2025-05 Monthly Archive
判断是公网 ip 还是私网 ip
def is_private_ip(ip):
parts = list(map(int, ip.split('.')))
if len(parts) != 4:
return False
return (
parts[0] == 10 or
(parts[0] == 172 and 16 <= parts[1] <= 31) or
(parts[0] == 192 and parts[1] == 168)
)
# 使用示例
ip = input("请输入要判断的IP地址:")
print(f"公网IP" if not is_private_ip(ip) else f"私网IP")
Ring buffer 环形缓冲区
工作原理: FIFO,两个指针,一个指向头元素,一个指向下一个空位(队尾下一个元素)。入队:rear = (rear + 1) % capacity,出队:front = (front + 1) % capacity。
优点:ring buffer 基本上是经过几十年探索后高性能 IPC 的最优解了,这东西又简单又对 cache 友好,还对同步友好。吞吐高的时候对着 ring buffer 跑 busy polling 秒杀中断,讲究一个力大砖飞。NVMe 跟网卡队列就都是 ring buffer。这块的套路就是中断嫌慢了就 busy loop。go 的 channel 里面也是个 ring buffer。高性能交易系统也用 ring buffer。
Ring buffer 为什么对 cache 友好?
局部性很好,内存空间连续,只有从队尾回到队头才会破坏连续性。
L1, L2, L3 (LLC) Cache
L1 和 L2 Cache 都被两个 HT 共享,且在同一个物理 Core。
NUMA Node 之间不共享 L3 cache。一个 NUMA Node 内的不同 core 之间共享 L3(或者准确来说,L3 是被多个不同的 cores 来共享的)。
在大多数现代 CPU 的设计中,只有 L1 缓存会区分为指令缓存(iCache)和数据缓存(dCache),而 L2 和 L3 缓存通常是统一缓存(不分指令和数据)。
LSB Module
LSB = Linux Standard Base。
SWIOTLB / iommu=soft / bounce buffer
下面这段来自于 DMA and swiotlb — The Linux Kernel documentation 的话对于 SWIOTLB 介绍的非常清楚。
swiotlb is a memory buffer allocator used by the Linux kernel DMA layer. It is typically used when a device doing DMA can’t directly access the target memory buffer because of hardware limitations or other requirements. In such a case, the DMA layer calls swiotlb to allocate a temporary memory buffer that conforms to the limitations. The DMA is done to/from this temporary memory buffer, and the CPU copies the data between the temporary buffer and the original target memory buffer. This approach is generically called “bounce buffering”, and the temporary memory buffer is called a “bounce buffer”.
比如,正如这里 DMA and swiotlb — The Linux Kernel documentation 所述:TDXIO 就是用 SWIOTLB 的 bounce buffer 做的。需要在 guest kernel command line 里指定使用 SWIOTLB。
iommu=soft: Use software bounce buffering (SWIOTLB). This can be used to prevent the usage of an available hardware IOMMU.
ARP 协议
主机和路由器上都有一张 ARP 表,记录 IP 与 MAC 映射关系。
主机的 ARP 表在内存中(注意不在网卡上),比如如果要改 Linux 系统的 ARP 表空间大小,需要改:
/proc/sys/net/ipv4/neigh/default/gc_thresh1
/proc/sys/net/ipv4/neigh/default/gc_thresh2
/proc/sys/net/ipv4/neigh/default/gc_thresh3
ARP 的整个流程,这篇文章讲的比较清楚:ARP的原理与基本流程 - banban's Blog
概括来说,ARP 是三层设备玩的东西,也就是说这是 OS 的协议栈来玩而不是网卡来玩的(网卡是 2 层设备),【Linux 内核网络协议栈源码剖析】ARP地址解析协议_linux arp命令源码-CSDN博客 这篇文章可以看出来 ARP 包在内核中是怎么解析或者说怎么发送出去的。
这也就意味着,当我们把一个 IP 地址绑到一张网卡上时,并不是写了网卡的什么寄存器告诉了网卡其 IP 地址是多少,而是记录在了主机内存里面,在主机内存里面以软件的形式和网卡进行了对应。
统计所有 CPU 的 CPU 利用率之和
mpstat -P ALL 1 1 | awk '/Average:/ && $2 ~ /[0-9]+/ {sum += 100 - $NF} END {print sum "%"}'
什么是信任根,和 TCB(可信计算基)是什么关系?
