张量并行)。
更重要的是,我们不再需要单个设备来保存整个序列。我们的序列并行使我们能够训练具有无限长序列的 Transformer。
具体来说,我们将输入序列分割成多个块,并将每个块输入到其相应的设备(即 GPU)中。为了计算注意力输出,我们将环状通信与自注意力计算相结合,并提出了环自注意力(RSA)。
Megatron-LM 序列并行
模型并行(MP, Model Parallelism)
在数据并行训练中,一个明显的特点是每个 GPU 持有整个模型权重的副本。这就带来了冗余问题。另一种并行模式是模型并行,即模型被分割并分布在一个设备阵列上。
张量并行可以被看作是层内并行,流水线并行可以被看作是层间并行。
朴素的模型并行(把模型隔成不同的层,每一层都放到一块 GPU 上):
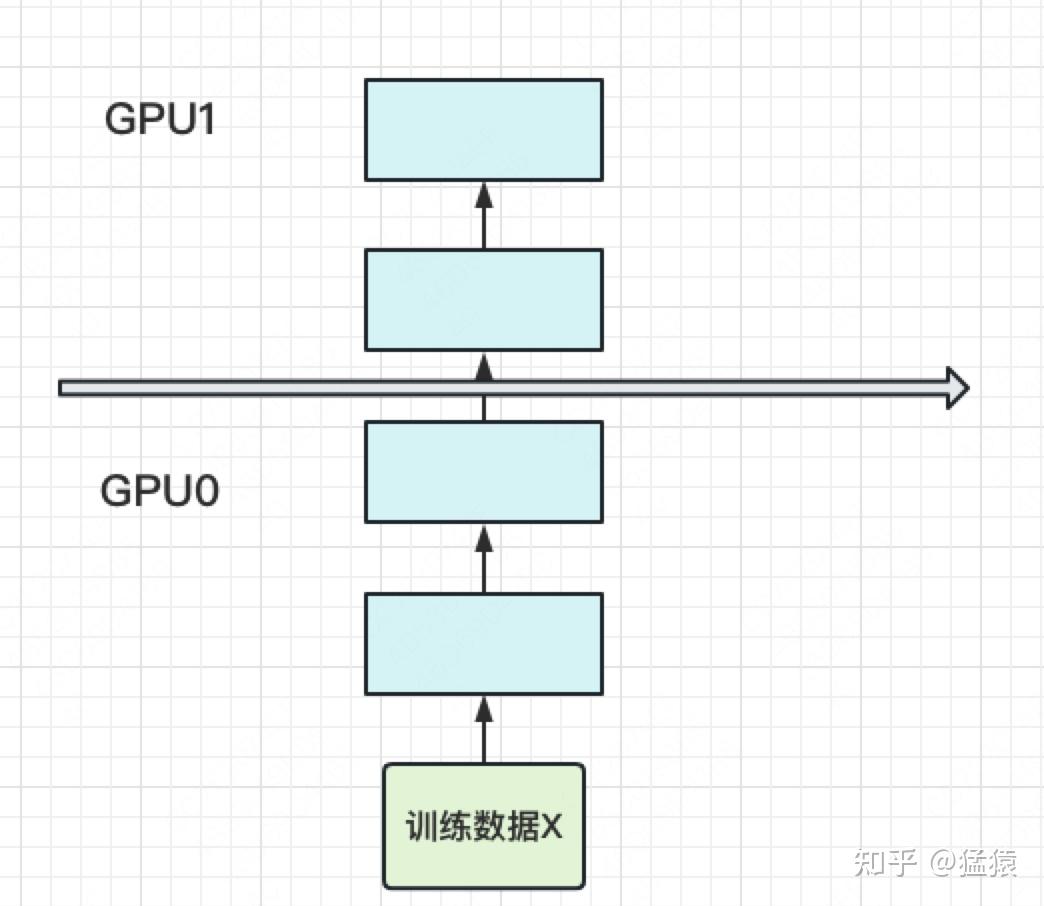
张量并行(TP, Tensor Parallelism)
属于模型并行的一种,可以理解成是竖切模型。
将一个张量沿特定维度分成 $N$ 块,每个设备只持有整个张量的 $1/N$,同时不影响计算图的正确性。这需要额外的通信来确保结果的正确性。
以一般的矩阵乘法为例,假设我们有 $C = AB$。我们可以将 $B$ 沿着列分割成 $[B0, B1, B2 … Bn]$,每个 GPU 持有一列。然后我们将 A 与每个设备上 B 中的每一列相乘,我们将得到 $[AB0, AB1, AB2, … ABn]$ 。此刻,每个设备仍然持有一部分的结果,例如,设备 (rank=0) 持有 $AB0$。为了确保结果的正确性,我们需要收集全部的结果,即沿列维串联(cat)张量。通过这种方式,我们能够将张量分布在设备上,同时确保计算流程保持正确。因此不难发现,计算过程中需要频繁的 AllReduce 同步。
相当于,本来如果有一张卡,我需要的计算量为 1,现在我有 $N$ 张卡,每一张卡上的计算量变成了 $1/N$,相当于让计算量实现了并行。
PD 分离可以和张量并行一起用吗?
