Transformer 架构
这篇文章不错:Transformer模型详解(图解最完整版) - 知乎
论文《Attention is All You Need》提出。Transformer 由 Encoder 和 Decoder 两个部分组成。(注意,当前一些主流的 LLM 比如 Claude, ChatGPT, Gemini, DeepSeek-V3 等等都已经抛弃了 encoder,成为了 Decoder-Only 的架构了)。
输入:
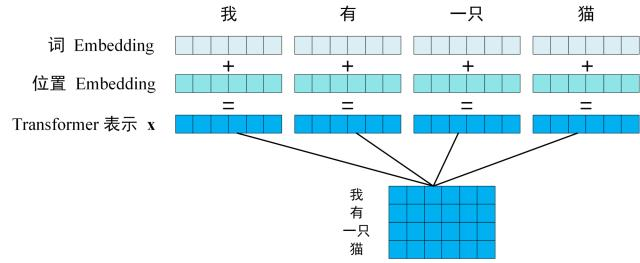
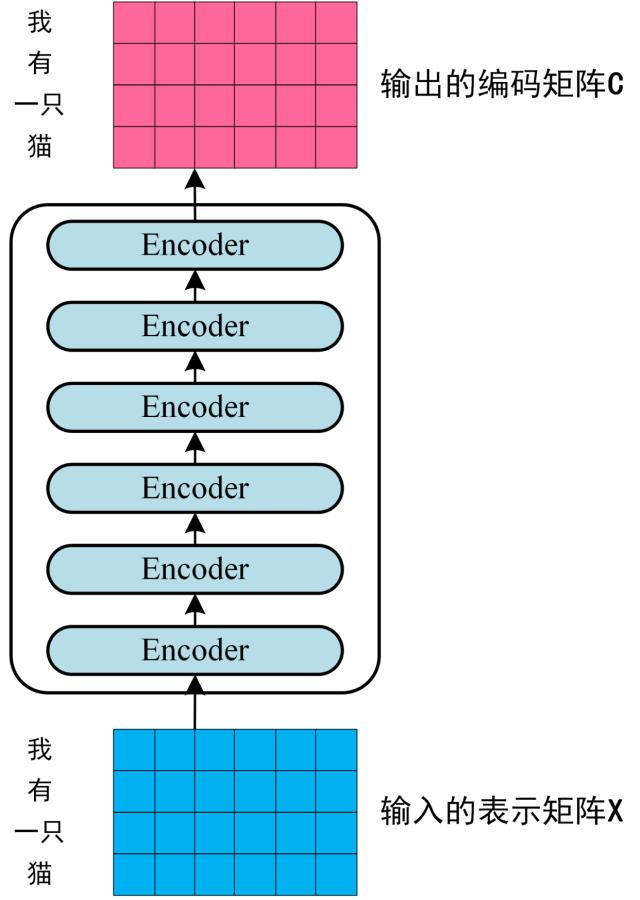
每一个 Encoder block 输出的矩阵维度与输入完全一致。
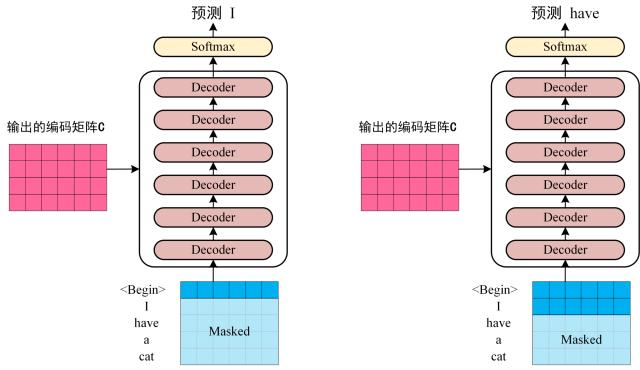
上图可以看出来,Decoder 有两个输入,编码矩阵和 Masked 矩阵(表示当前已经翻译好的内容)。然后进行多轮输入,每一轮根据编码矩阵和已经翻译好的内容翻译下一个单词。
表示矩阵与编码矩阵
Transformer 架构应用在机器翻译和大语言模型问答上的区别
Transformer 刚开始研发出来应该是做机器翻译的,
Encoder in Transformer
是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。
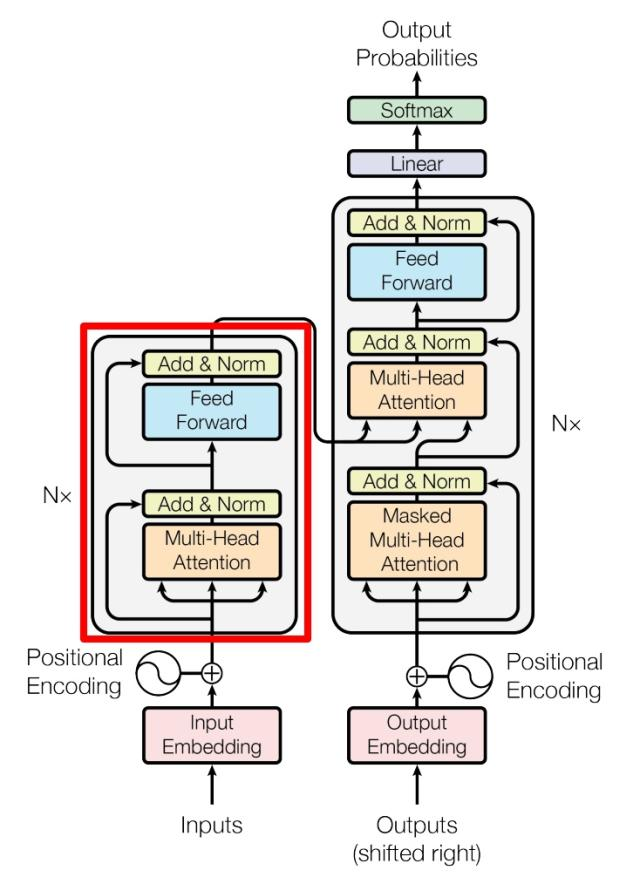
Decoder in Transformer
解码生成时都是自回归 auto-regressive 的方式。也就是,Decoder 的输出(已翻译的内容)会变为下一次的输入。刚开始都 mask,随着翻译的进行,逐渐 mask 的越来越少。
形式化来表达一下:也就是,解码的时候,先根据当前输入 $input_{i-1}$,生成下一个 $token_i$,然后把新生成的 $token_i$ 拼接在 $input_{i−1}$ 后面,获得新的输入 $input_i$,再用 $input_i$ 生成 $token_{i+1}$,依此迭代,直到生成结束。
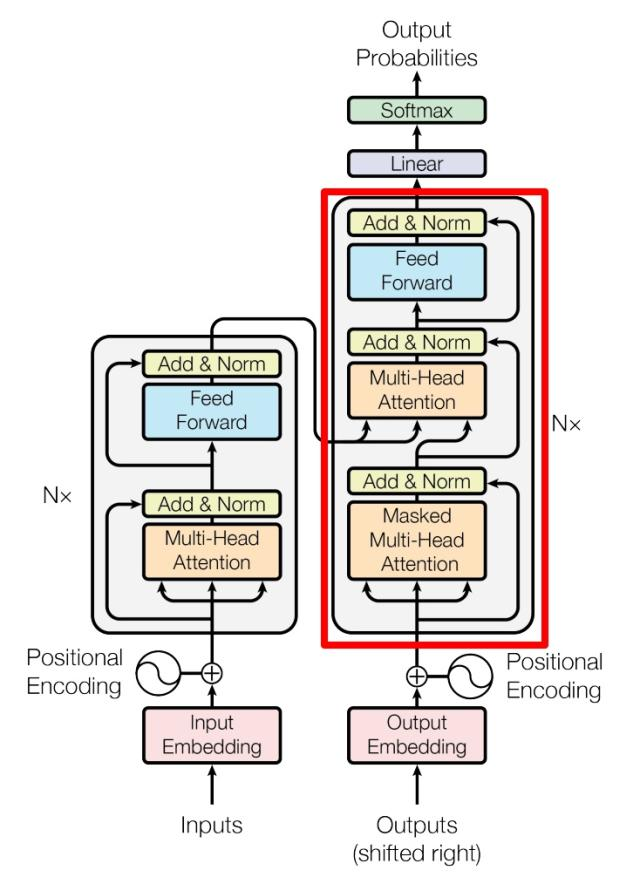