热备/冷备
热备:在不停机情况下对主数据中心进行备份,一般用于保证服务正常不间断运行,用两台机器作为服务机器,一台用于实际数据库操作应用,另外一台实时的从前者中获取数据以保持数据一致。如果当前的机器熄火,备份的机器立马取代当前的机器继续提供服务。
冷备:只有主数据中心承担业务,在停机情况下对主数据中心进行备份,当目标设备发生故障或停机后,冷备设备才开始由停机等待状态进入启动运转状态,并承担起故障设备的工作任务。
带内带外
带外:指在服务器正常运行时,通过专门的管理通道对服务器进行监控、配置和控制,而无需依赖服务器的主操作系统。
和 BIOS, OS 是相互独立的:
scp 通过跳板机拷贝
# 下载
scp -o 'ProxyJump 跳板机' -r 目标服务器:目标文件或目录 本地文件或目录
# 例子
scp -o 'ProxyJump 10.174.51.54' -r root@101.126.15.44:/root/profile.svg ~/profile.svg
####################################################################################################
# 上传
scp -P 22 -o 'ProxyJump 跳板机' -r 本地文件或目录 目标服务器:目标文件或目录
scp -P 22 -o 'ProxyJump admin@192.168.1.100 -p 22' -r ./12533.dump user@192.168.1.110:/user/bin/12533.dump
# 例子
scp -o 'ProxyJump 10.174.51.54' -r ./12533.dump root@101.126.15.44:/root/profile.svg
Pytorch DDP (DistributedDataParallel) / 多机训练
分布式数据并行,通过 NCCL 和别的节点通信。
/dev/shm And /tmp
/dev/shm 使用了 tmpfs,是存储在内存中的,而 /tmp 还是存储在硬盘上的。
内存拷贝
根据这里 [[#DMA 可以做内存到内存的拷贝吗?/ memcpy]] 的结论,内存拷贝(或者说造成较大开销的内存拷贝):
- 特指内存到内存的拷贝;
- 不包含使用了 DMA 的设备到内存之间的拷贝(因为这个通常来说更慢,也是必要没有办法省掉的)。
DMA 可以做内存到内存的拷贝吗?/ memcpy
标准 x86 架构只支持内存 - 设备的 DMA 拷贝,不支持内存 - 内存的 DMA 拷贝。
Intel 最新的技术 I/OAT 应该是支持内存到内存 DMA 的。Linux 内核则是自 2006 年开始使用,但此特性据称由于缺乏性能优势和造成数据损坏的可能性,在之后被禁用。
- Linux's API for DMA doesn't permit memory to memory transfers. It's only for communication between devices and memory. Look in Documentation/DMA-API.txt for more details.
- At hardware level, the x86 DMA controller doesn't allow memory to memory transfers. It's been discussed here: DMA transfer RAM-to-RAM
- Given that the memory bus is usually slower than the CPU, what benefit would it have to launch a kernel driven memory copy ?
linux - Using DMA Memory Transfer in User-Space - Stack Overflow
我觉得没有的主要原因在于:
- 现代架构都没有 DMAC 了,都是 device 来主动发送,Mem-to-Mem 没有设备参与其中,只能靠 CPU 来搬运。
- 内存总线比 CPU 要慢,因此直接 CPU 搬运就好了,反正即使支持 mem-to-mem DMA(通过引入一个类似 DMAC 之类的硬件) 了 CPU 也只能等待结束了才能继续工作。
