网络虚拟化
Overlay / Underlay
Overlay 网络是通过网络虚拟化技术,在同一张 Underlay 网络上构建出的一张或者多张虚拟的逻辑网络。不同的 Overlay 网络虽然共享 Underlay 网络中的设备和线路,但是 Overlay 网络中的业务与 Underlay 网络中的物理组网和互联技术相互解耦。
通俗理解,Overlay 就是经过网络虚拟化出来后的网络,而 Underlay 表示直连的物理网络。机头一般用 Overlay 网卡用来和外部或者和 VPC 其他机器通信,主要就是 CPU 侧的数据交互;机尾一般用 Underlay 网卡用来做高性能的机器间数据传输,主要就是 GPU 侧的数据交互,数据不会中转到 CPU 上。
除了上面解释,在 k8s 集群领域,节点网络都是 Underlay 网络,Pod 网络可以是 Overlay 网络,也可以是 Underlay 网络。
See: VPC 网卡直通网卡^、机头网卡机尾网卡^。
VPC 网卡和直通网卡(机头网卡和机尾网卡)
VPC 网卡是软件模拟出来的,位于 Overlay 网络。直通网卡一般是位于 Underlay 网络的,原因很简单,VM 能够通过直通网卡直连交换机。
VPC 网卡都是通过 OVS 做过网络虚拟化之后的。VPC 网卡是使用桥接模式,只不过 OVS 创建的网桥 br0 或者什么的里面使用了 VLAN 技术可以形成一个自己的私网 VPC。
竖向流量和横向流量 / 南北向东西向流量
南北向流量主要是在公网与 VPC 内的交互:虚拟机访问公网、公网用户访问私有网络内的云服务器等场景的流量均属于南北向流量。
东西向流量是数据中心环境中不同服务器之间之间的通信流量。
VPC 私有网络(Virtual Private Cloud)
为云上资源构建隔离的、自主配置和管理的虚拟网络环境。
俗话:给自己买的这些 ECS 机器开一个私网,让自己的这些 ECS 之间可以互相连接。
OVS 组件使用 VxLAN/GRE 的方式 Overlay 模式完成节点间网络平面的互通,形成自己的 VPC。
也就是需要虚拟交换机,桥接模式。
VPC-RDMA (字节 vRDMA) / 阿里云 eRDMA
在 VPC 网络内(机头 RDMA 网卡)提供 RDMA 高性能网络通信能力。并不只是需要机头是 RDMA 网卡,也需要一些其他方面的使能。
和 OVS Offload 是一个意思,把 OVS 的数据转发通路 offload 到了 RDMA 硬件上,是基于 vDPA 的吗?
见 [[#机头机尾]]
如何查看一张网卡(一般是 eth0)是 VPC 网卡还是 vRDMA 网卡(show_gids 没有用,因为已经预埋了 vRDMA 的能力)?
VM 里看不到的,不感知 vRDMA 是否开启。但是有一个讨巧的办法,vRDMA 的 MTU 是 4200,但是普通 VPC 网卡的 MTU 是 1500。
可以在 vnet 里查看一台主机支不支持 vRDMA:直接在 vnet 里输入宿主机的 ip 地址即可,右下角会展示这台机器支不支持 vRDMA,支持其实也可以不开(不勾选 vRDMA),只是预埋了这个能力。
另一种方式查看宿主机有没 vRDMA 的能力:在宿主机上执行:curl -X GET http://127.0.0.1:2929/v1/capability/show
vRDMA 在 VM 内目前没有屏蔽,即使在控制台没有勾选 vRDMA 创建的 VM,VM 里看到的 VPC 网卡也是支持 RDMA 的。目前没有屏蔽掉的规划。
如果开启了 vRDMA,所有包都走 vRDMA;如果没有开启,只有小包会走,所以会发现在里面跑测试还是可以跑通的。但是下面这个命令强制使用了大包,所以可以直接用来检查有没有开启 vRDMA:
# 强制设置使用大包
taskset -c 1 ib_write_bw -d mlx5_0 -x 3 -q 16 -D1 -s 64K --report_g --run_infinitely -F
taskset -c 1 ib_write_bw -d mlx5_0 -x 3 -q 16 -D1 -s 64K --report_g --run_infinitely -F <ip>
vRDMA 相比于 Underlay 网卡劣势:
Underlay 可以直接进行 GDR,显存里的数据不需要搬运到内存中,而是直接 P2P 到网卡发送即可;
vRDMA 仍需要先 d2h 拷贝到内存,然后 CPU 再通过传统的 RDMA 使用方式来从内存 h2d 通过 BVS 发送到 VPC 网卡上,VPC 网卡再传输出去。可以说,vRDMA 内存拷贝这一步,不是 GDR。
vRDMA 是怎么实现的?