与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的 K, V 矩阵使用 Encoder 的编码信息矩阵 C 进行计算,而 Q 使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
第一个 Multi-Head Attention 层采用了 Masked 操作:
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 $i$ 个单词,才可以翻译第 $i+1$ 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 " 我有一只猫 " 翻译成 "I have a cat" 为例,了解一下 Masked 操作。
第二个 Multi-Head Attention 层的 K, V 矩阵使用 Encoder 的编码信息矩阵 C 进行计算,而 Q 使用上一个 Decoder block 的输出计算:
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 $K, V$ 矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 $C$ 计算的。
根据 Encoder 的输出 $C$ 计算得到 $K, V$,根据上一个 Decoder block 的输出 $Z$ 计算 $Q$ (如果是第一个 Decoder block 则使用输入矩阵 $X$ 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
Add & Norm
由 Add 和 Norm 两部分组成,其计算公式如下:
\[\text { LayerNorm }(X+\text { MultiHeadAttention }(X))\]或者:
\[\text { LayerNorm }(X+\operatorname{FeedForward}(X))\]其中 $X$ 表示 Multi-Head Attention 或者 Feed Forward 的输入,$MultiHeadAttention(X)$ 和 $FeedForward(X)$ 表示输出 (输出与输入 $X$ 维度是一样的,所以可以相加)。
