NVIDIA GPU
HGX
一个典型配置就是 8 卡和 4 个 NVSwitch。
HGX 平台上的 GPU 应该只有 NVLink 接口,没有 PCIe 接口,也就是说只能通过 NVLink 连接。
NVIDIA 自己造的超级计算平台。HGX 是一个计算模组,没有 CPU,没有操作系统。
和 JBOG 的关系感觉就是:JBOG 是对于 HGX 上的又一层封装,比如浪潮出过 16 卡的 JBOG(里面包含了两个 HGX)。
HGX 还是包含 BF DPU 的。
Rank in HPC
Rank 与 GPU 之间没有必然的对应关系,一个 rank 可以包含多个 GPU;一个 GPU 也可以为多个 rank 服务(多进程共享 GPU)。
PTX (Parallel Thread Execution) / SASS (Streaming Assembly) / NVRTC
https://k48xz7gzkw.feishu.cn/docx/GBa6dc0SFoRhDyxNYA7cNt7knNe#share-OZ1mdKvNEo0Gk1xXHnbcJnoMnSh
cuda - Is NVIDIA's JIT compilation cache used when you don't use NVCC? - Stack Overflow
PTX 是什么:CUDA 平台的汇编语言,需要在虚拟机(这个虚拟机 JIT 是包含在驱动中的)上执行,虚拟机再使用真正的操作硬件的 CPU 指令来运行。
- PTX 是一种中间语言,可以在不同的 GPU 上运行,
- 而 SASS 是一种特定的汇编语言,只能在特定的 GPU 上运行。
PTX 代码示例:
.visible .entry test(int&)(
.param .u64 test(int&)_param_0
)
{
ld.param.u64 %rd1, [test(int&)_param_0];
cvta.to.global.u64 %rd2, %rd1;
mov.u32 %r1, %ctaid.x;
st.global.u32 [%rd2], %r1;
ret;
}
SASS 代码示例:
test(int&):
MOV R1, c[0x0][0x20]
MOV R2, c[0x0][0x140]
S2R R0, SR_CTAID.X
GPU Box / JBOG (Just a Bunch of GPUs)
一种新型服务器架构。
JBOG 通过将多个 GPU 模块集中在一个专用机箱中运行,并通过高速互联技术与主机服务器连接,提供了一个灵活且高效的解决方案。这个专用机箱 JBOG,一般叫做机尾;而控制 JBOG 的真正服务器,也就是传统的带有 CPU 和内存的控制节点,叫做机头(Head Node)。
JBOG 的命名方式和设计理念,类似于前几年存储服务节点 JBOD(Just a Bunch of Disks)和 JBOF(Just a Bunch of Flash)。JBOD 是最简单的存储方案,就是将多个硬盘简单地组合在一起,形成一个存储池。随着闪存技术的发展,JBOF 应运而生,它采用同样的理念,但使用闪存替代了传统硬盘,提供更快的存储性能。
和 HGX^ 的区别,
AI算力底座技术:GPU/NPU box是什么?JBOG是什么?什么又是HIB、OAM、OAI、UBB? - 知乎
NVIDIA GPU 加速库
下图很直观地展示了各个加速库(cuDNN, CUTLASS, TENSORRT, cuBLAS 等等)的位置,位于 Pytorch 之下,CUDA 之上。

- cudnn、cuBLAS 这样的基础算子原语库在常见的卷积层上性能表现很好,通常都能够满足用户的需求,但是在面对用户高度定制化的算法时,基础算子库往往并不能充分发挥硬件的性能。这是由于算子优化的长尾问题引起的,基础算子库引入了许多卷积优化的通用策略,但是这些优化的策略并不能覆盖所有的情况,实际算法中的卷积层有可能并不能从通用的优化策略中获得收益,从而无法充分发挥硬件的性能。基础算子库的另一个问题是用户无法对这些基础算子进行定制化开发,当算法开发人员想为卷积算子添加一种新的激活函数,或者想添加一种特殊的卷积算子 (比如:LocalConv) 时,就会变得束手无策。
- cutlass 是
NVIDIA推出的一款线性代数模板库,它定义了一系列高度优化的算子组件,开发人员可以通过组合这些组件,开发出性能和 cudnn、cublas 相当的线性代数算子。但是 cutlass 仅支持矩阵乘法运算,不支持卷积算子,从而难以直接应用到计算机视觉领域的推理部署中。 - TensorRT 是一款非常强大的深度学习推理部署框架,在 CUDA 平台上性能表现非常优秀,而且目前已经比较成熟,用户使用起来比较方便。然而 TensorRT 也存在着一些问题,对于开发人员来说,TensorRT 是一个黑盒,用户没有办法细粒度控制 TensorRT 内部的实现细节。例如:在部署量化网络时,开发人员无法控制 TensorRT 底层的量化细节,有可能会出现部署和训练的精度对不齐的问题。再比如:TensorRT 在推理部署时,用户无法精细的控制算子的显存使用情况,有时 TensorRT 在运行网络时耗费了大量的显存,而用户却没有特别好的办法对此进行优化。
(48 封私信 / 82 条消息) cudnn、cublas、cutlass、TensorRT - 知乎
cuDNN
GPU 加速库。提供了深度学习算法中常见算子的高效实现。
它能将模型训练的计算优化之后,再通过 CUDA 调用 GPU 进行运算,也就是位于 CUDA 的上层,算子也是位于 CUDA 上层(所以叫做 CUDA 算子开发)。
主要是为了加速训练过程。
Pytorch(GPU)配环境原理:cuda+cudnn+pytorch配环境的每一步到底干了些什么?_pytorch cudnn-CSDN博客
CUTLASS / cuBLAS / BLAS
CUTLASS 是开源的,cuBLAS 是闭源的。
是一个 CUDA C++ 模板抽象的集合,这里可以理解成一个抽象模板库。目的是为实现高性能的矩阵乘法和相关计算。说白了就是简化编写 CUDA 代码的,一些东西都给封装好了。
这个是工作在 CUDA 上层,的一般来说调用顺序是这样的:
torch.nn.functional.linear
// pytorch
libtorch_cpu.so
libtorch_cuda.so
// cuBLAS
libcublas.so
// CUDA
libcuda.so
CUTLASS 的设计初衷是将 GEMM 中一些“可变的部分”分解成若干 C++ 抽象模板实现的基础组件,这种设计可以使开发者轻松的定制到他们自己的 CUDA kernel 中,所以主要是为了面向开发者的。所以可以看到 CUTLASS 的位置:就是比 Triton 更底层,更能定制算子,但是相比于直接 CUDA 手撕算子来说灵活性又差一些。 所以实际来说,CUTLASS 是和 Triton 坐一桌的。
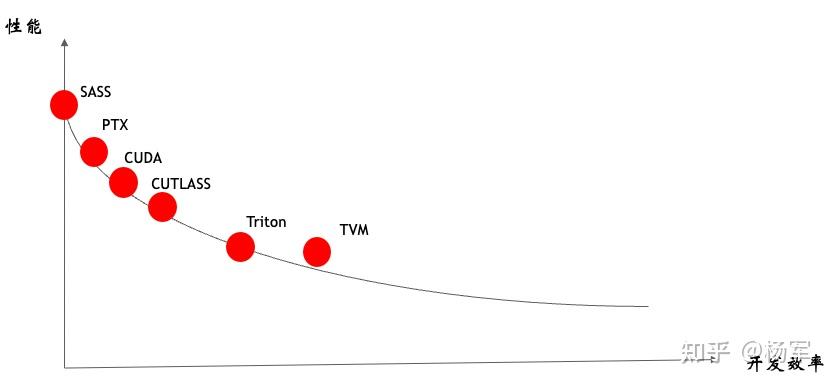
实际上 BLAS (Basic Linear Algebra Subprograms) 是很早之前就有的一个通用基础库。
GPU 知识体系学习文档
Modal 是一个大模型推理托管平台,他们的 developer 们深入研究了 GPU 相关的各种知识并放到了这个在线文档里面,比较杂,可以一看:GPU Glossary
Nvidia Confidential Computing 学习文档:[[2025-04-17-NVIDIA-GPU-CC#Resources for NVIDIA Confidential Computing]]
nvidia-persistenced / NVIDIA Persistence Mode
是 NVIDIA 驱动带的一个持久化守护进程,它的主要作用是:在没有应用程序使用 GPU 的时候,保持 GPU 驱动和设备处于初始化状态,而不是自动卸载或重置 GPU。
正常情况下,Linux 上的 NVIDIA 驱动是按需加载的:
- 当第一个进程访问 GPU 时,驱动会初始化 GPU(这需要几百毫秒甚至几秒钟);
- 当最后一个进程退出后,驱动会“释放” GPU,把 GPU 电源降级、重置硬件状态。
这样做节能,但有个问题:
如果你的系统上频繁有进程启动或结束使用 GPU(比如监控脚本、容器任务、短时 CUDA 作业),每次都要重新初始化 GPU,既慢又可能引发一些“GPU not ready”类错误。
nvidia-persistenced 的作用就是:
- 在后台维持一个轻量的守护进程;
- 打开 GPU 并保持它处于初始化状态;
- 这样即使没有用户进程使用 GPU,驱动也不会卸载;
- 新的 GPU 应用可以瞬时启动,不会再花时间重新初始化。
nvidia-smi
查看一个 GPU 特定的信息:
nvidia-smi -q -i 0
给 GPU 锁频:
nvidia-smi -lgc 2490,2490
nvcc / nvrtc
GPU 机间架构
查看 GPU 机内机间拓扑信息 / nvidia-smi topo -m
即使我们有 RDMA 网卡,如果没有启用 GDR 的话,那么输出也不会有 RDMA 网卡,而是仅仅有传统 TCP 网卡?是和 GDR 有关系吗?
