RDMA
定义了一套新的协议栈,并且把这个新的协议栈卸载到了一个硬件上,让应用之间可以直接通信(通过用户态驱动)。
就是直接把用户程序的内存不通过内核直接 DMA 到 RDMA 网卡上的设备存储,然后进行发送。
实现上: 应用程序的内存需要被 pin 住,并且其对应的物理地址列表会被提供给 RDMA 网卡中的 DMA 引擎,从而使得 RDMA 网卡可以用这些物理地址来通过 DMA 直接读写内存。GPUDirect RDMA 的演进与实现 - 知乎
和 DPDK 的区别:[[2025-05-30-2025-05#DPDK]]。
为了将内存的访问从 CPU 中解放开来,RDMA 技术结合了 TCP Offloading Engine 和 DMA 技术,使得 CPU 从数据包复制和内存访问中都解放了开来。
In general, the drawback of offloading technologies is getting data to and from the accelerating hardware. This is where Direct Memory Access, or DMA comes in. DMA has long been utilized in hardware such as disk drives. As the name implies DMA allows a device to have direct access to memory without needing to utilize the CPU.
通常来说,RDMA 被认为包含三个主要的方面的加速:
- Zero-copy:也就是 RDMA 在发送数据时不需要拷贝,这意味着数据可以直接从用户空间发送。Zero-copy 的意思是不需要将数据拷贝到内核中,但是仍旧需要将数据发送到网卡中(设备上内存)进行传输,也就是节省了 TCP 第一部分复制的开销;为什么 RDMA 不需要拷贝到 kernel space 再发送呢?这是因为 RDMA 的数据通路驱动部分位于用户态的
rdma-core中,因此不需要陷入内核,也就不需要出于安全考虑多一次拷贝。 - OS-bypass:也就是 RDMA 可以越过操作系统来发送数据,不需要 context switch 的开销;
- Protocol offload:也就是 RDMA 可以将网络协议(非 TCP/IP)卸载到网卡上,协议处理由软件转为硬件处理,速度更快。
DCQCN
HCA (Host Channel Adapter)
在 RDMA 语境中才会有这个称呼,RDMA 语境中,也就是在 Infiniband/RoCE 规范中的网卡被称为 HCA。
RDMA 稳定性
RDMA 性能对网络故障极为敏感,少量丢包就会导致 RDMA 吞吐严重下降。
RDMA 集合通信测试
如果没有 virtualTopology.xml 这个文件,会失败,需要生成。
# 两机 16 卡集合通信测试
mpirun \
--mca plm_rsh_no_tree_spawn 1 \
# mpirun 控制端使用的低速网卡
-mca btl_tcp_if_include eth0 \
-bind-to socket \
-mca pml ob1 \
-mca btl '^uct' \
# NCCL 通信所使用的高速 RDMA 网卡
-x NCCL_IB_HCA=mlx5_1,mlx5_2,mlx5_3,mlx5_4 \
-x NCCL_IB_DISABLE=0 \
# NCCL 控制端(非数据端)通信所使用的低速以太网卡
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_IB_GID_INDEX=0 \
-x NCCL_DEBUG=INFO \
--allow-run-as-root \
-H 192.168.4.69:8,192.168.4.70:8 \
/root/nccl-tests/build/all_reduce_perf -b 1G -e 8G -f 2 -g 1
NCCL_IB_HCA 参数和 btl_openib_if_include 参数指定的 RDMA 网卡有什么区别?