机头网卡会虚拟化成多个 VF,这些 VF 天生支持 RDMA 同时也有一些 VPC 的能力,每一个 VF 通过 VFIO 直通给虚拟机使用。
机头机尾
See JBOG^. 一般来说一个 JBOG 就是一个机尾。
机头表示 CPU,机尾表示 GPU。也可以引申为一个表示控制面,另一个表示数据面。
机头网卡和机尾网卡的区别在于:
- 机头网卡用于 VPC 内通信,属于 overlay 网络(可用于不同高性能计算集群间的通信,或者计算集群到存储集群);
- 机尾网卡用于高性能计算集群内通信,属于 underlay 网络,都是直接连接物理网络不经过虚拟化的。
具体拓扑可以看个人飞书笔记【计算机体系结构】,一目了然。
高性能计算集群(HPC Cluster)
HPC Cluster 是一种高性能计算集群,是一个用户维度的概念(用户感知,可以创建删除),一个 HPC Cluster 可以包含多个相互能通过 RDMA 网络通信的实例。HPC Cluster 相当于高速网络中的 VPC,是 Underlay 的,需要配置物理交换机做访问控制。
注:只有高性能计算 GPU 实例才支持放在高性能计算集群内。
高性能计算集群主要是从网络角度考虑的,用于实现高性能计算 GPU 实例的逻辑隔离。属于是 Underlay 网络,也就是需要使用到真实的物理交换机:
- 同一可用区内实例间 RDMA 网络互联互通;
- 不同可用区内实例间 RDMA 网络相互隔离。
可以大幅提高大规模集群加速比,适用于高性能计算、人工智能、机器学习等大规模集群业务场景。
不要和 VPC 弄混。不通集群下的机器可以通过 VPC 互联。
高性能计算集群里面可以是虚拟机,也可以是裸金属的机器。
一个 HPC Cluster 里的机器只能是一个 BigPod 里面的,一个 BigPod 可以有很多个 HPC Cluster,但是一个 HPC Cluster 只能对应一个 BigPod。
一个 HPC Cluster 里面的机器可以跨一个 BigPod 下面的多个 MiniPod,当然一个 MiniPod 下面也有可能有多个 HPC Cluster 下面的机器,因此 HPC Cluster 和 MiniPod 之间其实是多对多的关系(如果没有亲和性调度的情况下,如果有了亲和调度,那么很有可能都调度到同一个 minipod 下面(minipod 级别亲和))。
HPC Cluster 亲和性调度
为了保证机器的临近,我们需要做一个 HPC Cluster 下面机器的亲和性调度,保证两台机器所在的物理机在网络上离得近,因此,在创建 HPC Cluster 的时候我们没有亲和信息,只有在创建了第一台机器进去的时候我们才有亲和信息(根据这台机器所在的 minipod)。
- 如果通过 API 方式绑了 HPC Cluster 的 minipod,这就是严格调度,优先从这个 minipod 里面分配机器;这个功能其实客户不感知,而是资源同学感知。
- 如果没有绑,那么可能会通过一个算法,比如说找到机器最多的那个 minipod 来开机器。
OVS
OVS 的原理主要基于 SDN,通过软件实现传统硬件交换机的功能。OVS 和 VirtIO 的 vHost 是紧密相连的,两者需要同时理解。
OVS 主要工作在机头网卡机头网络场景,机尾的 Underlay 网络不需要用到 OVS。
It has traditionally been divided into:
- a fast kernel-based datapath (fastpath,或者也叫做 forwarding plane,在内核中实现) consisting of a flow table and,
- a slower userspace datapath (slowpath,在用户空间中实现) that processes packets that did not match any flow in the fastpath.