nvidia-smi topo -m
一个典型的输出结果:
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 NIC0 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV18 NV18 NV18 NV18 NV18 NV18 NV18 SYS 0-87 0 N/A
GPU1 NV18 X NV18 NV18 NV18 NV18 NV18 NV18 SYS 0-87 0 N/A
GPU2 NV18 NV18 X NV18 NV18 NV18 NV18 NV18 SYS 0-87 0 N/A
GPU3 NV18 NV18 NV18 X NV18 NV18 NV18 NV18 SYS 0-87 0 N/A
GPU4 NV18 NV18 NV18 NV18 X NV18 NV18 NV18 SYS 88-175 1 N/A
GPU5 NV18 NV18 NV18 NV18 NV18 X NV18 NV18 SYS 88-175 1 N/A
GPU6 NV18 NV18 NV18 NV18 NV18 NV18 X NV18 SYS 88-175 1 N/A
GPU7 NV18 NV18 NV18 NV18 NV18 NV18 NV18 X SYS 88-175 1 N/A
NIC0 SYS SYS SYS SYS SYS SYS SYS SYS X
-
NV#:表示使用 NVLink 传输,可以看到 GPU 之间都是使用 NVLink 直接传输的; -
SYS:跨 NUMA 节点通信,需要通过 CPU 间总线比如 UPI (也就是系统总线 SYS)来通信。所有的 GPU 和网卡通信都是需要通过 SYS 总线; -
NODE: 表示同一 NUMA 节点内的跨 PHB 通信,需要经过 PCIe 总线 + CPU 内 PCIe Host Bridge 之间的互连(片内互联),这是因为一个 CPU 可以有多个 PHB,典型场景:两个 PCIe 设备连接到同一个 CPU 的不同 PHB(如 CPU 的 PCIe x16 和 PCIe x8 插槽)。一个 CPU 上可以有多个 PHB。 -
PHB(PCIe Host Bridge): 表示通过单个 PCIe Host Bridge 的通信。设备直接连接到 CPU 内置的 PCIe 控制器,最佳 PCIe 直连情况,延迟约 100ns,带宽可达 PCIe x16 的满速。 -
PXB(PCIe Bridge):表示跨多个 PCIe 交换机的通信,经过 PCIe Switch 层但未到达 PHB。 -
PIX:表示单级 PCIe 交换的通信,最多经过一个 PCIe Switch。
NVLink > PIX > PXB > PHB > NODE > SYS。虽然 PHB 和 PXB 都有 Bridge 这个后缀,但是其实表示的是交换机。
更形象的解释:
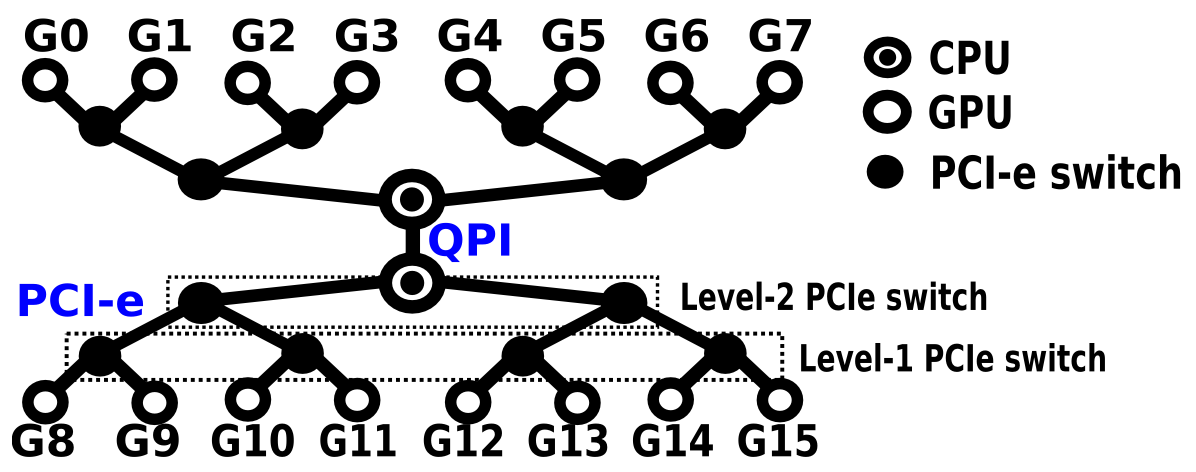
- GPU8 和 GPU9 通过一跳 PCIe switch 就能相连,这叫 PIX(Connection traversing at most a single PCIe bridge,需要 PLX 等特殊的硬件支持)
- GPU8 和 GPU10 通过两跳 PCIe switch 才能相连,这叫 PXB(Connection traversing multiple PCIe bridges but without traversing the PCIe Host Bridge,需要 PLX 等特殊的硬件支持)
- GPU8 和 GPU12 通过 CPU 根节点 PCIe host bridge 才能相连,这叫 PHB(PHB = Connection traversing PCIe as well as a PCIe Host Bridge,没有特殊硬件支持的话,同一个 CPU 上的设备都要通过 PCIe host bridge 才能相连)
- GPU8 和 GPU0 要跨过 CPU 节点之间的 QPI 才能相连,这叫 SYS(Connection traversing PCIe as well as the SMP interconnect between NUMA nodes, e.g., QPI/UPI)
NIXL
NIXL: NVIDIA Inference Xfer Library,随着 Dynamo 开源出来的。这个重点是在于:
- 优化 AI 推理框架的端到端通信。
- Providing an abstraction over various types of memory (e.g., CPU and GPU) and storage (e.g., file, block and object store)。
NVSHMEM
NVSHMEM 就是加了 IBGDA^ 的 NCCL。NVSHMEM 目前用的人不多,后面 IBGDA 进入 NCCL 之后,NVSHMEM 可能用的人会更少。
OpenSHMEM
NVSHMEM 是 NVIDIA 提供的一个并行编程接口 / 通信库,基于 OpenSHMEM 标准,专门用于在多个 NVIDIA GPU(包括跨多个节点 GPU 集群)之间实现高效且可扩展的通信和共享内存访问。
NCCL 专注于集合通信,通常用于深度学习训练中的梯度同步等。而 NVSHMEM 更底层一些,支持 put/get/atomic 等原语,也能用作集合通信工具的一部分或与 NCCL 混合使用。
GDA (GPUDirect Async) / IBGDA
指 GPU 可以直接向网卡下发指令(例如发起 RDMA 读写),不再依赖 CPU 去提交工作请求。
优点:把 CPU 从通信路径上彻底移除,GPU 可以在 Kernel 内部直接触发网络操作,进一步降低延迟,并能实现更细粒度的 GPU- 网络协同。
是 GDR 的进一步演进。GDR 还有一些控制面的东西需要在 CPU 上做,但是 GDA 可以完全没有 CPU 的参与。
GPUDirect / GPDR / GDR / GPUDirect RDMA
同一台机器的卡间可以使用 NVLink 通信,那么不同机器的机间可以使用 GDR 来通信。
GDR 技术是基于 PCIe 标准的。GDR 技术其实就是让 RDMA 网卡和 GPU 之间可以通过 PCIe 进行 DMA,不再需要 CPU 侧以及主机内存参与了。
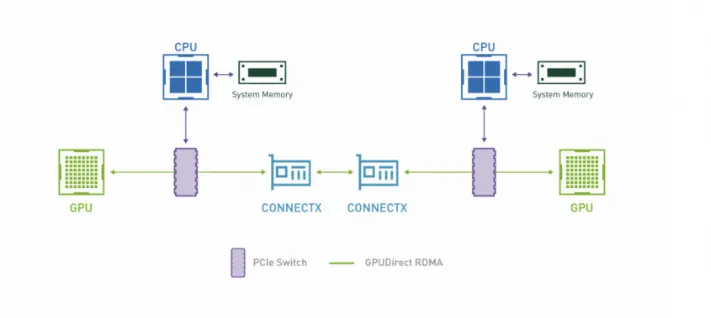
GDR 的合适使用场景是什么呢,比较推荐的场景就是 GPU 与第三方设备在同 PCIe switch 下的场景,这种情况下是存在性能增益的。
技术改变AI发展:RDMA能优化吗?GDR性能提升方案(GPU底层技术系列二)-阿里云开发者社区
如何使用和关闭 GDR?