注意 NCCL_IB_HCA 和 btl_openib_if_include 并没有关系,这个参数指定 NCCL 集合通信使用的网卡(是 GPU 通过 GDR 来通信使用的网卡,是直接 P2P 不过 CPU 的,也就是 GPU-GPU 之间通信使用的网卡),而 btl_openib_if_include 指定的是 MPI 库之间通信使用的网卡(是 CPU 端进程之间通信所使用的网卡),不过最好还是保持一致吧。
两种场景下通信路径是这样的(可见 MPI 这个会复杂很多):
RDMA 1-side and 2-side communication / RDMA 单边传输和双边传输
单边操作传输方式是 RDMA 与传统网络传输的最大不同,提供直接访问远程的虚拟地址,无须远程应用的参与,这种方式适用于批量数据传输。
TCP 和 UDP socket 提供的都是双边语义(接收方只有调用了 recv,才能收到包,相当于接收是主动的,而不是被动的)。
READ/WRITE 都是单边传输,SEND/RECV 是双边传输。
- 单边传输:在单边传输中,控制权主要由发送方控制。发送方直接从自己的内存中将数据传输到接收方的内存,接收方无需参与传输过程。性能高。 由客户端把数据从本地 buffer 中直接 push 到远程 QP 的虚拟空间的连续内存块中(物理内存不一定连续),因此需要知道目的地址(remote_addr)和访问权限(remote_key)。这两个信息其实反而是通过双边传输(send/recv)来交换的。可见单边传输至少在控制面上还是依赖于双边传输的。也可以看作是一种数据面加速技术吧。
- 在双边传输中,发送方和接收方都参与数据传输的控制。发送方和接收方都需要提供数据缓冲区,并通过 RDMA 操作进行数据传输。性能相对较低。
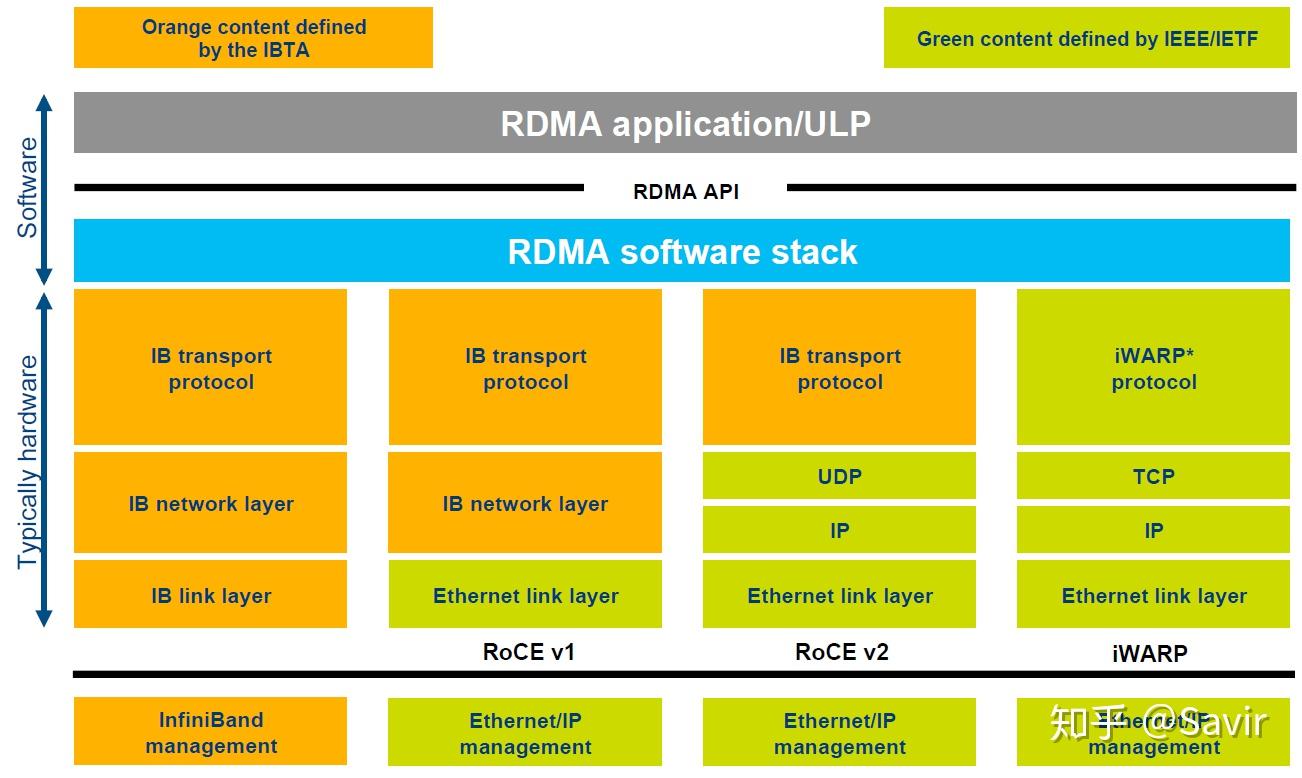
RDMA 协议 / InfiniBand / RoCE / iWARP
RDMA 是一种技术,但是因为我们定义了一套新协议栈(非 TCP/IP),这个协议栈怎么定义,如何设计,灵活性很大,因此有了多个不同的协议:
- InfiniBand
- RoCE
- iWARP
- …
投入成本:InfiniBand 的投入成本较高,需要专用的硬件和网络设备;RoCE 则可以利用现有的以太网设备进行部署,成本较低;iWARP 需要专用的网卡和协议栈,成本介于两者之间。
三种协议都符合 RDMA 标准,使用相同的上层接口。
RDMA 需要几次拷贝?/ RDMA Zero-copy
请先看:[[2025-05-30-2025-05#网卡收发包流程 / 网卡收发包需要几次拷贝?]]^
传统网卡需要两次拷贝,RDMA 一次拷贝也不需要(Zero-Copy)。没有数据从用户态到内核态再到网卡的拷贝。仅仅需要 DMA 用户内存到 RDMA 设备缓存,但这不算一次拷贝,详见 [[2025-05-30-2025-05#内存拷贝]]。
因为我们可以直接通过 RDMA Verbs 直接发送应用在用户态内存里的内容。
GID (Global Identifier) in RDMA
GID 用于标识和寻址网络中的节点设备或端口。
在传统 TCP-IP 协议栈中,使用 IP 地址来标识每个节点。而 IB 协议中的这个标识被称为 GID,是一个 128 bits 的序列。
一张 RDMA 网卡可以有多个 GID,就像一个以太网卡可以有多个 IP 地址(多网口网卡)。
是用于在网络层唯一标识 RDMA 设备端口的地址。它是 InfiniBand 架构 和 RoCE(RDMA over Converged Ethernet) 协议中的核心概念,尤其在跨子网通信时起关键作用。
ENI (Elastic Network Interface)
在云计算中是一个常见概念。
用于连接虚拟机实例(例如 AWS EC2 实例)与虚拟私有云(VPC)。它类似于物理服务器中的网卡,但具备更高的灵活性和可配置性。
rdma_rxe
The rdma_rxe kernel module provides a software implementation of the RoCEv2 protocol.