Add 指 $X+MultiHeadAttention(X)$,是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到。
Norm 指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
Feed Forward in Transformer
比较简单,是一个两层的全连接层,第一层的激活函数为 $RELU$,第二层不使用激活函数。
$X$ 是输入,Feed Forward 最终得到的输出矩阵的维度与 $X$ 一致。
各种 Attention 机制
Attention 模块的核心思想:以前每一个 token 的编码向量仅仅代表了这个 token 的抽象信息,比如说 tower 这个 token,可以是任何塔,可以是九层妖塔,也可以是埃菲尔铁塔,而 Attention 机制就是要根据周围的信息更新每一个 token 的编码向量,让这个编码向量表示一个加了更多形容词的更加具象化的实体,比如说埃菲尔铁塔。这是因为在 token 表示空间中,一个向量可以表示一个很具体的事物,也可以表示是一个抽象的概念。
一个大模型一般有很多层的 attention,每一个 attention 有很多个头。比如说,GPT-3 使用了 96 层 attention,同时每一个 attention 使用了 96 个 head。每一层 attention 之间进行堆叠的原因是每一层的输入的 token 的语义更加细致,因此更深层的 attention 能够从这些语义中提取出更加细致的内容。
Self-Attention, MHA, MQA, GQA, MLA。
MQA、GQA、MLA,都是围绕“如何减少 KV Cache 同时尽可能地保证效果”这个主题发展而来的产物。
| [缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间 | Scientific Spaces](https://spaces.ac.cn/archives/10091) |
Self-Attention
需要用到三个矩阵:$Q$(查询), $K$(键值), $V$(值)。记住 $K$ 和 $V$,KV Cache 指的就是这两者。
Self-Attention 接收的输入是:
- (单词的表示向量组成的矩阵 $X$(注意是表示不是编码),M 是 token 维度,N 是向量空间维度) 或者