# 开启 GDR
export NCCL_NET_GDR_LEVEL=SYS
# 关闭 GDR
export NCCL_NET_GDR_LEVEL=LOC
See: Environment Variables — NCCL 2.26.5 documentation
实现上,两种方式:
- 通过
nv_peer_mem内核模块,较老; - 通过 DMA-BUF^ 机制,较新,且性能也更好,原因是
nv_peer_mem比较 hack,不太标准。
https://zhuanlan.zhihu.com/p/1981507594146305320 这篇文章有评测。
nvidia_peermem.ko / nv_peer_mem.ko
这是一个内核模块。
The nvidia_peermem module is a drop-in replacement for nv_peer_mem
GDR 毕竟要涉及到 DMA 等等底层操作,而 NVIDIA 并不打算开源他们的驱动,所以搞了个可以安装的内核模块。
后面要逐渐用 DMA-BUF 也就是更加标准化的方式替代了,这也是 NVIDIA 和 Linux 社区共同努力的结果。
GDR 测试
先 nvcc --version 检查下 CUDA 有没有装。因为 GDR 本身是 CUDA 包的一部分。
GDR 测试依赖 NCCL 吗?
好像是不依赖的,相反,NCCL 本身是依赖 GDR 来进行运行的,因为 NCCL 是一个集合通信库,更偏上层一些。
# 一般来说就是下面这个测试模版
ib_write_bw --use_cuda <gpu index>
# 以下是 RDMA 测试
# 一打一测试(发送端和接收端唯一的区别在于一个指定了目的地址,一个没有)
# 使用 read 是因为使用了 1-side 测试而不是基于 send recv 的 2-side 测试
# 这个应该是从一边的显存 GDR copy 到另一边的显存当中。
# ib_read_bw 这个命令就是如果没有指定 ip 地址就是服务端,否则就是客户端。
# client 端
ib_read_bw -F -d mlx5_0 -x 3 -q 1 -s 1K --run_infinitely --report_gbits -p 10000 --use_cuda 0 26.111.50.130
# server 端
ib_read_bw -F -d mlx5_0 -x 3 -q 1 -s 1K --run_infinitely --report_gbits -p 10000 --use_cuda 0
# 二打二测试
# client 端(可见 client 端也使用了不同的 GPU(但是使用了同一网卡,那么就存在竞争的情况),通过同一 IP 的不同的端口连接服务端)
ib_read_bw -F -d mlx5_0 -x 3 -q 1 -s 64K --run_infinitely --report_gbits -p 10000 --use_cuda 0 192.168.0.24
ib_read_bw -F -d mlx5_0 -x 3 -q 1 -s 64K --run_infinitely --report_gbits -p 10001 --use_cuda 1 192.168.0.24
多机多卡训练问题排查
前备:
- 确保所有机器安装相同版本的 CUDA、NVIDIA 驱动和 NCCL。
- 确保主节点可以免密登录到所有节点(如 ssh hostname 无需密码)。
- 确保所有机器上的 nccl-tests 可执行文件路径一致,或手动同步编译后的二进制文件。
GPU 卡间架构
P2P (GPUDirect Peer-to-Peer)
主要用于单机 GPU 间的高速通信,它使得 GPU 可以通过 PCIe 直接访问目标 GPU 的显存。
两个 GPU 通过 PCIe 进行直接 DMA,没有主机 CPU/内存的参与。
在测试 nccl-tests 时,如何查看任何两张 GPU 间通信有没有使用 P2P,还是基于 D2H H2D 这种内存拷贝的方式?
NVLink / NVSwitch
NVLink 和 NVSwitch 单向链路之间:
- 带宽是差不多的,只不过是连接形态不一样;
- 延迟:NVSwitch 略有增加,毕竟要经过一个交换芯片。
体感上来说,NVLink 相比于 PCIe Gen5 x16 大概有 20x - 80x 的带宽性能差距。
本质上都是为了直接能够 P2P,绕过主机内存和 CPU,同时不需要占用 PCIe 带宽(相比于 P2P)。
不要被 NVLink 里的 Link 所迷惑觉得这是一种线材,其实和 PCIe 一样,都是集成在板子上的,因此不存在单独购买 NVLink 然后把两个 GPU 连起来的情况。
NVLink 一般都是 full mesh 结构,也就是所有 GPU 之间都有一条到另外一个 GPU 的连接。这就需要 GPU 上有很多的端口才行。
使用了 NVSwitch,每一个 GPU 需要连的线数仅仅和 Switch 数量相关,而 Switch 一般不会加很多,所以不会出现八卡 GPU 之间要互连但是每一个卡最多只有四个 NVLink 口的尴尬情况(仅仅比喻)。
NVSwitch 可以形成树形结构吗?
NVSwitch 无法形成级联的结构,无法形成树形的结构,每一个 NVSwitch 连接的不只是 GPU 卡。每个 NVSwitch 芯片还预留了相当数量的端口用于连接到其他 NVSwitch 芯片。这些 NVSwitch 间链路(ISL, Inter-Switch Links)是实现多芯片扩展和构建统一交换网络的关键。
NVLink/NVSwitch 的设计目标是为 GPU 提供超高速、超低延迟、完全对等的互连。多个 NVSwitch 之间的互连通常是高度互联的网状(mesh)或类似拓扑。
NVSwitch 之间需要连接吗?
需要连接,如果不需要连接,为什么还需要多个 NVSwitch 呢?直接一个 NVSwitch 接所有 GPU 就好了。多个 NVSwitch 芯片必须通过高速专用链路互相连接。这样的话,一个 GPU 到另一个 GPU 之间的通信就有多条链路可以走了,因此引申出下面问题:
两个 GPU 之间通信如何选路?