rdma_cm
rdma_cm 和 verbs 配合使用,rdma_cm 主要用于管理连接(建立和断开)、verbs 用于管理数据的收发。
rdma_cm 和 ibverbs 分别会创建一个 fd,这两个 fd 的分工不同。rdma_cm fd 主要用于通知建连相关的事件,verbs fd 则主要通知有新的 cqe 发生。
使用 rdma_cm 和不使用的区别在于,使用的话:
- 地址解析:自动将 IP 和端口转换为 RDMA 地址(如 GID、LID)。
RDMA 网络带宽测试 / ib_send_bw / ib_write_bw / ib_read_bw
见 RDMA 单边传输和双边传输^。
这三个都是 IB release 的 perftest 套件里面的 binary。
ib_write_bw 和 ib_read_bw 之间的区别比较好解释一些,一个是向对端显存写入数据,一个是从对端显存拉取数据。都是单边传输,ib_send_bw 其实是双边传输,所以说他们测试的方式是不一样的。
# 检查 InfiniBand 设备状态
ibstat
ibv_devinfo
# 测试 RDMA 通信(节点间),-q 16 表示使用所有的 qp。
ib_write_bw -a -d mlx5_1 -q 16 --report_gbits # 服务端
ib_write_bw -a -F -q 16 <server ip> -d mlx5_0 --report_gbits # 客户端
RDMA 网络连通性测试
【RDMA】RDMA通信测试工具|RDMA信息查询工具 - bdy - 博客园
有时候可以连上不一定表示可以进行网络通信,可以通过 ib_send_bw 这个工具再去测试一下网络的带宽。可能是可以连接上但是没有办法进行带宽的测试。
WQ (Work Queue) / WQE (Work Queue Element) in RDMA
请看这里:3. RDMA基本元素 - 知乎
CQ (Completion Queue) / CQE (Completion Queue Element) in RDMA
QP (Queue Pair) in RDMA
一个 QP 的性能是有限的,测试的时候可以多开几个 QP 来最大化 RDMA 网卡带宽。QP 数量上升到一定程度也会引起性能下降:
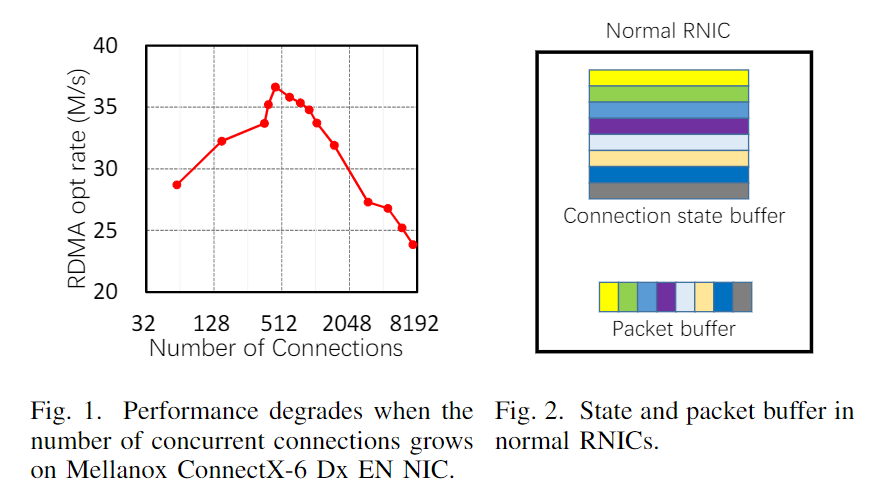
硬件是可以感知到 QP 的存在的,QP 也是存储在网卡的 SRAM 中。从本质上讲,RDMA 可扩展性以上的问题是 CPU 减负的副作用。为了在不涉及主机 CPU 的情况下完成网络传输和数据 DMA,RNIC 必须维护一系列与连接相关的状态(DMA 相关、网络相关和安全相关)。因此,当并发连接过多时,RNIC 有限的板载内存会被耗尽,它必须频繁地通过慢速 PCIe 总线从主机内存(这说明 QP 管理内容可以放在主机内存中)获取连接状态,这会严重影响性能。
QP(Queue Pair)是 RDMA 中的基本通信实体,由一个发送队列(Send Queue,SQ)和一个接收队列(Receive Queue,RQ)组成。下图一目了然:
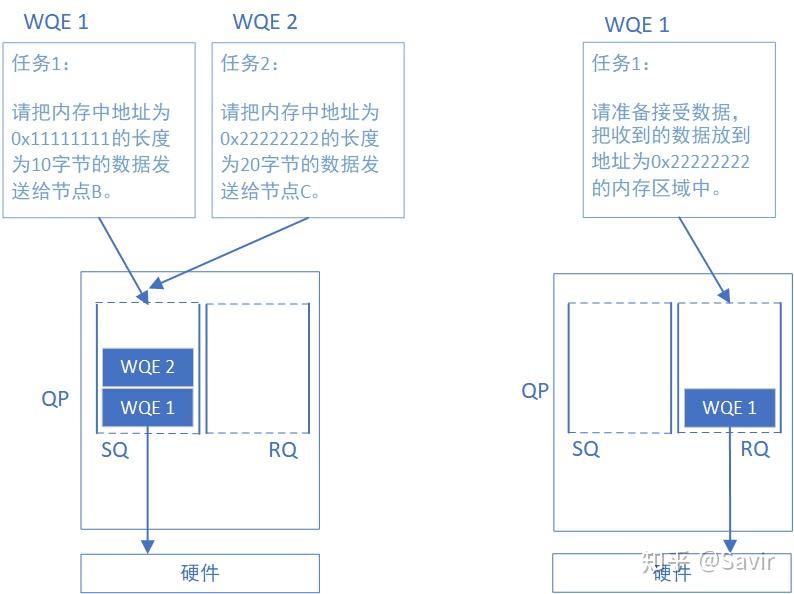
需要注意的是,在 RDMA 技术中通信的基本单元是 QP,而不是节点。如下图所示,对于每个节点来说,每个进程都可以使用若干个 QP,而每个本地 QP 可以“关联”一个远端的 QP。我们用“节点 A 给节点 B 发送数据”并不足以完整的描述一次 RDMA 通信,而应该是类似于“节点 A 上的 QP3 给节点 C 上的 QP4 发送数据”。
硬件上,QP 是一段包含着若干个 WQE 的存储空间,IB 网卡会从这段空间中读取 WQE 的内容,并按照用户的期望去内存中存取数据。至于这个存储空间是内存空间还是 IB 网卡的片内存储空间,IB 协议并未做出限制,每个厂商有各自的实现。
QP 主要是存储开销比较大。首先,当我们创建了 QP 之后,系统是需要保存状态数据的,比如 QP 的 metadata,拥塞控制状态等等,除去 QP 中的 WQE、MTT、MPT,一个 QP 大约对应 375B 的状态数据。这在以前 RNIC 的 SRAM 比较小的时候会是一个比较重的存储负担,现在新的 RNIC 的 SRAM 已经比较大了,Mellanox 的 CX4、CX5 系列的网卡的 SRAM 大约 2MB,所以现在新网卡上,大家还是比较少去关注 QP 带来的存储开销,除非你要创建几千个,几万个 QP。
QP 有三种类型(顾名思义,就是 UDP 和 TCP 的区别):
- UD(Unreliable Datagram)、
- UC(Unreliable Connected)、
- RC(Reliable Connection)。
In general, RDMA supports up to 16M QPs (since there are 24 bits for QP numbers).