- 上一个 Encoder block 的输出。
而 $Q$, $K$, $V$ 正是通过 Self-Attention 的输入进行线性变换得到的。Self-Attention 的输入用矩阵 $X$ 进行表示,则可以使用线性变阵矩阵 $W_Q$, $W_K$, $W_V$ 计算得到 $Q=X \times W_Q$, $K = X \times W_K$, $V = X \times W_V$。引入线性变换是为了提升模型的拟合能力,矩阵都是可以训练的,起到一个缓冲的效果。注意 $X$, $Q$, $K$, $V$ 的每一行都表示一个单词。
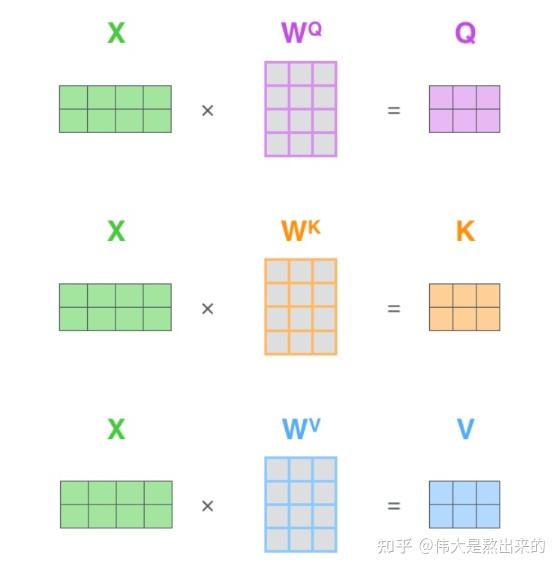
$Q$, $K$ 两个矩阵具有相同的格式,这是由其计算过程决定的(见后文)。$V$ 比较特殊,其列数为
得到矩阵 $Q$, $K$, $V$ 之后就可以计算出 Self-Attention 的输出了,计算的公式如下:
\[Attention(Q,K,V)=sofltmax(\frac{QK^T}{\sqrt{d_k}})V\]我们可以把这个公式分成三部分:
- $\frac{QK^T}{\sqrt{d_k}}$
- $softmax(…)$
- $V$
下面分开进行解释。第一部分:
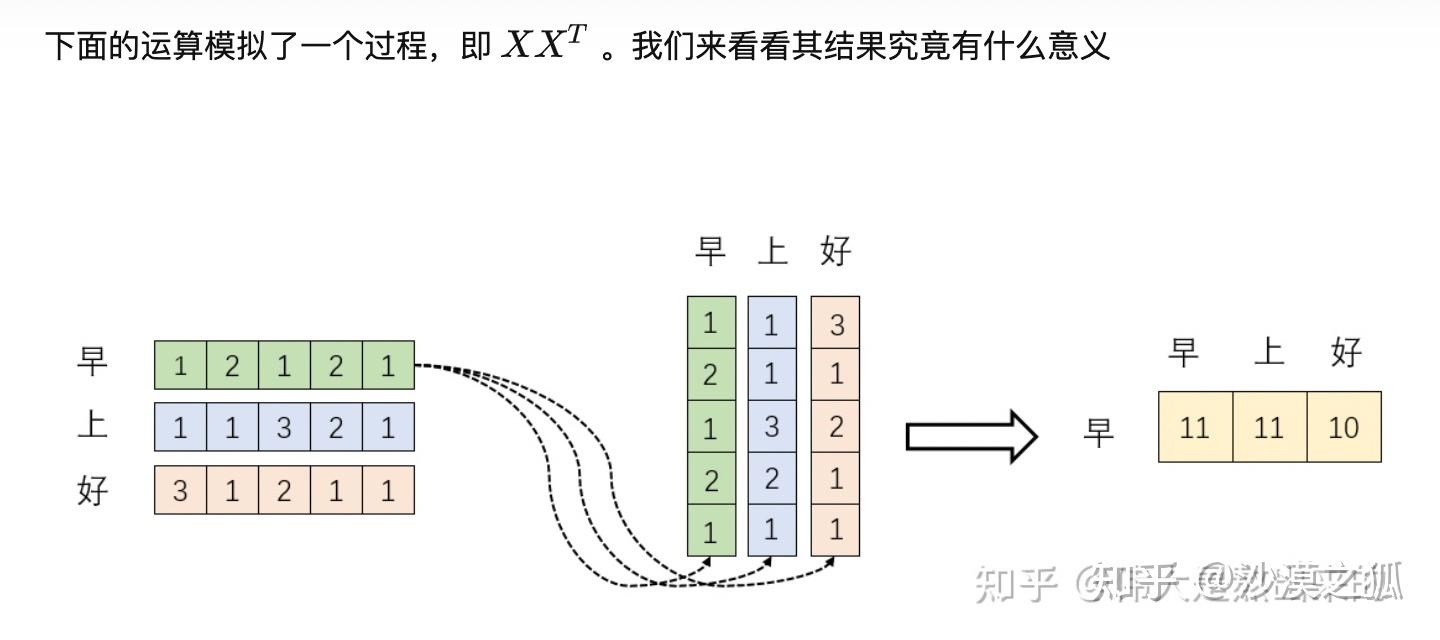
公式中计算矩阵 $Q$ 和 $K$ 每一行向量的内积,为了防止每一个内积的值过大,因此除以 $\sqrt{d_k}$,这个是矩阵的列数,表示每一个单词向量的维度(用了多少维来表示这个向量) 。$Q$ 乘以 $K^{T}$ 后,得到的矩阵行列数都为 $n$,$n$ 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。也就是矩阵的 $(i, j)$ 项其实表示第 $i$ 个单词和第 $j$ 个单词之间的 attention 强度。
我们知道向量相乘表示一个向量在另一个向量上的投影。投影越大,说明向量相关性越高。因为两个向量的内积是两个向量的相关度,那矩阵计算 $QK^{T}$ 就是每一个单词向量和其他单词向量的相关性。词 A 和 B 之间相关度高表示什么?是不是在一定程度上(不是完全)表示,在关注词 A 的时候,应当给予词 B 更多的关注?