简而言之,有一个硬件实现的自适应路由算法。下面图里 NVSwitch 画的有点问题,其实 NVSwitch 之间也是有线缆连接的,只不过没有画出来。
这引申出来一个问题,两个 GPU 之间可以通过不同方式进行通信(可以走任何一个 NVSwitch,这里就涉及到负载均衡了)。

GPU 单卡架构
从 CUDA Kernels 如何被调度并执行讲起
同一时间,一个 NV GPU 上可以有多少个 kernel 同时执行? Hyper-Q 之前,kernel 之间是串行的,因此在某一个时刻,只能执行一个 kernel。但是在 Hyper-Q 之后(Kepler),可以同时执行。
同一时间,一个 NV GPU 的 SM 上可以有多少个 kernel 同时执行? 一个。但是一个 SM 上可以同时执行来自一个 kernel 的多个不同线程块(Block)的线程束(Warp),但这些线程块(Block)都属于同一个 Kernel。 不同 CUDA Kernel 不能同时在一个 SM 上混合执行。
一个 Block 是被分配给一个 SM 的,一个 SM 上可以分配多个 Warp。 这是资源分配的基本单位。一个 Block 内的线程会被组织成一个或多个 Warp。Warp 是 SM 上实际调度和执行的最小单位。一个 Block 必定是在一个 SM 上执行的(因为要共享该内核的资源),故目前来说一个 block 块最多 1024 个线程(不然的话如果超过了 SM 中的线程数量,那么就没有办法并行了)。并且在这个 SM 内,它的线程会被拆分成多个 Warp(硬件上的拆分)。这些 Warp 会在该 SM 的 Warp 调度器管理下,与其他 Block 的 Warp 交错执行(如果该 SM 上有多个 Block 的话)。
在同一时刻,一个 SM 中的不同 warp 可以同时执行来自不同 block 的任务。
一个 block 被划分出的 warp 不会固定在特定的物理资源上执行,而是由 SM 的硬件调度器根据 warp 的状态动态分配计算资源。
每个时钟周期,如果 Warp Scheduler 发现有 warp 空闲了,那么其就从队列中选择就绪的 warp(例如已完成上一指令、无内存阻塞)进行计算。 调度决策与 warp 所属的 block 无关——可能连续执行同一 block 的多个 warp,也可能交替执行不同 block 的 warp。
一图以蔽之:
https://k48xz7gzkw.feishu.cn/docx/GBa6dc0SFoRhDyxNYA7cNt7knNe?openbrd=1&doc_app_id=501&blockId=doxcn5pdj8kZMqP7epATmMrG5Lh&blockType=whiteboard&blockToken=AT1zwNf0OhUqR2bFbomc8EjjnBe#doxcn5pdj8kZMqP7epATmMrG5Lh
总结:
- 从软件角度出发:Kernel
->Block->Thread; - 从硬件角度出发:SM
->Warp->SP (CUDA Core)。 - 软件角度概念都比硬件概念高一级,比如:
- Kernel > SM:一个 Kernel 可以调度到多个 SM 上同时执行;
- Block > Warp:一个 Block 可以调度到多个 Warp 上同时执行;
- Thread = SP (CUDA Core):一个软件上的 Thread 其实是对应到了一个 SP 上。
CUDA Core / Tensor Core / SP, Streaming Processor
- CUDA Core 和 Streaming Processor SP,其实是同一个东西,只是同一个东西的不同叫法。
- CUDA Core 和 Tensor Core 都是集成在 SM 内部的专用计算组件,一个 SM 会包含很多 CUDA Cores 和 Tensor Cores。Tensor Cores 不能叫做 SP。
CUDA cores are general-purpose processors in NVIDIA GPUs. While, Tensor cores are built specifically to accelerate deep learning tasks like training and inference. CUDA cores can do “more” than the tensor cores.
GPU 工作队列(Work Queue)
NVIDIA driver
有广义(full driver)有狭义:
- 广义 NVIDIA driver:包含了 CUDA library 等等用户态的 driver;
- 狭义 NVIDIA driver:仅仅包含内核模块。
SIMT vs. SIMD
首先明白什么是 SIMD:SIMD 是一种数据级并行的技术。一条指令,多个计算单元同时执行计算。MMX, SSE, AVX (Vector), AMX (Matrix) 都是 SIMD 技术。
比如我们有 4 个数字要加上 4 个数字,那么我们可以用这种 SIMD 的指令来 1 次完成本来要做 4 次的运算。这种机制的问题就是过于死板,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外。
相比之下 SIMT 就更加灵活了,虽然两者都是将相同指令广播给多个执行单元,但是 SIMT 的某些线程可以选择不执行,也就是说同一时刻所有线程被分配给相同的指令,SIMD 规定所有人必须执行,而 SIMT 则规定有些人可以根据需要不执行,这样 SIMT 就保证了线程级别的并行,而 SIMD 更像是指令级别的并行。
SIMT 包括以下 SIMD 不具有的关键特性:
- 每个线程都有自己的指令地址计数器;
- 每个线程都有自己的寄存器状态;
- 每个线程可以有一个独立的执行路径;
而上面这三个特性在编程模型可用的方式就是给每个线程一个唯一的标号 (blckIdx, threadIdx),并且这三个特性保证了各线程之间的独立。
CUDA执行模型GPU架构 GPU架构是围绕一个流式多处理器(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件 - 掘金
线程束(Warps)/ Warp scheduler
所有的内容可以在这里找到:
- 1. Introduction — CUDA C++ Programming Guide
- 这里讨论更准确:GPU architecture and warp scheduling - CUDA / CUDA Programming and Performance - NVIDIA Developer Forums
这是 H100 的的架构图,可以看到一个 SM 可以包含多个 Warp(比如 64 个)。注意 wrap scheduler 和 wrap 并不是一一对应的关系(比如 4 个 warp scheduler 对应到 64 个 warp,每一个 warp 是否绑定到了一个 scheduler 上这个 NVIDIA 没有公开,所以需要讨论)。可以看到一个 warp 有 32 个线程(Warp 的大小固定是 32 个线程):

CUDA 采用单指令多线程 SIMT 架构管理执行线程,不同设备有不同的 warp 大小,但是到目前为止基本所有设备都是维持在 warp size == 32,也就是说每个 SM 上有多个 block,一个 block 有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻,SM 上虽然可以同时执行多个 warp,每一个 warp 内也就是 32 个线程可以同时同步执行,但是线程束中的每个线程执行同一条指令,但是使用的都是私有数据(比如 instruction address counter)和寄存器信息,因此可以有自己的 branch 选择执行与不执行。也就是以不同的数据资源执行相同的指令。线程同时在相同的程序地址启动。 从性能的角度来说,一个 warp 里 diverge 的 thread 越少,那么执行效率越高,所以我们软件编程应当尽量避免 diverge 的情况发生。
一般一个 SM 上最多调度 64 个 thread groups(一个 group 对应一个 warp)。
不同 block 的 thread 不能在同一个 warp 里面,也就是一个 warp 需要整着切 block 而不是混着切。
线程束是 SM 里的硬件概念。
Warp scheduler 调度是硬件行为,一个 SM 上 warp scheduler 会自动感知是否有 warp 是等待的状态,如果是然后切换到另外一个 warp。调度基本上 1ns 发生一次(CPU 上因为要 save/restore context 基本上要 1ms 一次),每次调度,warp 会被 switched out 换入换出。GPU 上的 warp schedule 不需要任何的 save/restore。这是因为每一个线程(指软件线程)都有自己的 register file(从 warp 处申请的,见上图里每一个 warp 里的共享的 register file)。
Warp 和 block,一个是硬件层面的线程集合,一个是逻辑层面的线程集合。 一旦 block 被调度在一个 SM 上,线程块中的线程会被进一步划分为 wrap,划分逻辑非常直白,block 里的所有 thread 按照线程号的连续顺序来划分。因此线程束(wraps)是比线程块(blocks)更小的单位。
了解 warp 可以帮助理解和优化特定 CUDA 设备上 CUDA 应用程序的性能。
SM详解与Warp Scheduler,合理块和线程的数量对GPU利用率非常重要 - 知乎
流式多处理器(SM, Streaming Multiprocessor)
Nvidia 特有的硬件概念,每个 GPU 通常有多个 SM,当一个 kernel 的 grid 被启动的时候,多个 block 会被同时分配给可用的 SM 上执行。
当一个 block 被分配给一个 SM 后,他就只能在这个 SM 上执行了,不可能重新分配到其他 SM 上了,多个 block 可以被分配到同一个 SM 上(一个 SM 上可以同时跑多个 blocks 吗,而不仅仅是顺序执行)。因此同一块中的线程能够以不同于不同块之间的线程的方式相互交互(因为 share 同一个 SM)。也就是说,block 和 SM 是多对一的关系。
在 SM 上同一个 block 内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
为什么 GPU 要划分 SM?