c - asynchronous memcpy in linux? - Stack Overflow
runC / runV
runV 已经 obsoleted,就是 kata container。
Together with Intel, the runV team created Kata Containers project in OpenInfra Foundation, and the Kata Containers is a top level open infrastructure project in the foundation.
runC 就是普通。
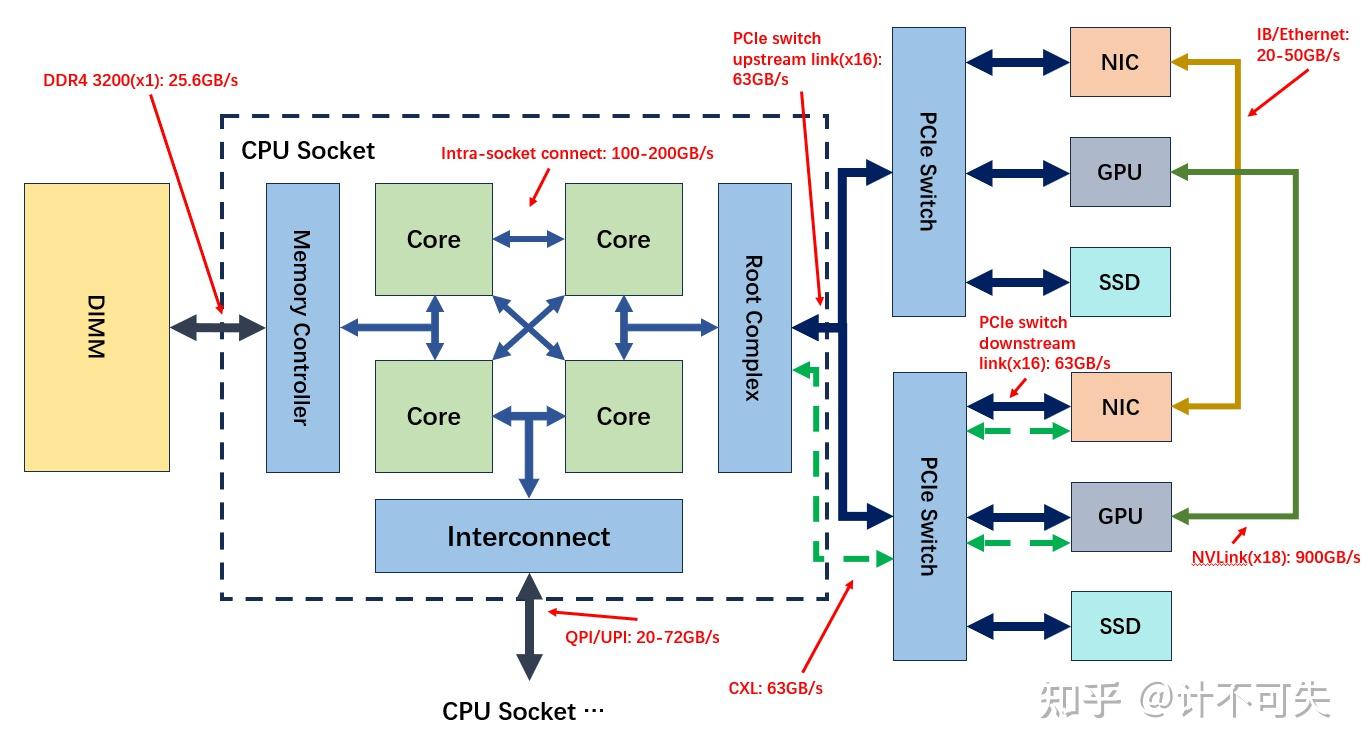
各通信协议带宽体感认识
| 协议 | 带宽 |
|---|---|
| QPI/UPI | |
| PCIe | |
| NVLink | |
| DDR5 |
PL0 / FlexPL / TL0
云盘规格--弹性块存储-火山引擎 这里有火山的不同的类型的存储的应用场景,可以关注学习一下。
ESSD (Enterprise SSD)
阿里云的存储服务?
Intel UPI (Ultra Path Interconnect) / QPI (QuickPath Interconnect) / 前端总线 FSB / xGMI
UPI 2017 年替代 QPI。AMD 对应的名字叫 xGMI。
这些都是芯片间互联技术,主要用在不同 NUMA Node 的不同 CPU 之间的通信。之所以叫做前端总线,是因为之前叫 FSB (Front-Side Bus),现在基本上已经淘汰了,它仅存在于 20 世纪 90 年代到 21 世纪初的老式计算机架构中。
- 可以用来基于此总线协议承接并实现更高层的协议比如 CPU 间的缓存一致性(Cache Coherence)、内存访问同步、中断传递等,确保多处理器协同工作。
- 物理层面:UPI 直接连接物理 CPU,而每个 CPU 对应一个 NUMA 节点。
与 CXL 的协同:新一代技术如 Compute Express Link (CXL) 可能逐步替代部分 UPI 功能,尤其在内存池化和异构计算场景。
注意区分 UPI 与核间通信,也要留意内存总线的位置(20-72GB/s vs. 100-200GB/s):
驱动可以运行在用户态吗?/ 用户态如何直接访问物理硬件?
设备驱动可以运行在内核态,也可以运行在用户态,各有利弊。
用户态驱动的优点:
- 可以和整个 C 库链接;
- 驱动问题不会导致整个系统挂起,内核态驱动的一些错误常常导致整个系统挂起。
缺点:
- 无法使用中断,中断在用户空间不可用(因为中断发生后会陷入到内核态切换到中断处理上下文的,那么怎么将中断信息从中断处理上下文路由到用户态呢?这是一个我们需要考虑的问题),最新的 UIO 接口已经解决了这个问题。
- 无法 DMA(原因很简单,DMA 需要提供的是物理地址,而在用户态并不知道物理地址)。
VFIO^ 也让用户态驱动开发变得更方便了。VFIO 本身就是一个设备直通框架,那么可以 bypass kernel 直通给虚拟机,为什么就不行 bypass kernel 直通给用户态呢?
DPDK and RDMA - Yizhou Shan's Home Page
CCL (Collective Communication Library)
为什么:集合通信的使用将分布式训练中多个硬件之间的数据通信变得简洁和高效。集合通信由通信库来实现。
和 MPI 的关系:除了在高性能计算领域被广泛使用的信息传递接口(Message Passing Interface,MPI)通信库之外,工业界针对深度学习的技术特点和硬件特性,对集合通信库(Collective Communication Library or CCL)进行了专门的优化,并提供了各自不同的通信库实现。
安全启动(Secure Boot)
安全启动的根本目的是为了防止消费者从软硬件层面对产品的部分关键系统进行读写、调试等高权限的操作。以限制消费者的能力,来达到保护产品的商业机密、知识产权等厂家权益的目的。当然,厂家是不会这样宣传 Secure Boot 的。他们的文案通常都是通过这项技术保护用户的隐私,防止恶意软件修改系统软硬件等等。
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。