在容器中使用 RDMA
# -v /dev/infiniband:/dev/infiniband 是为了保证 RDMA 设备已经透传给了容器
# --privileged 是为了让容器有足够权限使用 RDMA 网卡
docker run -v /dev/infiniband:/dev/infiniband --privileged <other args>
# 容器内:
apt-get install libibverbs1 ibverbs-utils
测试是否是互通的:
mpirun --mca plm_rsh_no_tree_spawn 1 -mca btl_tcp_if_include eth0 -bind-to socket -mca pml ob1 -mca btl '^uct' -x NCCL_IB_HCA=mlx5_ -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=eth0 -x NCCL_IB_GID_INDEX=3 -x NCCL_DEBUG=INFO --allow-run-as-root -H 192.168.0.24:8,192.168.0.19:8 /root/nccl-tests/build/all_reduce_perf -b 1G -e 8G -f 2 -g 1
RDMA 学习资料
如何确定哪一张是 RDMA 网卡
直接 ifconfig 并不能输出哪一张是 RDMA 网卡。但是我们可以对 ifconfig 的所有输出进行 ethtool -i eth0(eth0 可以替换成为需要的网卡名),如果输出的 driver 为 mlx5_core 这种类似的输出的话,那么这张网卡就是 RDMA 网卡。
RDMA 设备(如 InfiniBand 或 RoCE 网卡)通常会在 /sys/class/infiniband/ 目录下生成条目。ls /sys/class/infiniband/ 如果输出类似 mlx5_0、irdma0 等名称,则表示存在 RDMA 设备。
ibstat 也是可以输出哪些是 RDMA 网卡的。
为什么 RDMA 网卡是用户态直接 DMA 过去的,还是能在 ifconfig 的输出中看到它呢?
- 内核仍需管理设备的基础功能
- 控制路径与数据路径分离,控制路径依赖内核
- IPoIB(IP over InfiniBand)等兼容层,为了支持传统的 IP 协议。RDMA 流量和 IPoIB 流量可共存,但前者直接通过用户态 DMA 传输,后者走内核协议栈。
市场 RDMA 网卡型号
NVIDIA Mellanox(迈络思):
- NVIDIA Mellanox ConnectX,简写 CX。支持协议 RoCE,比如 CX5, CX7 等网卡型号。
RDMA Verbs
可以类比为 Sockets 在传统以太网里的定义。
不依赖操作系统,而是一套抽象的 API 定义规范。
Verbs 直译过来是“动词”的意思,它在 RDMA 领域中有两种含义。具体请看下面文章:
分为两类:
- 控制 Verbs
- 数据 Verbs
RDMA 网卡是怎么对用户态内存做 DMA 的?
RDMA 数据 Verbs 的高性能依赖于数据传输过程中的零拷贝实现。零拷贝实现要求 RNIC 具有主动发起 PCIe DMA 直接读写应用缓冲区的能力。
RDMA MTT (Memory Translation Table)
零拷贝实现要求 RNIC 具有主动发起 PCIe DMA 直接读写应用缓冲区的能力。应用在 RDMA 数据传输中使用进程虚拟地址,然而 PCIe DMA 需要总线映射后的 DMA 物理地址。RNIC 需要主动将应用缓冲区的虚拟地址翻译为 DMA 物理地址。在具体的实现中,RNIC 会缓存应用进程页表的一部分到其管理的内存翻译表(Memory Translation Table,MTT)。这样,当用户调用 verbs 发送其用户内存空间里的数据时,RNIC 就可以根据 MTT 先翻译得到进程物理地址,然后再使用物理地址设置 DMA 的起终点。
应用处于用户态,如何直接操作 RDMA 网卡的?