- 主要目的是提高 GPU 的并行计算能力和资源利用率。GPU 就可以通过将计算任务分解成多个小部分的工作分配给不同的 SM 并行执行,从而加快计算速度。
- 避免不同计算任务之间的资源竞争,提高 GPU 并行性能。
体感认识:Ampere A100 GPU 具有 108 个 SM,每个 SM 有 64 个核心,总共在整个 GPU 中有 6912 个核心。H100 GPU 有 132 个 SM。所以从这种角度来说,一个 SM 更像对应一个 CPU 里一个 core 的概念,比如 AMD CPU 有 256 个 core。
一个 SM 不可以同时被分配不同 CUDA kernel (grid) 的 block,这就是说,如果一块 GPU 需要同时执行多个 kernel,那么应该将它们分配给不同的 SM 来一起执行,而不是在 SM 里面分配不同的 block 来执行。这里面分两部分调度:
- 是由 GPU 硬件调度器来进行而不是软件驱动进行的。
一般不支持乱序执行。
下图区分硬件和软件上的概念:
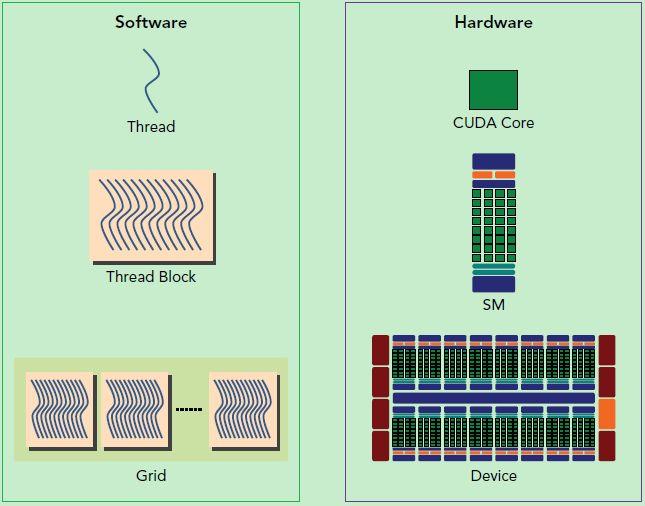
GPU 如何知道自己应该运行什么程序?
查看 GPU 设备进程占用
sudo apt-get install psmisc
sudo fuser -v /dev/nvidia*
显存 / GPU Memory
NVIDIA GPU 显存层级
分为片内和片外,因为 GPU 本身也是一个计算系统,片内相当于 CPU,片外相当于内存。
- 片内内存(On-Chip Memory):
| 名称 | 作用域 | 管理方 | 大小 | 延迟 | 作用与解释 |
|---|---|---|---|---|---|
| Register File 寄存器文件 | SM 中,线程私有 | CUDA 程序申请使用。 | 单 SM 几百 KB,每个线程几十字节。 | ~1-2 个时钟周期 | 线程本地计算使用。 |
| Shared Memory 共享内存 | SM 中,线程块 Block | 可软件配置硬件共享内存比例,程序可管理和申请。 | 单 SM 几百 KB | ~10-20 个时钟周期 | 同一线程块内的线程间高效协作与数据共享。 |
| L1 Cache | 整个 SM 内共享 | 可软件配置和共享内存比例。 | 与共享内存等同 | 与共享内存等同 | 物理上和共享内存是共享同一份,可以指定分配比例,就是缓存自动命中。 |
| L2 Cache | GPU 全局共享,可被所有 SM 访问 | 一些硬件特性可软件配置。 | 几十到上百 MB | ~ 40-60 或 200-500 个时钟周期 | 就是缓存自动命中。 |
- 片外内存(Off-Chip Memory):
| 名称 | 作用域 | 管理方 | 大小 | 延迟 |
|---|---|---|---|---|
| 全局内存(显存、VRAM) | 全局 | 软件 | 几十到上百 GB | 400 - 600 个时钟周期 |
补充 Register File, Shared Memory 和显存在程序中怎么用?一个示例:
#include <cuda_runtime.h>
#include <stdio.h>
// 核函数:展示寄存器、共享内存、全局内存的用法
// 功能:每个线程读入一个值,加 1 后存入共享内存,然后由线程 0 累加整个块的值并写回显存
__global__ void demo_memories(const float* d_in, float* d_out, int n) {
// 1. 寄存器 (Register File) —— 线程私有,速度最快
int tid = threadIdx.x; // 线程在块内的索引
int gid = blockIdx.x * blockDim.x + tid; // 全局索引
float reg_val; // 寄存器变量
// 从全局内存读取到寄存器(若未越界)
if (gid < n) {
reg_val = d_in[gid]; // 全局内存 -> 寄存器
} else {
reg_val = 0.0f;
}
// 在寄存器中做一次简单运算
reg_val = reg_val + 1.0f;
// 2. 共享内存 (Shared Memory) —— 块内所有线程共享,需同步
__shared__ float shm[256]; // 假设 blockDim.x <= 256
shm[tid] = reg_val; // 寄存器 -> 共享内存
__syncthreads(); // 确保所有线程写入完成
// 块内累加:只有线程 0 操作共享内存
if (tid == 0) {
float sum = 0.0f; // 寄存器变量
for (int i = 0; i < blockDim.x; i++) {
sum += shm[i]; // 从共享内存读取
}
// 3. 全局内存 (显存) —— 最后将结果写回
d_out[blockIdx.x] = sum; // 共享内存 -> 全局内存
}
}
int main() {
const int N = 1024; // 总数据量
const int blockSize = 256;
const int gridSize = N / blockSize; // 4 个 block
float *h_in, *h_out;
float *d_in, *d_out;
// 主机内存分配与初始化
h_in = (float*)malloc(N * sizeof(float));
h_out = (float*)malloc(gridSize * sizeof(float));
for (int i = 0; i < N; i++) h_in[i] = (float)i;
// 全局内存分配(显存)
cudaMalloc(&d_in, N * sizeof(float));
cudaMalloc(&d_out, gridSize * sizeof(float));
// 拷贝输入到显存
cudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);
// 启动核函数
demo_memories<<<gridSize, blockSize>>>(d_in, d_out, N);
cudaDeviceSynchronize();
// 拷贝结果回主机
cudaMemcpy(h_out, d_out, gridSize * sizeof(float), cudaMemcpyDeviceToHost);
// 验证:每个块的和应为 (块内索引偏移 + 1) 的累加
printf("Block sums: ");
for (int i = 0; i < gridSize; i++) {
printf("%.0f ", h_out[i]);
}
printf("\n");
// 释放资源
free(h_in); free(h_out);
cudaFree(d_in); cudaFree(d_out);
return 0;
}
模型大小和显存
如果只是进行推理的话,还是比较容易计算的。目前模型的参数绝大多数都是 float32 类型, 占用 4 个字节。所以一个粗略的计算方法就是,每 10 亿(1B)个参数,占用 4G 显存 (实际应该是 $10^9*4/1024/1024/1024=3.725G$,为了方便可以记为 4G)。
int8 量化模型更简单,1B 对应 1G 显存。
HBM2 / HBM2e / GDDR
因为 DDR^ 是面向内存的,而内存带宽在 GPU 领域里还是不太够。因此如果我们想要以更快的速度访问显存的话,就需要 GDDR 了。
DDR 在下降沿和上升沿都传输,所以叫做 Double Rate,而 GDDR (Graphic DDR) 通过定义了多个沿来传输,实现了四倍甚至更高的速度。
NVIDIA GPU 架构演进 / A10
截止到 2024 年的所有 Nvidia GPU 架构:NVIDIA GPU 核心与架构演进史 – 陈少文的网站
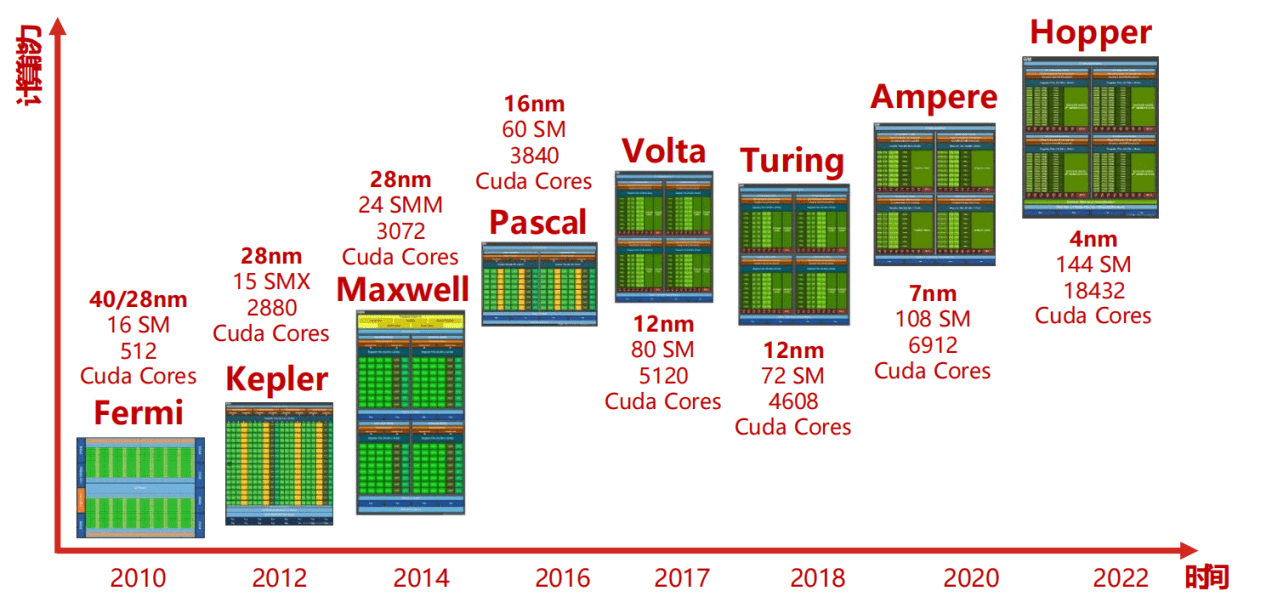
Ampere 和 Hopper 之间也是有一个新的架构叫做 Ada Lovelace。是一个全新的架构,应该不属于 Tesla 架构。
区分系列名,架构名和型号名:
- GeForce 等等都是系列名;
- Ampere, Hopper 都是架构名;
- A100, H100 都是型号名。
可以看到,后面出的 CPU 型号名和架构名都是有关联的,比如:
- Ampere 架构:型号名 A100
- Hopper 架构:型号名 H100
- Blackwell 架构:型号名 B100
FYI: 3070ti 显卡用的是 Ampere 架构。
A10: NVIDIA A10 datasheet
- 24GB 显存。
A100: NVIDIA A100 | Tensor Core GPU
- 80GB 显存。
B200 和 GB200 区别
B200 表示的单纯是 GPU,而 GB200 是芯片的“组合”,是通过一个板子将 2 颗 B200 加上一颗 Grace CPU(72 核心的 ARM 架构处理器)组合而成。
H200, H100, H20 区别
H20 是中国特供,H200, H100 GPU core 架构都是一样的,主要区别在于内存容量和带宽上有区别。
H100 PCIe vs. H100 NVL vs. H100 SXM
三种不同的接口,这里能够看到他们的区别:NVIDIA Announces H100 NVL - Max Memory Server Card for Large Language Models
NVIDIA 的 GPU 需要哪些固件
VBIOS
NVIDIA VBIOS 是 NVIDIA 显卡的 固件(Firmware),全称为 Video BIOS 或 显卡 BIOS。它是存储在显卡硬件芯片中的一段程序,负责显卡的底层初始化、硬件控制和与操作系统/驱动程序的通信。
AMD GPU 架构演进
RDNA:架构名字,比如 RDNA, RDNA 2, RDNA 3, RDNA 4。
架构系列:
- Vega 架构:发布于 2017 年,特点是采用高带宽缓存控制器(HBCC),以及下一代计算单元设计,支持高级图形与高性能计算任务。比如 Radeon RX Vega 64/56 显卡。
- RDNA 2/3/4 架构:2019 年推出的第一代 RDNA 架构是 GCN 架构的重大革新,旨在提供更高的能效比,并首次应用于 Radeon RX 5000 系列显卡上,如 RX 5700 XT 和 RX 5700。偏向游戏玩家。
- CDNA 架构:专注于数据中心和高性能计算市场,具备高度优化的计算性能,适用于机器学习、深度学习、科学计算等领域。
主要 GPU 产品线:
- 消费级桌面显卡: • Radeon RX 系列:例如 RX 5000 系列、RX 6000 系列等,为个人电脑玩家和内容创作者提供中高端图形处理能力。
- 移动版显卡: • Radeon RX 移动版:针对笔记本电脑市场,如 Radeon RX 5000M 系列和最新的 RX 6000M 系列,为游戏本和平板电脑提供强劲的图形性能。
- 专业显卡: • Radeon Pro WX 系列:面向专业工作站用户,如 WX 7100、WX 8200 以及基于 Vega 架构的 WX 9100 等型号,满足 CAD、渲染、建模等专业应用需求。
AMD GPU体系知识大全_vega架构和rdna架构-CSDN博客
GPU 图形渲染
着色器(Shader)
是一个软件程序,不是一个硬件单元。
顶点着色器(Vertex Shader)
像素着色器(Pixel Shader)
NVIDIA GPU 可观测性 & 稳定性
Range time and Projection time
Range time 就是打 NVTX 点的时间,也就是在 CPU 上经过执行的时间,这个很好理解。
Projected time 理解起来其实是有点难度的:
NVTX time ranges projected from the CPU to the GPU. Each NVTX range contains one or more GPU operations. A GPU operation is considered to be “contained” by the NVTX range if the CUDA API call used to launch the operation is within the NVTX range. Only ranges that start and end on the same thread are taken into account.
The projected range will have the start timestamp of the start of the first enclosed GPU operation and the end timestamp of the end of the last enclosed GPU operation. This report then summarizes all the range instances by name and style. Note that in cases when one NVTX range might enclose another, the time of the child(ren) range(s) is not subtracted from the parent range. This is because the projected times may not strictly overlap like the original NVTX range times do. As such, the total projected time of all ranges might exceed the total sampling duration.
Post-Collection Analysis Guide — nsight-systems
简单点来说:
如何计算?
在该 NVTX range 内(Range time)启动的 G 所有 GPU 操作(kernels、memcpy 等),找到所有这些操作在 GPU 时间轴上的:
- 最早开始时间($start$);
- 最晚结束时间($end$)。
projected time = $end - start$。所以一般来说,Projected time 的开始时间都是比 Range time 要晚的。结束时间就不一定了。
Projected time 不是 GPU 执行的时间,比如一个 Range 内有多个 GPU 操作,这些操作中间的 Bubble 也被算在了内,因此 projected time 变长可能也是 CPU 侧执行变长的结果:每一个 kernel 发的都晚了,如下图所示:
https://k48xz7gzkw.feishu.cn/docx/SzYAdhpA9oRJ2axWEmUcabwFnUh#share-XGmIdjOXSoGB4xxO3PacWNpqnZb
对于嵌套的 range。假设 MemoryTransfer 是第一个子,假设 KernelCalculation 是第二个子,那么自然而然的,第一个子的结束时间可能会晚于第二个子的开始时间,因此两者的 projection time 就有可能重合,此时父 Range 也就是 AlgorithmStep 的 projection time 就是
GPU时间轴 (μs): 0----------------------------------------------------------------------->500
MemoryTransfer (子): [-----------从50到150-----------]
KernelCalculation (子): [--------------从120到300-------------]
AlgorithmStep (父): [---------------------从50到300--------------------]
意义?
- 如果 Projected time < Range time,那么 GPU 端有可能瓶颈,有可能不是瓶颈,取决于 projected time 的开始时间;
- 如果 Projected time > Range time,那么 GPU 端一定是性能瓶颈。
https://k48xz7gzkw.feishu.cn/docx/SzYAdhpA9oRJ2axWEmUcabwFnUh#share-OJcodhuNgogmhfxUH5ncmLdEnZb
nvml / dgcm
这两个工具之所以放到一起,因为都是 NVIDIA 开发并提供的可观测性工具。两者最重要的区别是一个是单个 GPU 的 metrics,一个是多 GPU 多节点级别的 metrics。
- NVML: NVIDIA Management Library. C-based API.