第二部分:
softmax 的意义在于归一化,softmax 之后,得到的数之和就是 1 ,这样代表了权重。这就是 attention 的核心加权求和的由来。当我们关注 " 早 " 这个字的时候,我们应当分配 0.4 的注意力给它本身,剩下 0.4 关注 " 上 ",0.2 关注 " 好 ",这就是注意力机制。
第三部分:
得到 Softmax 矩阵之后可以和 $V$ 相乘,得到最终的输出 $Z$。最终单词 1 的输出 $Z_1$ 等于所有单词(包括自己) $i$ 的值 $V_i$ 根据 attention 系数的比例加在一起得到:
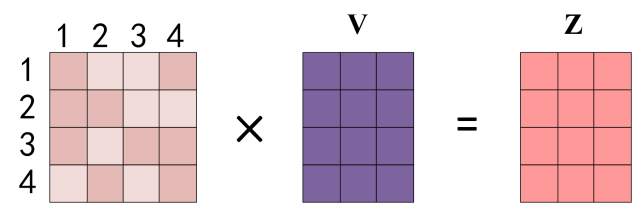
这一步的物理意义可以这么解释:
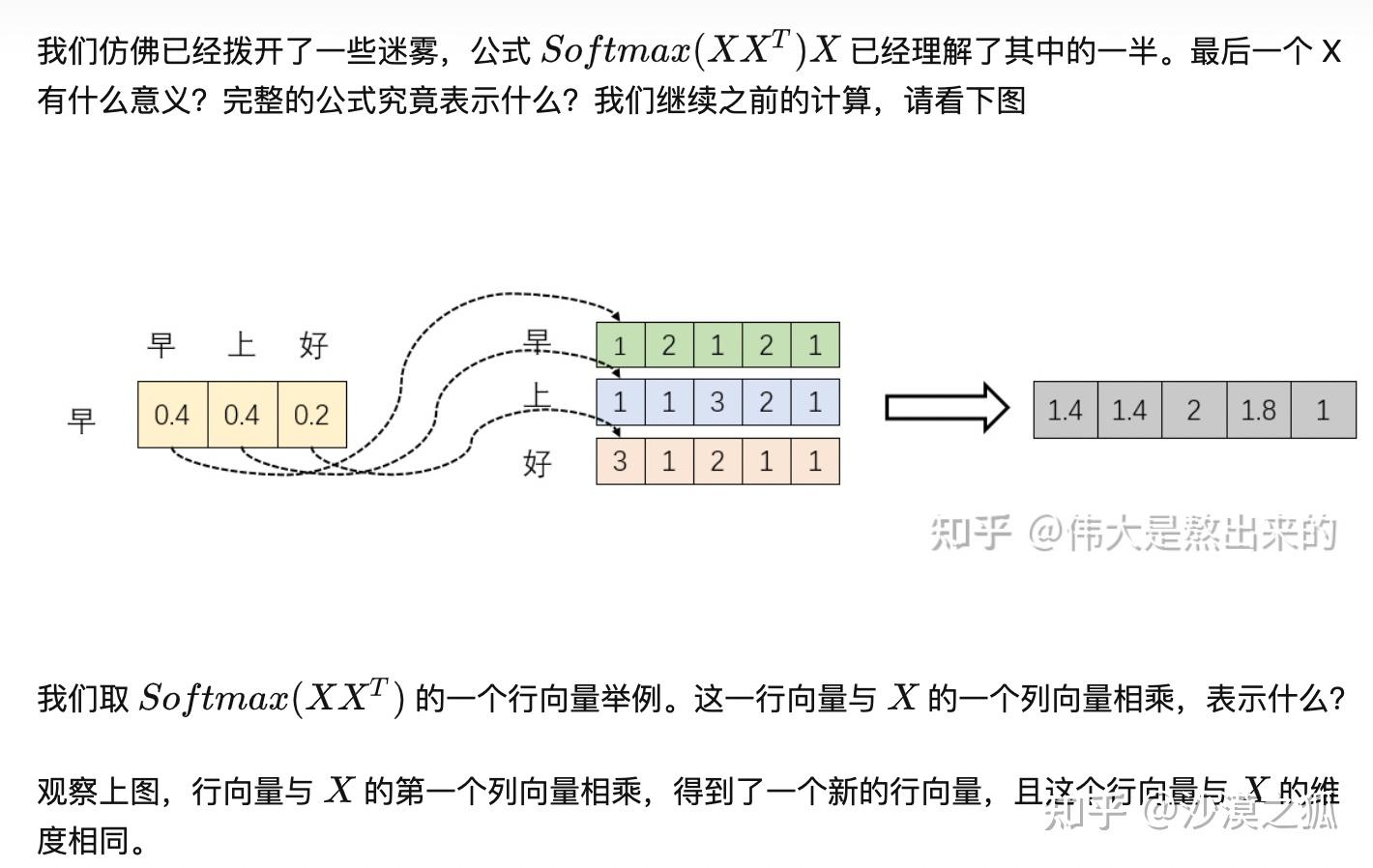
这个新的行向量就是 " 早 " 字词向量经过注意力机制加权求和之后的表示。其实也可以这样理解:之前各个向量是独立存在的(也就是 V 向量),经过 attention 之后(和注意力向量相乘之后),每个向量的表示融入了一些注意力的因素在里面做了变换。这一步还有一个意义就是用来保持 self-attention 算子的输入和输出格式保持一致。
最后,为什么这三个矩阵起 $Q$(查询 Query), $K$(键 Key), $V$(值 Value) 这些名称呢?