完全可以,并且在实际的大型模型训练中,PD 分离与张量并行经常结合使用,形成混合并行策略。
流水线并行(PP, Pipeline Parallelism)
传统模型并行主要存在的问题是 GPU 利用度不够(GPU 越多浪费越明显,因为同一时刻都是只有一个 GPU 在运行):
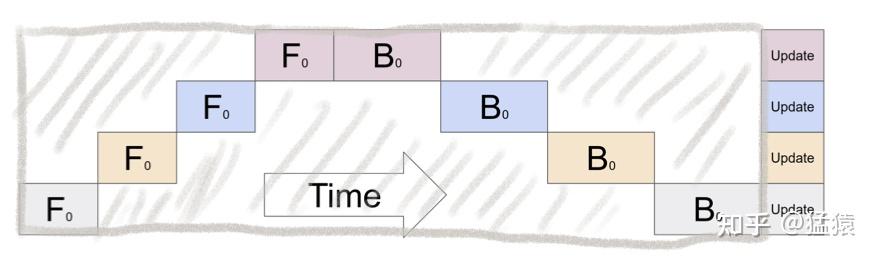
流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个 batch,送入 GPU 进行训练。未划分前的数据,叫 mini-batch。在 mini-batch 上再划分的数据,叫 micro-batch。
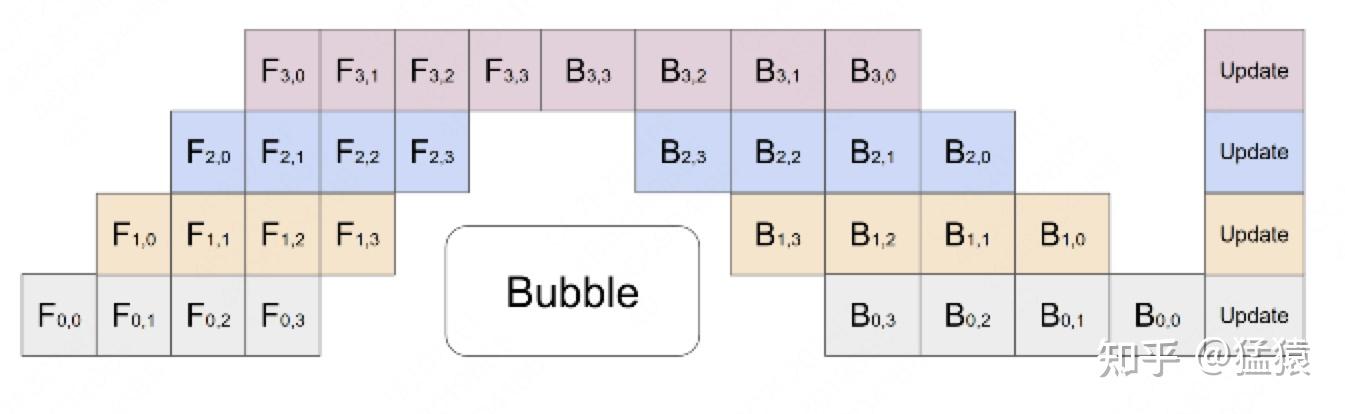
其中,第一个下标表示 GPU 编号,第二个下标表示 micro-batch 编号。
通俗理解:
- 把第一个 micro-batch 先送到第一个 GPU 进行 forward;
- 把第二个 micro-batch 送到第一个 GPU,把第一个 micro-batch 的结果输入第二个 GPU。
- …
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。