ib_verbs 和 rdma_cm 都是 Mellanox 公司提供的两个动态链接库,基于这两个动态链接库,向用户提供了 RDMA 原生编程 API。这两种 API 比较复杂,需要对 RDMA 技术有深入理解才能做好开发,学习成本较高。目前主流实现是利用 rdma_cm 来建立连接,然后利用 verbs 来传输数据。
控制 Verbs^ 都会经过内核态 RNIC 驱动的转发到达 RNIC 内部的控制 Verbs 处理单元。
- 控制 Verbs 和内核驱动交互的过程涉及系统调用和上下文切换,被认为是慢路径;
- 数据 Verbs 通过内存映射 I/O 的方式直接和 RNIC 内部的数据 Verbs 处理单元交互。数据 Verbs 直接访问 RNIC 的过程被认为是快路径。RDMA 的数据传输性能取决于数据 Verbs 的实现。
控制路径和数据路径:
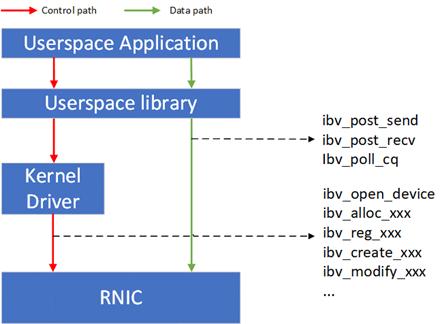
所以大部分的 RDMA 应用都是用户态应用,即使用以 ibv_ 为前缀的用户态 Verbs API。
并非所有的用户态 Verbs API 都可以完全绕开内核,本文中我来讲解一下哪些 API 依赖于内核 RDMA 子系统(包括驱动),为什么需要依赖内核,以及用户态和内核是如何交互的。
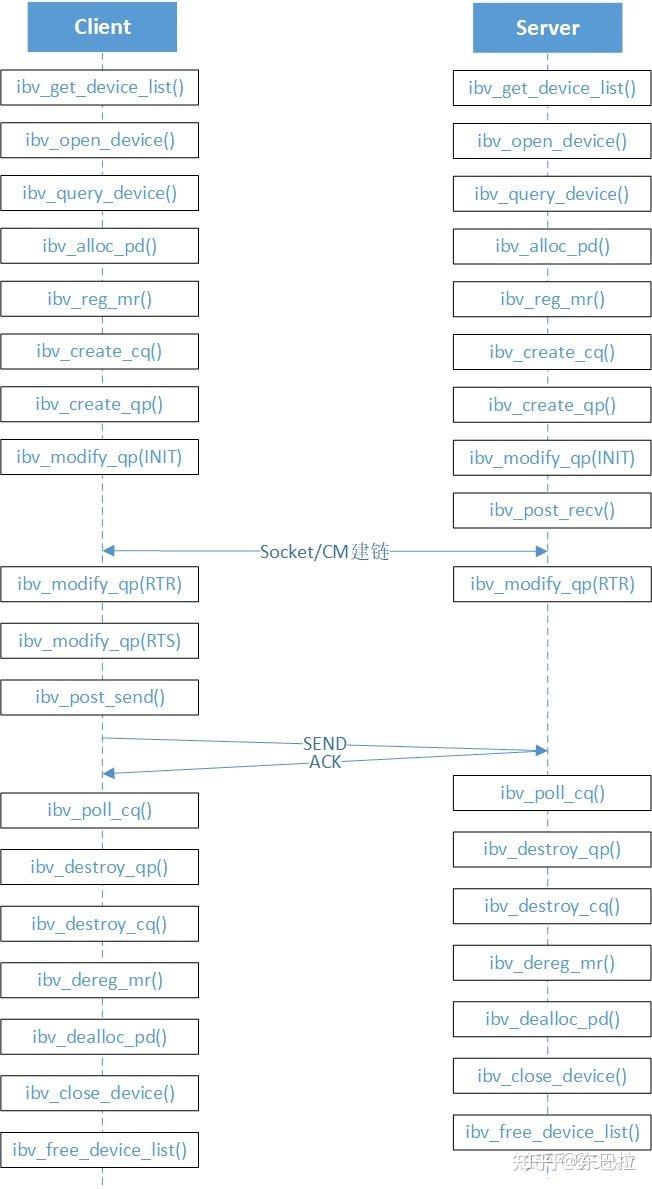
RDMA 网卡只能和 RDMA 网卡通信吗?/ RDMA 网卡支持 TCP/IP 吗?
看协议,如果是 RoCE 和 iWARP 的话,是可以通信的,如果是 IB 协议的话,不可以。
注意即使是 RoCE 和 iWARP,通信双方应用层仍然需要使用 RDMA 元语通信,而不是使用 TCP/IP sockets。
| RDMA 协议类型 | 是否依赖 TCP/IP | 说明 |
|---|---|---|
| InfiniBand | ❌ 完全不依赖 | 使用专用网络协议和硬件,与 TCP/IP 无关。 |
| RoCE (RDMA over Converged Ethernet) | ✅ 部分依赖(IP 层) | - RoCE v1:依赖以太网链路层(L2),无需 IP。 - RoCE v2:基于 UDP/IP(需要 IP 地址路由)。 |
| iWARP | ✅ 完全依赖 TCP/IP | 在 TCP 协议上实现 RDMA,需完整 TCP/IP 协议栈支持。 |
- InfiniBand 网卡不支持 TCP/IP,仅用于纯 InfiniBand 网络,需专用 InfiniBand 交换机和网卡。若需与传统 TCP/IP 网络通信,需通过 IPoIB(IP over InfiniBand) 协议转换,性能会受限。
- RoCE 网卡(v2)部分支持 TCP/IP。仅依赖 IP 层:RoCE v2 通过 UDP/IP 封装 RDMA 流量,因此需要 IP 地址,但不直接处理传统 TCP 流量(如 HTTP、SSH)。RoCE v2 流量可与普通 TCP/IP 流量共享以太网,但 RDMA 网卡仅处理 RDMA 数据,传统 TCP/IP 流量仍需走内核协议栈。
- iWARP 网卡完全支持 TCP/IP:基于 TCP 协议:iWARP 在 TCP 协议上实现 RDMA,因此天然依赖 TCP/IP 协议栈。可与传统 TCP 流量共存:但由于 TCP 的流控和可靠性机制,iWARP 的延迟和吞吐性能通常低于 RoCE 和 InfiniBand。
RDMA 支持广域网通信吗,还是仅仅限于局域网 LAN 通信?
提出这个问题原因是 RDMA 是一套单独的协议,但是现在广域网都是基于 TCP/IP 协议的,那么是不是 RDMA 只能适用于局域网(甚至只能是 L2 以太网交换机局域网)通信?