- DGCM: Data Center GPU Manager. 也是要依赖 NVML 组件的:it builds on NVML but adds higher-level features for cluster-wide management.
nvidia-smi 或许是每一个接触 GPU 编程的人都知道的命令,它能够显示 GPU 的相关信息,经常用于查询 GPU 状态、使用情况等。
有些工具借助 nvidia-smi,对它的输出进行分析,从而获取 GPU 状态;更高级一些的工具,则会使用 nvidia-smi --query-gpu=index --format=csv 等类似的指令,分析结构化的 csv 输出。而本质上,nvidia-smi 的很多信息,其实都是来自于 NVIDIA management library(简称 nvml)。
其次是 dgcm:
What is the difference between NVIDIA DCGM and NVIDIA NVML? - Massed Compute
GPU XID
The Xid message is an error report from the NVIDIA driver that is printed to the kernel log or event log.
nvidia-bug-report.sh
Nsight
Nsight 的安装
Installation Guide — nsight-systems 2025.3 documentation
上面文档里的下面几行:
apt update
apt install -y --no-install-recommends gnupg
echo "deb http://developer.download.nvidia.com/devtools/repos/ubuntu$(source /etc/lsb-release; echo "$DISTRIB_RELEASE" | tr -d .)/$(dpkg --print-architecture) /" | tee /etc/apt/sources.list.d/nvidia-devtools.list
apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
apt update
apt install nsight-systems-cli
Nsight 的使用
# 结束进程时,会显示:
# Generating '/tmp/nsys-report-01cd.qdstrm'
# [1/1] [========================100%] report1.nsys-rep
# Generated:
# /root/p/virt_pgo/honor/report1.nsys-rep
# 这些表示 profile 完成了。
nsys profile <进程启动命令>
拿到 .nsys-rep 文件后,我们在我们的客户端(工作机)打开 Nsight Sytem,选择 file -> load 这个文件来查看即可,非常简单。
Nsight 的解读
Nsight System 输出解读 - 飞书云文档
NVTX (NVIDIA Tools Extension SDK)
一个调试工具,具体功能这里说的比较清楚:探索NVIDIA NVTX:强大的性能分析工具库-CSDN博客
Pytorch Profiling
Wall duration / Self duration
Self duration 就类似 perf report 抓出来的 self overhead。Wall duration 就类似 perf report 抓出来的 children overhead。
- Self duration / self overhead:仅仅统计这个函数自己代码的占比;
- Wall duration / children overhead:统计这个函数从头到尾占用的时间,包含了这个函数子函数的执行时间。
NVIDIA GPU 配置
持久化模式 nvidia -pm 1
NVIDIA GPU 性能
GPU P-State
在 NVIDIA GPU 上,“P-State”(Performance State)用来表示显卡当前的性能/功耗等级,P0 代表最高性能。
如何查看当前 P-State?
nvidia-smi -q -d PERFORMANCE
里面有 Performance State。
双向 h2d / 双向 d2h
数据在 Host 和 Device 之间双向流动。通常包含两个步骤:
- 首先将数据从 CPU 内存传到 GPU 显存;
- 然后 GPU 计算后再将结果数据传回 CPU,也就是从显存再拷贝回 CPU 内存。
GPU d2h h2d 性能问题
nvidia-smi -q -i 0
可以看 PCI -> GPU Link Info 这部分,能看到有 PCIe Gen 和 Link Width 两部分,都可以作为排查依据。
cccl
NVIDIA/cccl: CUDA Core Compute Libraries
CUB Benchmarks — CUDA Core Compute Libraries
nccl-tests
nccl-tests/nccl 本身没有办法在多机之间进行通信,需要借助 mpi 才行。mpi 是负责进行多机通信的。
nccl-tests 即使是在单机跑,也是有可能会用 GDR 也就是 RDMA 网络的,这和具体版本的 NCCL 的选路逻辑是有关系的。举个例子,如果我们跑的是 all-to-all 的 case,一个机器上有两个 NUMA Node,一个 NUMA node 有四张显卡两张网卡,其中每两张显卡和一张网卡位于一个 PCIe switch 下。如果我们不使用 GDR,那么两张卡之间的最远距离就是从一个 NUMA node 到另一个 NUMA node,需要经过多个 PCIe 上行链路、下行链路、还有 UPI 跨 socket 互联等等。但是如果有 GDR,那么我们只需要通过同 PCIe Switch 下的网卡发送过去就行,PCIe 流量仅仅在 PIX 内部,不会上行,因此会更高。当然,如果有 NVLink 的话,应该都是优先走 NVLink 的,因为 NVLink 要比 GDR 快太多了。
通过 mpirun 使用多机跑 nccl-tests 能够在卡之间直接使用 GDR 来传输。需要保证的是,master 能够 ssh 到所有的 slave。
- 注意 nccl-tests 在编译时要带上:
MPI=1:make -j MPI=1 MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi CUDA_HOME=/usr/local/cuda NCCL_HOME=/root/nccl-master/build/
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make NCCL_HOME=/path/to/nccl # 指定 NCCL 安装路径(默认 /usr/local/nccl)
# 单机 8 卡测试 AllReduce
./build/all_reduce_perf -b 8 -e 256M -f 2 -g 8
# 多机多卡测试
# host 通常可以包含 master 节点,因为一般来说 master 节点也希望参与到计算中去而不仅仅是调度。
# NCCL_NET_GDR_LEVEL=2 表示强制使用 GDR。
# 如果有使用 GDR 传输,还要加上:
# -x NCCL_IB_DISABLE=0
# -x NCCL_NET_GDR_LEVEL=2
# -x NCCL_NET_GDR_READ=1
# -x NCCL_IB_HCA=mlx5_
# 如果是容器里,需要在 slave 的容器里跑:
mkdir -p /run/sshd
chmod 0755 /run/sshd
/usr/sbin/sshd -D -p 2222
# 如果是使用 dmabuf 的方式来进行 GDR,需要下面:
# 需要给 mpirun 加下面的参数才行
-mca plm_rsh_args "-p 2222"
# 需要在 master 的容器里生成密钥,然后拷贝公钥到 slave 容器 authorized_keys 里过去。
ssh-keygen -t rsa
# 最后,测试命令:
mpirun \
-mca plm_rsh_args "-p 2222" \
-mca plm_rsh_no_tree_spawn 1 \
-mca btl_tcp_if_include eth0 \
-bind-to socket \
-mca pml ob1 -mca btl '^uct' \
-x NCCL_DEBUG=INFO \
-x NCCL_IB_DISABLE=0 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_NET_GDR_LEVEL=2 \
-x NCCL_IB_HCA=mlx5_ \
-x LD_LIBRARY_PATH \
--allow-run-as-root \
-H 192.168.1.142:8,192.168.1.143:8 \
~/p/nccl-tests/build/all_reduce_perf -b 512M -e 1G -f 2 -g 1
非容器环境:
mpirun \
-mca plm_rsh_no_tree_spawn 1 \
-mca btl_tcp_if_include eth0 \
-bind-to socket \
-mca btl '^uct' \
-x NCCL_IB_DISABLE=0 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_NET_GDR_LEVEL=2 \
-x NCCL_IB_HCA=mlx5_1,mlx5_2,mlx5_3,mlx5_4 \
-x LD_LIBRARY_PATH \
--allow-run-as-root \
-H 192.168.0.212:8,192.168.0.208:8 \
~/nccl-tests-master/build/all_reduce_perf -b 1M -e 2M -f 2 -g 1
nvbandwidth
如果有 RDMA 网络,会走 RDMA 嘛?
❯ ./nvbandwidth -l (base)
nvbandwidth Version: v0.8
Built from Git version: v0.8
Index, Name:
Description
=======================
0, host_to_device_memcpy_ce:
Host to device CE memcpy using cuMemcpyAsync
1, device_to_host_memcpy_ce:
Device to host CE memcpy using cuMemcpyAsync
2, host_to_device_bidirectional_memcpy_ce:
A host to device copy is measured while a device to host copy is run simultaneously.
Only the host to device copy bandwidth is reported.
