2025-06 Monthly Archive
查看设备对应驱动
# -k: Show kernel drivers handling each device
# 没有驱动的(八卡 H20):
❯ lspci -k | grep NVIDIA
0e:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
Subsystem: NVIDIA Corporation Device 1643
Subsystem: NVIDIA Corporation Device 1643
Subsystem: NVIDIA Corporation Device 1643
Subsystem: NVIDIA Corporation Device 1643
Subsystem: NVIDIA Corporation Device 1643
Subsystem: NVIDIA Corporation Device 1643
40:00.0 Bridge: NVIDIA Corporation GH100 [H100 NVSwitch] (rev a1)
Subsystem: NVIDIA Corporation GH100 [H100 NVSwitch]
41:00.0 Bridge: NVIDIA Corporation GH100 [H100 NVSwitch] (rev a1)
Subsystem: NVIDIA Corporation GH100 [H100 NVSwitch]
42:00.0 Bridge: NVIDIA Corporation GH100 [H100 NVSwitch] (rev a1)
Subsystem: NVIDIA Corporation GH100 [H100 NVSwitch]
43:00.0 Bridge: NVIDIA Corporation GH100 [H100 NVSwitch] (rev a1)
Subsystem: NVIDIA Corporation GH100 [H100 NVSwitch]
44:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
4d:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
58:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
91:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
c1:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
ca:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
d5:00.0 3D controller: NVIDIA Corporation GH100 [H20] (rev a1)
Subsystem: NVIDIA Corporation Device 198b
# 有驱动的:
eb:00.4 Generic system peripheral [0807]: Intel Corporation Device 0b23
Subsystem: Intel Corporation Device 0000
Kernel driver in use: pcieport
eb:01.0 System peripheral: Intel Corporation Device 0b25
Subsystem: Intel Corporation Device 0000
Kernel driver in use: idxd
Kernel modules: idxd
eb:02.0 System peripheral: Intel Corporation Device 0cfe
Subsystem: Intel Corporation Device 0000
Kernel driver in use: idxd
Kernel modules: idxd
# 有驱动的(八卡 H20)
用户态驱动
好处:
- 可以和整个 C 库链接,开发更方便,同时因为是在用户态,所以调试起来也方便。
- 驱动问题不会导致整个系统挂起。
- 可以给出封闭源码的驱动程序,不必采用 GPL,更为灵活。
NUMA balance / numa_balancing
cat /proc/sys/kernel/numa_balancing
An application will generally perform best when the threads of its processes are accessing memory on the same NUMA node as the threads are scheduled. Automatic NUMA balancing(两种方式,把任务往内存移,和把内存往任务移):
- moves tasks closer to the memory they are accessing.
- It also moves application data to memory closer to the tasks that reference it.
This is all done automatically by the kernel when automatic NUMA balancing is active.
- 当发现一个进程在某个 CPU 上运行,但它访问的内存大部分在另一个 NUMA 节点时,内核会把这个进程的线程迁移到内存所在的节点的 CPU 上。
- 只有在极少数情况下(比如内存严重不均衡),内核才会做 page migration(页面迁移),把少量内存移动到进程所在节点,但这不是主要手段,成本也更高。
网关
网关是三层概念。IP 地址的网关。
子网掩码
子网掩码为什么可以在主机上配置,难道不是取决于其接入的网络吗?为什么每一个主机都要配置一个子网掩码?