OVS 配合 vhost-net 虚拟网卡模拟,OVS-DPDK 配合 vhost-user 虚拟网卡模拟后端。
OVS 如何连接到 vhost-net?
vhost-net 和 OVS 之间并非直接传输数据,而是通过 TAP^ 设备来连接的:
- QEMU 在启动虚拟机时,会预先创建一个 TAP^ 设备并打开文件
/dev/net/tun并将对应 fd 传递给 vhost 线程,这样 vhost 就可以和 TAP 通信; - OVS 会连接 TAP 设备的网络接口端,将其作为一个标准的网络接口连接到 OVS 虚拟交换机上。

OVS-DPDK 如何连接到 vhost-user?
因为不经过内核,所以就不需要 TAP 设备了,如下图:
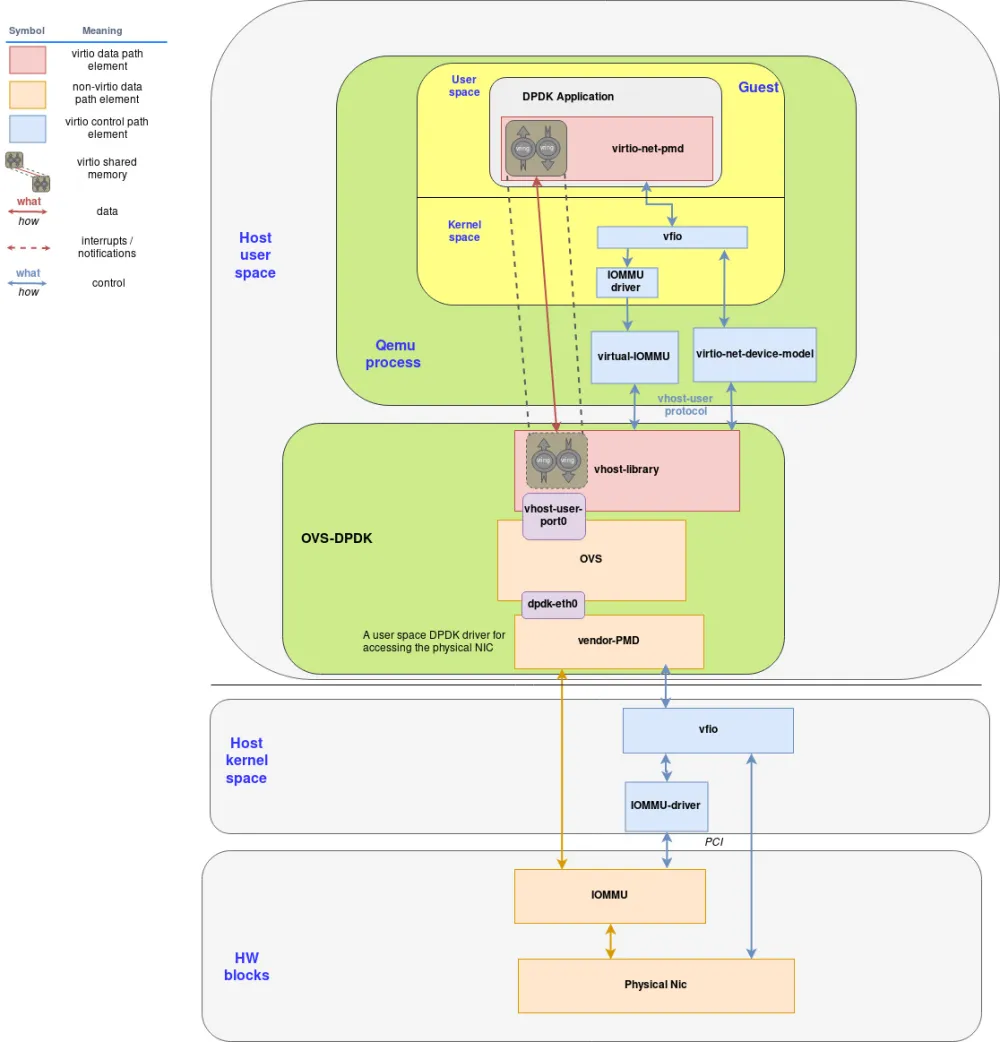
https://www.redhat.com/en/blog/journey-vhost-users-realm 这篇 RedHat 文章写的非常好,值得品读。
用户直通网卡之间的 VPC 必须要基于 OVS 来实现吗?
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。