$Q$ 表示的就是与我这个单词相匹配的单词的属性,$K$ 就表示我这个单词的本身的属性,$V$ 表示的是我这个单词的包含的信息本身。
举个例子来说,假如你有一个问题 $Q$,去数据库里面搜,数据库存了很多文章,每个文章的标题是 $K$,内容是 $V$,然后搜索的过程就是用你的问题 $Q$ 去和数据库内所有的标题 $K$ 进行一个相关度的计算,然后将每个文章的内容 $V$ 根据其标题 $K$ 与查询 $Q$ 的相关度和做个加权和,得到了最终的结果,这个结果融合了相关性强的文章 $V$ 更多信息,而融合了相关性弱的文章 $V$ 较少的信息。这就是注意力机制,注意力度不同,重点关注(权值大)与你想要的东西相关性强的部分(文章内容 $V$),稍微关注(权值小)相关性弱的部分(文章内容 $V$)。所以你能看到,$QK^T$ 就表示了单词之间的相关性。因为相当于拿 $Q$ 里面的每一个 token 所对应的行向量作为一个 query 来查询 K 里面的相关性,这样就得到了所有 query 和所有其他 token 的的相关性。然后乘以 $V$ 就可以根据 $Q$ 和 $K$ 的相关性取出所有的值。
深度学习Attention中的Q,K,V为什么不叫A,B,C或者X,Y,Z? - 知乎
整个 self-attention 的计算过程可以汇总为下面这张非常直观的图:
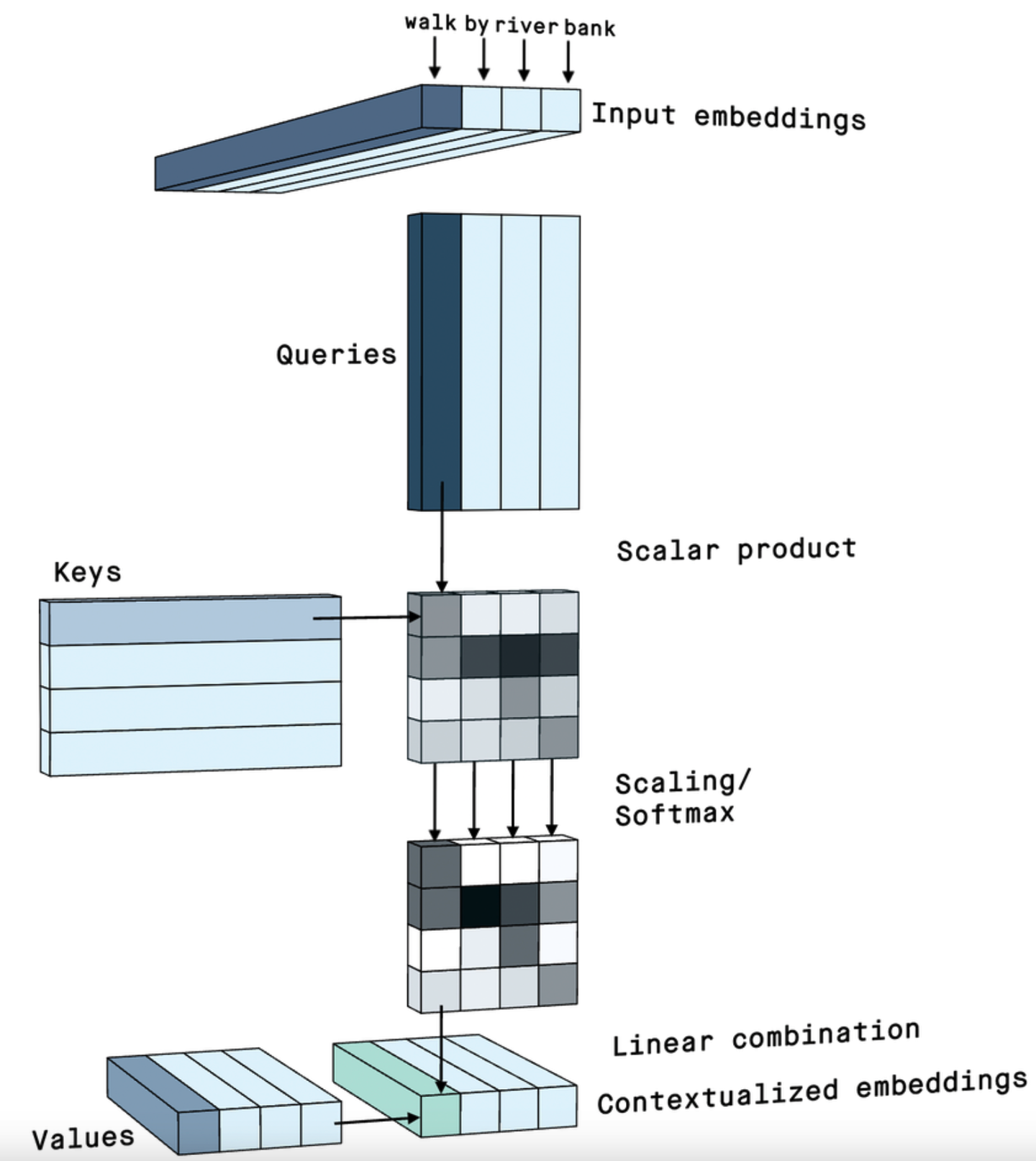
Self-Attention 输入输出矩阵大小一致吗?
简单来说:通常是相同的,但这并不是数学上的必然要求,而是工程上的标准实践。输出矩阵的列数由 $V$ 矩阵的列数决定,并且通常这个列数与输入矩阵的列数保持一致。
MHA (Multi-Head Attention)