因为 RDMA 网卡大部分支持 TCP/IP,即使是 IB 也是有 IP over InfiniBand 的,所以还是可以广域网通信的。
eRDMA(阿里云神龙)
RDMA CC (Congestion Control)
InfiniBand
属于 [[#RDMA 协议]] 的一种。在所有协议中是当之无愧的核心。其规定了一整套完整的物理层到传输层规范,因为跨层太大,导致无法兼容现有以太网。除了需要支持 IB 的网卡之外,企业如果想部署的话还要重新购买配套的交换设备(网线都得用专用网线,10m 网线 1w 人民币,网卡一块 6k)。
IB 自己定义了六层网络协议(并不是 OSI 当中的 6 层),IB 是一个覆盖 OSI 传输层网络层链路层物理层 的协议。也就是重写了从 TCP 协议到底层物理信号发送的协议。这意味着其是没有办法和以太网或者说传统的 TCP/IP 网络进行通信的。
从零学习 InfiniBand-network架构(四) —— IB六层网络模型_ib网络学习-CSDN博客
IB 网卡和 IB 交换机区别
因为 IB 是一套重定义了大部分层的协议,因此不兼容以太网,需要使用专用交换机(因为重写了物理层,所以网线也要用专用的)。
一般 IB 网卡也会提供 RoCE 模式(MLX 的网卡就是支持的)。

IPoIB
应用程序可以使用传统 IP 接口,同时可以享受到底层 IB 传输带来的高性能优势。
和 RoCE 是相反的:
- IPoIB 是传统协议栈在 IB 之上(IB 是一个在所有层都有的协议,因此如果 IPoIB 会牺牲一部分 IB 的性能);
- RoCE 是让 RDMA 协议运行在传统协议栈之上。
RoCE (RDMA over Converged Ethernet)
用通俗的话讲,就是基于传统以太网的部分下层协议,在其基础上实现 Infiniband 的部分上层协议。 这就让 RDMA 也可以使用以太网局域网和互联网通信了。如果用户想要从以太网切换到 RoCE,那么只需要购买支持 RoCE 的网卡就可以了,线缆、交换机和路由器(RoCE v1 不支持以太网路由器)等网络设备都是兼容的——因为我们只是在以太网传输层基础上又定义了一套协议而已。
有两个版本:RoCE v1 和 RoCE v2:
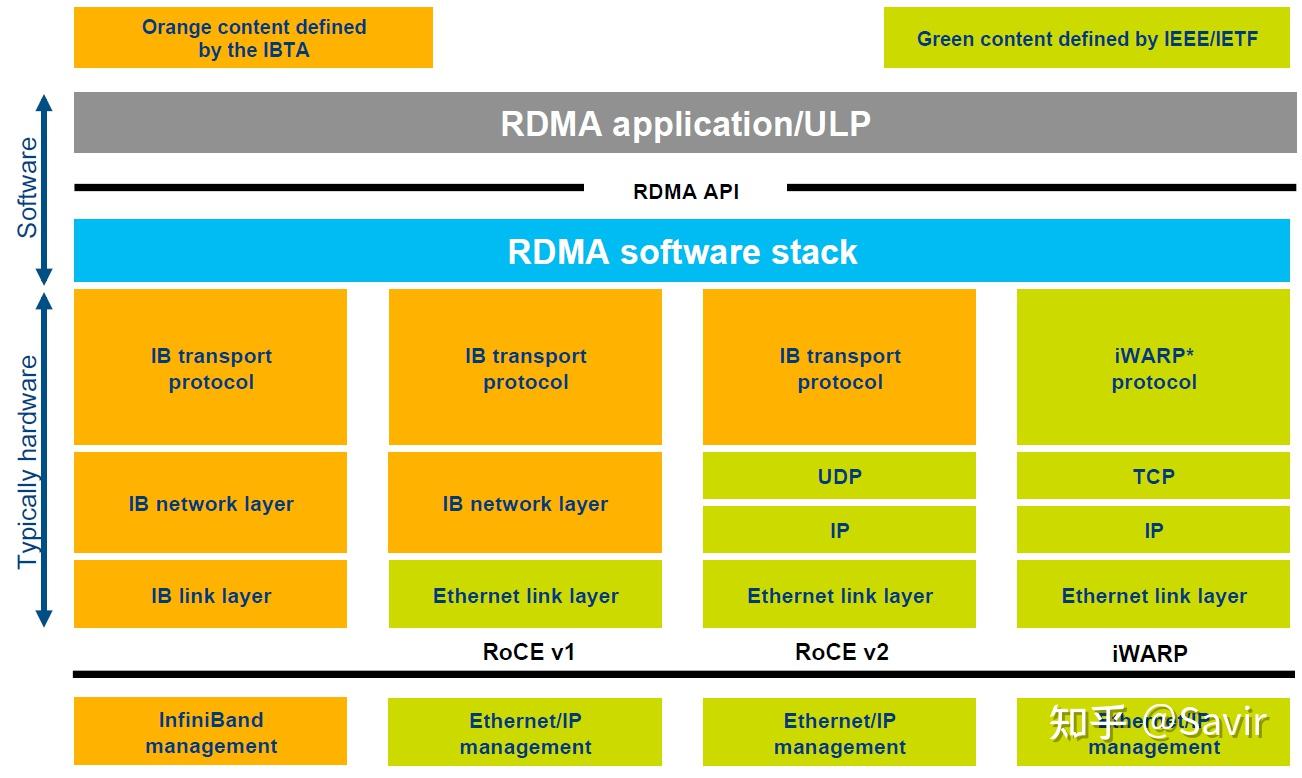
可以看到:
- RoCE v1 仅仅支持局域网以太网互联(使用 RoCE v1 协议通信的双方必须在同一个二层网络内,也就是支持了一个局域网内 RoCE v1 网卡和传统以太网卡的一个通信(传统以太网卡上不能使用传统 socket,还是要在收到包后就行软解,但是其实对端进程也默认要收到的是 IB 包,所以肯定是通过 IB 的方式接收,也就是调用了相关的底层 IB 库如 libibverbs,在库之中会有软解,但是因为发送端是支持 RoCE v1 的 RDMA 网卡,所以这部分解析不需要在软件中做,而是直接在 RDMA 网卡硬件中做了),但是没有办法出二层网络因为网络层这块路由器就已经识别不了了),不支持网络路由;
- RoCE v2 支持局域网以太网互联和网络层/传输层协议(本身 RoCE v2 的包就是封装在一个 UDP Payload 里面的,所以能够通过 UDP 转发到合适的对端进程但是不保证可靠,对端进程在收到包之后仍然需要软解 IB 包)。
Soft-RoCE
通过软件代替硬件来将 IB 传输层的报文加在普通 UDP 报文中,从而得以让普通网卡也可以发送 RoCE 报文,这对于为我们学习 IB 传输层协议,以及编写调试基于 Verbs 的 RDMA 程序提供了一种非常低成本的方案。
RoCE 组网
iWARP
iWARP 支持局域网以太网互联和网络层/传输层协议(本身 iWARP 的包就是封装在一个 TCP Payload 里面的,所以能够通过 TCP 转发到合适的对端进程同时保证可靠)。
至于 iWARP,相比于 RoCE 协议栈更复杂,并且由于 TCP 的限制,只能支持可靠传输,即无法支持 UD 等传输类型。所以目前 iWARP 的发展并不如 RoCE 和 Infiniband。
RDMA 软件栈
OFED 驱动安装
比较麻烦,得去这里手动下载:https://network.nvidia.com/products/infiniband-drivers/linux/mlnx_ofed/。
rdma-core
rdma-core 是纯用户态的,没有内核态的内容。
指开源 RDMA 用户态软件协议栈,包含用户态框架、各厂商用户态驱动、API 帮助手册以及开发自测试工具等。
rdma-core 在 github 上维护,我们的用户态 Verbs API 实际上就是它实现的。
Kernel RDMA Subsystem
看这名字就知道了,这个是 Linux 内核态的驱动。虽说名字叫做驱动,但是数据通路相关的 Verbs 主要还是用户态驱动提供的,只有一些控制通路相关的 Verbs 是内核的这部分来提供,主要是出于安全的一些考虑吧。
RDMA 子系统跟随 Linux 维护,是内核的的一部分。
- 一方面提供内核态的 Verbs API;
- 一方面负责对接用户态的接口。
所以,其实 Kernel RDMA Subsystem 和 rdma-core 的关系就像是 kernel 和 glibc 等用户态库的关系,