大多数设备都进行路由,只是用它们自己的数据包。
子网掩码可以告诉设备,它是否可以将数据包发送到本地网络上的设备,或者它是否必须将该数据包定向到网关才能到达远程网络。
如果没有掩码,设备将假定所有地址都在本地网络上。
掩码定了一个以太网络。
如果主机 A 想向位于同一本地以太网网络上的主机 B 发送 IP 数据包,过程如下:
- ARP whohas 用于发现负责主机 B 的 IP 的 MAC 地址(除非之前已缓存)。
- 发送一个以太网数据包,该数据包的地址是主机 B 的 MAC 地址,其中包含一个以主机 B 的 IP 地址为地址的 IP 数据包。
- 这个以太网数据包将穿过构成本地以太网网络的任何交换机、集线器和电缆。
如果主机 A 想向不在同一本地以太网网络上的主机 Z 发送 IP 数据包,过程如下:
- ARP whohas 用于发现负责路由器的(或默认网关的)IP 的 MAC 地址(除非之前已缓存)。
- 发送一个以太网数据包,该数据包的地址是路由器/网关的 MAC 地址,其中包含一个以主机 Z 的 IP 地址为地址的 IP 数据包。
所以主机 A 需要知道它自己的子网掩码,以便在这两条路径之间做出决定。
ECS 有哪些形式?
不使用 DPU 的:
- ECS VM:不使用 CPU 硬件上的 CPU/MEM 虚拟化能力;
使用 DPU 的:
- ECS BMS: 裸金属服务器,保留虚拟化能力;
- ECS VM:基于 DPU 的 VM,性能通常比没有 DPU 的好,把一些数据面功能卸载到了 DPU 上。
Scale-up, scale-out
面对是 scale out 还是 scale up 的问题,老黄的答案是,“Before you scale out, scale up first."
- Scale up:扩展单机能力;
- 核心:NVLink & NVSwitch。
- Scale out:扩展集群能力。
- 核心:InfiniBand & CX8 (800Gbps) & CX9。
查看 NVIDIA GPU 驱动版本
nvidia-smi 第一行会显示出 Driver Version 和 CUDA Version。
我的飞书主页
k48xz7gzkw.feishu.cn 如果只是用文档和画板,那么不需要再登录飞书客户端。
七层负载均衡和四层负载均衡 / 七层代理和四层代理
代理和负载均衡其实差不多是同样的概念。
4 层代理和 7 层代理都是客户端和代理服务器之间建立一个 TCP 连接。然后代理服务器将请求的源地址改为代理服务器自己的地址,然后与服务端进行一个 TCP 连接。当服务端返回数据时,代理服务器将响应的目的地址改为代理服务器的地址。
4 层代理和 7 层代理的主要区别是:4 层代理不会查看报文的数据部分,比如我们的 HTTP 部分的报文。
7 层代理通常会根据 HTTP 部分, 比如请求的域名,然后根据负载均衡算法进行流量转发。 以及服务端响应的 HTTP 部分,比如说响应的数据类型 (jpeg,css,js),然后可以对特定的数据进行缓存。 即 7 层代理完全客户端和服务端之间的通信内容。
可以看到,7 层代理需要进行更多的运算。 如果我们是通过 HTTPS 进行访问,那么在代理服务器这个结点,需要进行 TLS 加密解密,并且读取 HTTP 报文中的信息。
在以前计算机性能不太好,需要实现的功能不那么复杂 (比如做缓存) 的年代,通常采用 4 层代理。并且代理服务器通常采用特殊的芯片。比如 F5,LVS。但是现在计算机性能很好。并且 7 层代理能够实现更丰富的操作。因此经常被采用。
软件也支持 4 层和 7 层代理的实现。比如 NGINX。因为代理的功能归根结底就是会操作报文就可以了。
一般都是七层
什么是 EIP?
弹性公网 IP(Elastic IP Address,简称 EIP)作为能够独立购买和持有的公网 IP 资源,主要作用是为云资源提供稳定的公网访问能力。
注意是买了 ip 不是买了网卡,登录上去之后 ifconfig 是看不到这个 ip 地址的(在使用了 EIP 的情况下,ECS 实例上只能看到自己的内网 IP)。因为这个 ip 是绑定在火山或者阿里云的网关上的。然后再通过 NAT 映射的方式映射到对应的 ECS。问题:
- 这个 ip 云服务商提前购买了吗?是的,这些公网 ip 网段是云服务商提前购买的。
EIP 支持在 ECS 实例上的弹性插拔。
如果没有 EIP,不单单是没法访问虚拟机,虚拟机里也没法访问互联网。
udev / Udev rules
❕2012 年,udev 被合并至 systemd
管理 /dev 目录底下的设备节点。udev 完全在用户空间执行,而不是像 devfs 在内核空间一样执行。现代 Linux 发行版早已不再使用 devfs,并且几乎完全基于 udev。
当设备添加或删除时(比如热插拔),udev 的守护进程监听来自内核的 uevent,以此添加或者删除 /dev 下的设备文件,所以 udev 只为已经连接的设备产生设备文件。
Udev uses rules files that determine how it identifies devices and creates device names.