对于 self-attention,由于 $Q$, $K$, $V$ 都来自输入 $X$,在计算 $QK^T$ 时,对于每一个 token,其自身的权重过大,也就是 $QK^T$ 对角线上的激活值会明显比较大。这样的情况其实不是很好,因为这会削弱模型关注其他高价值位置的能力,也就限制模型的理解和表达能力。MHA 对这个问题会有一些缓解作用。
MHA 在 2017 年就随着《Attention Is All You Need》一起提出,都是在同一篇论文里的。主要干的就是一个事:把原来一个 attention 计算,拆成多个小份的 attention,并行计算,分别得出结果,最后再合回原来的维度。其实就是在原来的 attention 下,$Q$, $K$, $V$ 的维度都是比较长(行数和输入矩阵 $X$ 是一样的,但是列数不一定,列数取决于 $W_Q,W_K,W_V$,因为要 $XW_Q=Q$),然后做一次 attention,而 MHA 相当于把每一个 $Q$, $K$, $V$ 都拆成了列数比较少的多个矩阵,然后做多次 attention,最后再拼起来。
因为参数矩阵 $W_Q,W_K,W_V$ 的列数其实没有什么物理含义,单纯列数越多我们能拿到的信息就越多,所以直观来讲,每一个 head 其实相当于关注了语义空间的不同部分。 比如说 $W_Q$ 的 0-9 列关注一个语义“发生了什么”,$W_Q$ 的 10-19 列关注一个语义“为什么发生这些” 等等。MHA 是在算出来 $Q,K,V$ 矩阵之后才开始对这些矩阵进行拆分的。
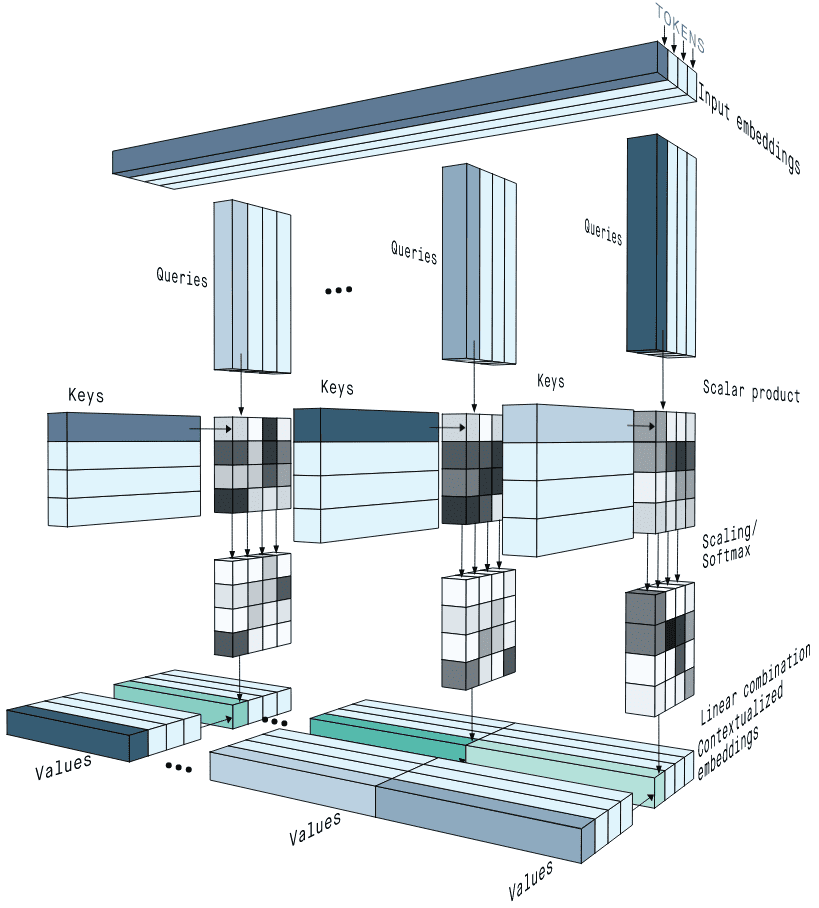
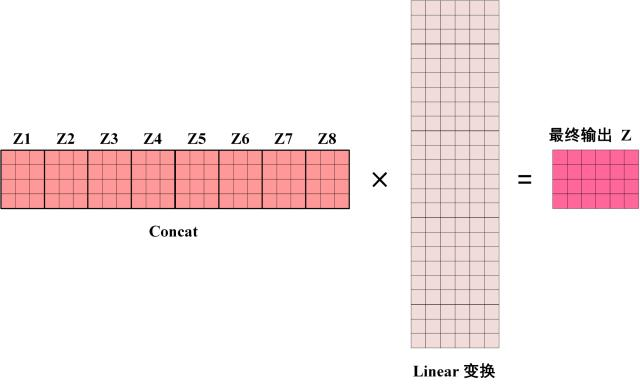
Multi-Head Attention 是由多个 Self-Attention 组合形成的。首先将输入 $X$ 分别传递到 $h$ 个不同的 Self-Attention 中,计算得到 $h$ 个输出矩阵 $Z$。比如当 $h=8$ 的时候,此时会得到 8 个输出矩阵 $Z$。