- 用户应用程序可以直接调用 syscall,也可以直接调用 glibc 提供的 API;
- 用户网络程序可以直接调用 kernel RDMA subsystem 提供的 kernel verbs API,也可以直接调用 rdma-core 提供的 userspace verbs API 。
OFED (OpenFabrics Enterprise Distribution)
全称为 OpenFabrics Enterprise Distribution,是一个开源软件包集合,其中包含内核框架和驱动、用户框架和驱动、以及各种中间件、测试工具和 API 文档。
注意 OFED 并不一定是 RDMA 的驱动,而是 MLX 的驱动,如果要使用 TCP,如果是 MLX 的网卡,也要安装 OFED,因为 OFED 同时支持 RDMA 和 TCP 模式,可以切换到 TCP 模式使用。
开源 OFED 由 OFA 组织负责开发、发布和维护,它会定期从 [[#rdma-core]] 和 [[#Kernel RDMA Subsystem]] 取软件版本,并对各商用 OS 发行版进行适配。
【RDMA】12. RDMA之Verbs|OFED - bdy - 博客园
RDMA 拥塞控制(PCC)
Programmable congestion control (PCC) allows users to design and implement their own CC algorithm, giving them good flexibility to work out an optimal solution to handle congestion in their clusters.
PCC 是 DOCA 里的概念(DPU 相关的)。和 ConnectX RDMA 网卡的拥塞控制没有关系。
DCQCN / BCC。
RDMA 虚拟化
在 RDMA 虚拟化的实现中,由于 Guest OS 中映射的 DMA 地址不一定连续,MTT 表中的 DMA 地址需要由 Hypervisor 提供。
全虚拟化 RDMA 虚拟化方案
RDMA 全部的数据和控制路径的全部请求都被 Hypervisor 截获、翻译以及执行,即全虚拟化 I/O 技术。
开销太大,并未在工业界和学术界调查到基于全虚拟化技术的 RNIC 虚拟化方案。
半虚拟化 RDMA 虚拟化方案
VMware 公司提出的 vRDMA 属于半虚拟化 RDMA 方案,其整体架构如下图所示:
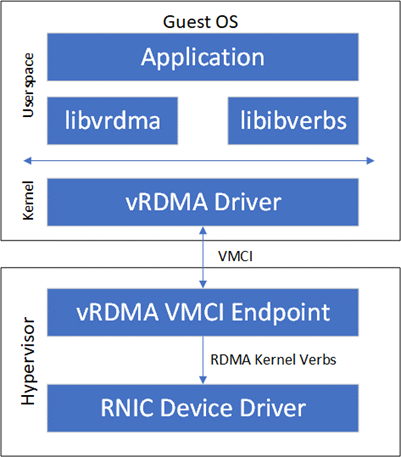
vRDMA 向 Guest OS 的 RDMA 应用提供 VMCI 虚拟设备,libvrdma 是 VMCI 虚拟设备的用户态驱动(那就是 guest 的应用程序需要知道自己是运行在虚拟机之中,因为所引用的库都已经变了),vRDMA Driver 是 VMCI 虚拟设备的内核态驱动。
同时,VRDMA Driver 也是半虚拟化框架中的前端驱动,后端驱动是 Hypervisor 中的 vRDMA VMCI Endpoint。vRDMA VMCI Endpoint 最终通过宿主机上的 RDMA 内核 Verbs 调用 RDMA 内核态驱动。
设备直通 RDMA 虚拟化方案
直通和 SRIOV 两种方案。
RNIC 以一个 PCIe 设备的形式接入到现有系统,因此最基础的硬件辅助 RNIC 虚拟化方案是采用 Intel VT-D 或者 AMD Vi 技术将 RNIC 直接绑定到一个虚拟机。直通方式能够使得虚拟机独占 RNIC,RNIC 性能可以实现零损耗。
SRIOV RDMA 的性能:SR-IOV 虚拟化 RDMA 的小消息延迟相对于非虚拟化 RDMA 只增加了 0.5us~1us,大消息延迟和非虚拟化 RDMA 无明显差距。此外,基于 SR-IOV 的虚拟化 RDMA 和非虚拟化 RDMA 的可达带宽无明显差距。 仅就 RDMA 虚拟化的性能而言,SR-IOV 可以被认为是最优的选择。
SRIOV 缺点:
- 不灵活:Mellanox ConnextX 在重新配置 SR-IOV 的 VF 数量时需要首先将 VF 数量清零(没有办法动态扩容)
- 热迁移不友好:需要在 RDMA 网卡内部集成支持虚拟网络的 2 层交互模块(L2 Switch),在将 VM 从一个主机热迁移到另外一个主机时需要重新配置 L2 Switch,硬件重配置通常被认为是不灵活的。
RDMA 混合虚拟化方案
混合虚拟化利用了 RDMA 设计中的控制 - 数据路径分离的特点,对控制路径使用半虚拟化,对数据路径采用基于内存映射的硬件直通。
-
在控制路径上,VM 中的前端驱动拦截用户态驱动的
ibv_create_qp,ibv_create_cq等控制 Verbs 转发到到 Hypervisor 中的后端驱动。后端驱动对接受到的控制 Verbs 调用实现 VM 层面的隔离、安全以及资源管控等要求后,将控制 Verbs 转发给 RNIC 设备驱动。HyV 使用成熟的 Virtio 框架实现了控制路径的前后端驱动。
控制路径的虚拟化实现:
实验评估显示 HyV 的性能和 SR-IOV 相近,在资源管理的灵活性上接近半虚拟化。以 HyV 为代表的 RDMA 混合虚拟化提出后,通过半虚拟化实现控制面和通过内存映射方式实现数据面直通硬件的方案已经成为共识。
RDMA 工具
检查 RDMA 网卡状态:ibstatus。
rping
使用 RDMA 的 ping,用来检测 RDMA 网络连通性。
show_gids
可以 RDMA 网卡对应 IP 地址。
DEV PORT INDEX GID IPv4 VER DEV
--- ---- ----- --- ------------ --- ---
mlx5_0 1 0 fe80:0000:0000:0000:0216:3eff:fe61:2ed8 v1 eth0
mlx5_0 1 1 fe80:0000:0000:0000:0216:3eff:fe61:2ed8 v2 eth0
mlx5_0 1 2 0000:0000:0000:0000:0000:ffff:c0a8:0445 192.168.4.69 v1 eth0
mlx5_0 1 3 0000:0000:0000:0000:0000:ffff:c0a8:0445 192.168.4.69 v2 eth0
mlx5_1 1 0 fe80:0000:0000:0000:c670:bdff:fef3:7bf2 v1 eth1
mlx5_1 1 1 fe80:0000:0000:0000:c670:bdff:fef3:7bf2 v2 eth1
mlx5_1 1 2 0000:0000:0000:0000:0000:ffff:1a30:4352 26.48.67.82 v1 eth1
mlx5_1 1 3 0000:0000:0000:0000:0000:ffff:1a30:4352 26.48.67.82 v2 eth1
mlx5_2 1 0 fe80:0000:0000:0000:c670:bdff:fef3:caec v1 eth2
mlx5_2 1 1 fe80:0000:0000:0000:c670:bdff:fef3:caec v2 eth2
mlx5_2 1 2 0000:0000:0000:0000:0000:ffff:1a30:4752 26.48.71.82 v1 eth2
mlx5_2 1 3 0000:0000:0000:0000:0000:ffff:1a30:4752 26.48.71.82 v2 eth2
mlx5_3 1 0 fe80:0000:0000:0000:c670:bdff:feed:5216 v1 eth3
mlx5_3 1 1 fe80:0000:0000:0000:c670:bdff:feed:5216 v2 eth3
mlx5_3 1 2 0000:0000:0000:0000:0000:ffff:1a30:4b52 26.48.75.82 v1 eth3
mlx5_3 1 3 0000:0000:0000:0000:0000:ffff:1a30:4b52 26.48.75.82 v2 eth3
mlx5_4 1 0 fe80:0000:0000:0000:c670:bdff:fef3:644a v1 eth4
mlx5_4 1 1 fe80:0000:0000:0000:c670:bdff:fef3:644a v2 eth4
mlx5_4 1 2 0000:0000:0000:0000:0000:ffff:1a30:4f52 26.48.79.82 v1 eth4
mlx5_4 1 3 0000:0000:0000:0000:0000:ffff:1a30:4f52 26.48.79.82 v2 eth4
n_gids_found=20
ib_stat
查看每一个 ib 设备具体状态。
ibdev2netdev
ibdev2netdev 查看当前系统下网卡名称与 IB 端口名称的对应关系及状态。
该命令常用于验证 IB 网卡或 DPU(数据处理器)是否被系统正确识别,并确认其与网络接口(如 eth0、ib0)的绑定关系。
将 IB 设备(ibdev)映射为网络设备是为了实现以下目标:
- Linux 内核通过 netdev(网络设备)抽象层管理所有网络硬件(以太网、InfiniBand、RoCE 等)。将 IB 设备映射为 netdev,可以让操作系统使用统一的接口(如 ip、ifconfig)管理不同硬件。
- IB 设备可以通过 IPoIB(IP over InfiniBand) 支持传统 IP 协议,使得常规网络应用(如 TCP/IP 应用)无需修改即可运行在 IB 网络上。
root@iv-ydworndog0v1ew9e2hc2:~# ibdev2netdev
bfa_0 port 1 ==> eth1 (Down)
bfa_1 port 1 ==> eth2 (Down)
bfa_2 port 1 ==> eth3 (Down)
bfa_3 port 1 ==> eth4 (Down)
bfa_5 port 1 ==> eth6 (Down)
bfa_6 port 1 ==> eth7 (Down)
bfa_7 port 1 ==> eth8 (Down)
mlx5_0 port 1 ==> eth0 (Up)
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。