-
/lib/udev/rules.d: Contains default rules files. Do not edit these files. -
/etc/udev/rules.d/*.rules: Contains customized rules files. You can modify these files. -
/dev/.udev/rules.d/*.rules: Contains temporary rules files. Do not edit these files.
C-State / P-State / CPU Turbo Boost (睿频)
C-states are idle power saving states, in contrast to P-states, which are execution power saving states.
During a P-state, the processor is still executing instructions, whereas during a C-state (other than C0), the processor is idle, meaning that nothing is executing.
A new CPU driver intel_pstate was added to the Linux kernel 3.9 (April 2009).
When a logical processor is idle (C-state except of C0), its frequency is typically 0 (HALT).
CPU cores can be completely turned off (CPU HALT, frequency of 0) temporarily to reduce the power consumption, and the frequency of cores changes regularly depending on many factors like the workload and temperature.
The processor P-state is the capability of running the processor at different voltage and/or frequency levels. Generally, P0 is the highest state resulting in maximum performance, while P1, P2, and so on, will save power but at some penalty to CPU performance. P-state 主要控制的就两件事:频率和电压。
P-state 和 C-state 是一个互补的机制:
- P-State:管的是“干活时的速度”,核心处于活跃工作状态时的性能与功耗。
- C-State:管的是“不干活时的睡眠深度”,核心处于空闲状态时的功耗。
It looks like the most reliable way to get a relialistic estimation of the CPUs frequency is to use the tool turbostat.
Typically, they are used along with algorithms to estimate the required CPU capacity, so as to decide which P-states to put the CPUs into. Of course, since the utilization of the system generally changes over time, that has to be done repeatedly on a regular basis. The activity by which this happens is referred to as CPU performance scaling or CPU frequency scaling.