3, device_to_host_bidirectional_memcpy_ce:
A device to host copy is measured while a host to device copy is run simultaneously.
Only the device to host copy bandwidth is reported.
4, device_to_device_memcpy_read_ce:
Measures bandwidth of cuMemcpyAsync between each pair of accessible peers.
Read tests launch a copy from the peer device to the target using the target's context.
5, device_to_device_memcpy_write_ce:
Measures bandwidth of cuMemcpyAsync between each pair of accessible peers.
Write tests launch a copy from the target device to the peer using the target's context.
6, device_to_device_bidirectional_memcpy_read_ce:
Measures bandwidth of cuMemcpyAsync between each pair of accessible peers.
A copy in the opposite direction of the measured copy is run simultaneously but not measured.
Read tests launch a copy from the peer device to the target using the target's context.
7, device_to_device_bidirectional_memcpy_write_ce:
Measures bandwidth of cuMemcpyAsync between each pair of accessible peers.
A copy in the opposite direction of the measured copy is run simultaneously but not measured.
Write tests launch a copy from the target device to the peer using the target's context.
8, all_to_host_memcpy_ce:
Measures bandwidth of cuMemcpyAsync between a single device and the host while simultaneously
running copies from all other devices to the host.
9, all_to_host_bidirectional_memcpy_ce:
A device to host copy is measured while a host to device copy is run simultaneously.
Only the device to host copy bandwidth is reported.
All other devices generate simultaneous host to device and device to host interferring traffic.
10, host_to_all_memcpy_ce:
Measures bandwidth of cuMemcpyAsync between the host to a single device while simultaneously
running copies from the host to all other devices.
11, host_to_all_bidirectional_memcpy_ce:
A host to device copy is measured while a device to host copy is run simultaneously.
Only the host to device copy bandwidth is reported.
All other devices generate simultaneous host to device and device to host interferring traffic.
12, all_to_one_write_ce:
Measures the total bandwidth of copies from all accessible peers to a single device, for each
device. Bandwidth is reported as the total inbound bandwidth for each device.
Write tests launch a copy from the target device to the peer using the target's context.
13, all_to_one_read_ce:
Measures the total bandwidth of copies from all accessible peers to a single device, for each
device. Bandwidth is reported as the total outbound bandwidth for each device.
Read tests launch a copy from the peer device to the target using the target's context.
14, one_to_all_write_ce:
Measures the total bandwidth of copies from a single device to all accessible peers, for each
device. Bandwidth is reported as the total outbound bandwidth for each device.
Write tests launch a copy from the target device to the peer using the target's context.
15, one_to_all_read_ce:
Measures the total bandwidth of copies from a single device to all accessible peers, for each
device. Bandwidth is reported as the total inbound bandwidth for each device.
Read tests launch a copy from the peer device to the target using the target's context.
16, host_to_device_memcpy_sm:
Host to device SM memcpy using a copy kernel
17, device_to_host_memcpy_sm:
Device to host SM memcpy using a copy kernel
18, host_to_device_bidirectional_memcpy_sm:
A host to device copy is measured while a device to host copy is run simultaneously.
Only the host to device copy bandwidth is reported.
19, device_to_host_bidirectional_memcpy_sm:
A device to host copy is measured while a host to device copy is run simultaneously.
Only the device to host copy bandwidth is reported.
20, device_to_device_memcpy_read_sm:
Measures bandwidth of a copy kernel between each pair of accessible peers.
Read tests launch a copy from the peer device to the target using the target's context.
21, device_to_device_memcpy_write_sm:
Measures bandwidth of a copy kernel between each pair of accessible peers.
Write tests launch a copy from the target device to the peer using the target's context.
22, device_to_device_bidirectional_memcpy_read_sm:
Measures bandwidth of a copy kernel between each pair of accessible peers. Copies are run
in both directions between each pair, and the sum is reported.
Read tests launch a copy from the peer device to the target using the target's context.
23, device_to_device_bidirectional_memcpy_write_sm:
Measures bandwidth of a copy kernel between each pair of accessible peers. Copies are run
in both directions between each pair, and the sum is reported.
Write tests launch a copy from the target device to the peer using the target's context.
24, all_to_host_memcpy_sm:
Measures bandwidth of a copy kernel between a single device and the host while simultaneously
running copies from all other devices to the host.
25, all_to_host_bidirectional_memcpy_sm:
A device to host bandwidth of a copy kernel is measured while a host to device copy is run simultaneously.
Only the device to host copy bandwidth is reported.
All other devices generate simultaneous host to device and device to host interferring traffic using copy kernels.
26, host_to_all_memcpy_sm:
Measures bandwidth of a copy kernel between the host to a single device while simultaneously
running copies from the host to all other devices.
27, host_to_all_bidirectional_memcpy_sm:
A host to device bandwidth of a copy kernel is measured while a device to host copy is run simultaneously.
Only the host to device copy bandwidth is reported.
All other devices generate simultaneous host to device and device to host interferring traffic using copy kernels.
28, all_to_one_write_sm:
Measures the total bandwidth of copies from all accessible peers to a single device, for each
device. Bandwidth is reported as the total inbound bandwidth for each device.
Write tests launch a copy from the target device to the peer using the target's context.
29, all_to_one_read_sm:
Measures the total bandwidth of copies from all accessible peers to a single device, for each
device. Bandwidth is reported as the total outbound bandwidth for each device.
Read tests launch a copy from the peer device to the target using the target's context.
30, one_to_all_write_sm:
Measures the total bandwidth of copies from a single device to all accessible peers, for each
device. Bandwidth is reported as the total outbound bandwidth for each device.
Write tests launch a copy from the target device to the peer using the target's context.
31, one_to_all_read_sm:
Measures the total bandwidth of copies from a single device to all accessible peers, for each
device. Bandwidth is reported as the total inbound bandwidth for each device.
Read tests launch a copy from the peer device to the target using the target's context.
32, host_device_latency_sm:
Host - device access latency using a pointer chase kernel
A 2MB buffer is allocated on the host and is accessed by the GPU
33, device_to_device_latency_sm:
Measures latency of a pointer derefernce operation between each pair of accessible peers.
A 2MB buffer is allocated on a GPU and is accessed by the peer GPU to determine latency.
--bufferSize flag is ignored
34, device_local_copy:
Measures bandwidth of cuMemcpyAsync between device buffers local to the GPU.
How to install NVIDIA bunch of things?
How to remove NVIDIA driver and CUDA?
# 卸载驱动
sudo apt-get purge nvidia-*
sudo apt-get autoremove
sudo rm /etc/X11/xorg.conf # 删除Xorg配置文件(如果存在)
sudo rm /etc/modprobe.d/blacklist-nouveau.conf # 删除 nouveau 黑名单文件(如果存在)
# 卸载 cuda
sudo apt-get purge "*cuda*" "*cublas*" "*cufft*" "*curand*" "*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "nsight*" # 使用apt purge清理CUDA相关包:cite[4]:cite[8]
sudo apt-get autoremove
How to install and check nvidia-fabricmanager?
sudo apt-get install nvidia-fabricmanager-<driver_version>
systemctl enable nvidia-fabricmanager
systemctl start nvidia-fabricmanager
How to install and check NVIDIA GPU driver?
可以看一下这个页面:CUDA Toolkit Downloads | NVIDIA Developer 可以直接把 driver 和 CUDA 都安装了。
注意!⚠️:如果是 NVLink 的机型,在安装完成后记得安装一下 nvidia-fabricmanager 并且启动服务,否则
torch.cuda.is_available()会报错。
NVIDIA 最近开源了一版驱动:NVIDIA/open-gpu-kernel-modules: NVIDIA Linux open GPU kernel module source version 575.64。从 515 开始,NVIDIA 会 release 专用的和开源的两版驱动。目前的话,开源的已经是默认安装方式了。
The NVIDIA Linux GPU Driver contains several kernel modules:
nvidia.konvidia-modeset.konvidia-uvm.konvidia-drm.ko- `nvidia-peermem.koiPI Reference — TensorRT-LLM](https://nvidia.github.io/TensorRT-LLM/llm-api/reference.html#tensorrt_llm.llmapi.TorchLlmArgs)
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。