得到 8 个输出矩阵 $Z_1$ 到 $Z_8$ 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后乘以一个 Linear 层,得到 Multi-Head Attention 最终的输出 Z。
可以看到,之所以叫做 Multi-Head Attention,是因为是由多个 self-attention 组成的。
理论上来说,可以看到 MHA 的输入和输出格式不一定是一样的,这取决于最后线性变换矩阵的列数。但是实际上 Multi-Head Attention 输出的矩阵 $Z$ 与其输入的矩阵 $X$ 的维度是一样的(原因可能和 [[#Self-Attention 输入输出矩阵大小一致吗?]] 类似)。
我们希望多个头能够在训练中学会注意到不同的内容。例如在翻译任务里,一些 attention head 可以关注语法特征,另一些 attention head 可以关注单词特性。这样模型就可以从不同角度来分析和理解输入信息,获得更好的效果了。
头的数量不是越多越好(毕竟头的数量多了,各个子空间小了,子空间能表达的内容就少了)。
参考文献:
MLA 算子(Multi-query Latent Attention)
MLA(Multi-query Latent Attention) 是国内创业公司 deepseek 在 24 年 5 月份发布的 DeepSeek-V2 大模型中用到的 KV Cache 压缩技术,正是在该技术的加持下 DeepSeek-V2 可以大幅压缩 KV Cache 的大小,进而大幅提升吞吐量。
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces
FlashMLA
PagedAttention
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。