CPU Performance Scaling — The Linux Kernel documentation
Intel CPUs: P-state, C-state, Turbo Boost, CPU frequency, etc. — Victor Stinner blog 3
睿频 Turbo Boost
例如:
- Base: 3.0 GHz
- 1-core turbo: 5.2 GHz
- all-core turbo: 4.4 GHz
注意:单核 turbo 通常远高于全核 turbo。
Turbo Boost allows to run one or many CPU cores to higher P-states than usual. The maximum P-state is constrained by the following factors:
- The number of active cores (in C0 or C1 state)
- The estimated current consumption of the processor (Imax)
- The estimated power consumption (TDP - Thermal Design Power) of processor
- The temperature of the processor
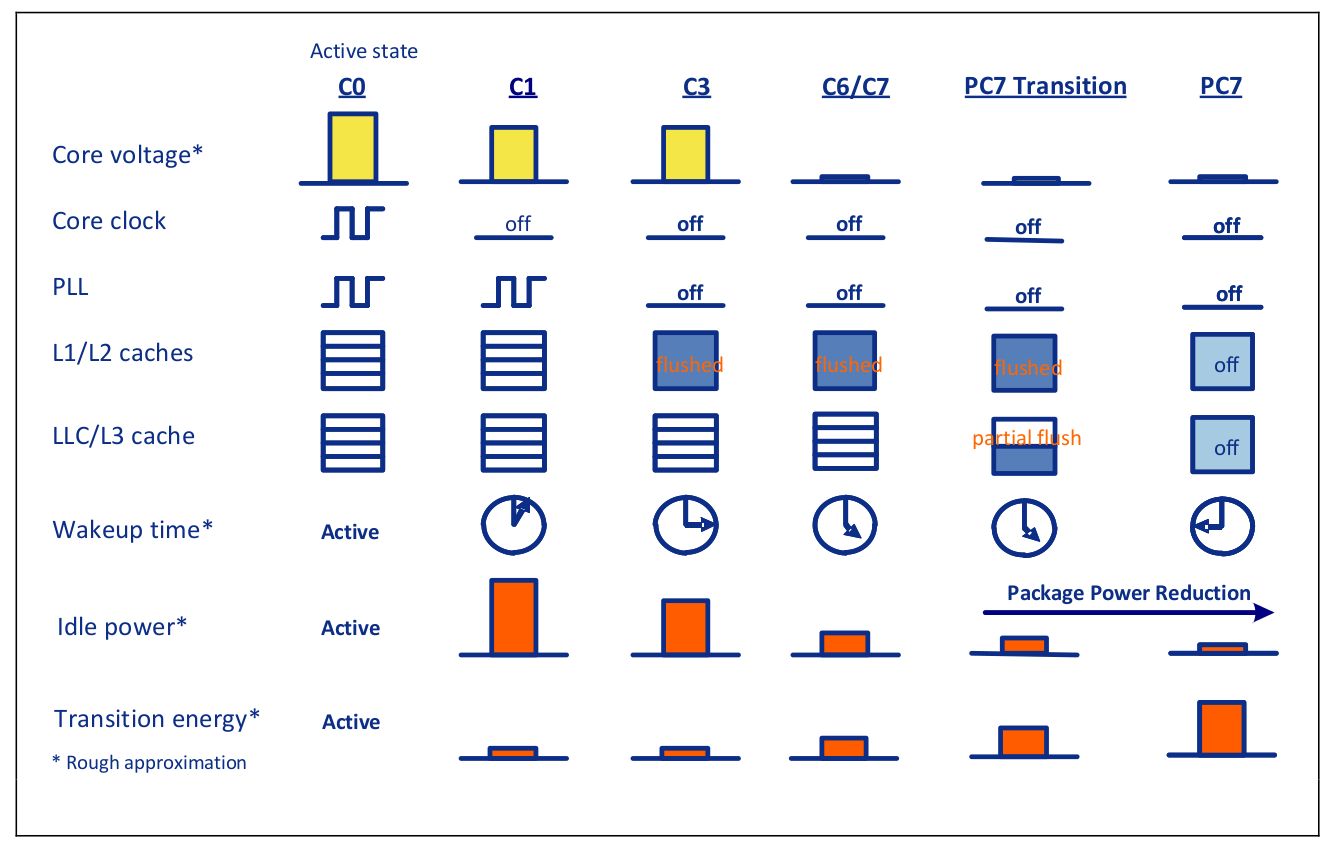
C6 C State/ cpu-pm
CPU 电源管理。相关可以看 MWAIT^。因为 C6 State 是通过 MWAIT 这个指令进入的。
The processor supports C0, C2, C3, C6, C8, and C10 package states.
打开 C6 可以提升性能的原因是:可以让空闲的核更加深度的睡眠,从而可以让未空闲的核更充分地利用功耗。
如何检查 C6 有没有打开?
# 命令
cpupower idle-info
# 输出
CPUidle driver: intel_idle
CPUidle governor: menu
analyzing CPU 0:
Number of idle states: 4
Available idle states: POLL C1 C1E C6
POLL:
Flags/Description: CPUIDLE CORE POLL IDLE
Latency: 0
Usage: 29969219
Duration: 134084770
C1:
Flags/Description: MWAIT 0x00
Latency: 1
Usage: 112995409
Duration: 885306913
C1E:
Flags/Description: MWAIT 0x01
Latency: 2
Usage: 17493031591
Duration: 2067402059601
# 注意这里有一个 disabled,没有开启 C6。
# 操作系统(Linux内核)能识别 CPU 支持 C6 State,但 BIOS 已将其禁用。
C6 (DISABLED) :
Flags/Description: MWAIT 0x20
Latency: 190
Usage: 0
Duration: 0
如何可以让虚拟机可以使用 C6 ?
- 开启物理机 BIOS 中的 C6 功能;
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。