LLM
LLM Map / AI Map
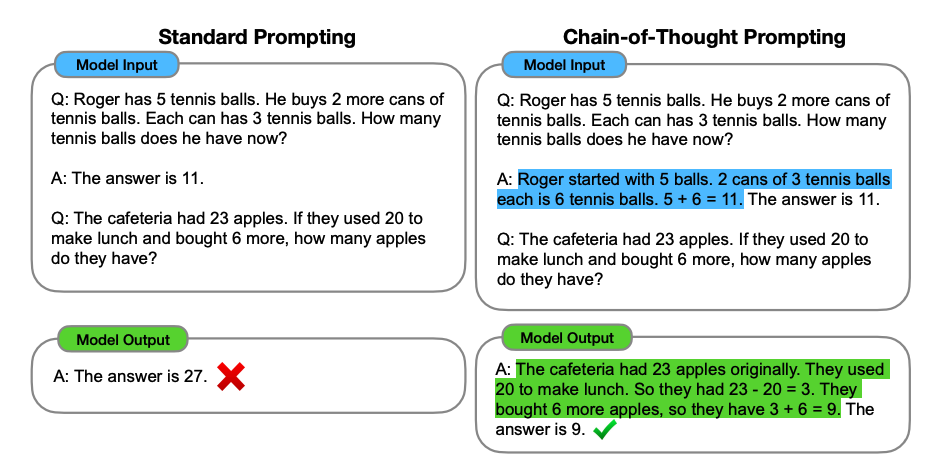
CoT (Chain-of-Thought) 思维链
不是什么模型结构,也不是什么训练技巧,是一个提示词工程,因此,Chain-of-Thought 又被称为 Chain-of-Thought Prompting。一图以蔽之:
flashinfer
也是算子库,只不过是聚焦于大模型的 Serve 也就是推理侧。
什么是 token?
Prefill and Decode
- Prefill 阶段:生成第一个 token 之前;
- Decode 阶段:后续一个 token 一个 token 生成。
PD 分离:Prefill 节点专门处理 Prefill 请求,Decode 阶段处理 Decode 请求,Prefill 完成后把 KVCache 发送到 Decode 节点上。
EPD 分离:针对 VLM 模型。E 表示 Encode 就是把视频数据先编码成为 token。
Pre-train 预训练 / Post-train 后训练
LoRA (Low-Rank Adaptation)
Encoder-Decoder / Encoder-Only / Decoder-Only
现在的 LLM 其实都没有 Encoder 了,因为都是 Decoder-Only 架构的:当前的 ChatGPT、DeepSeek-V3、Gemini、Grok 和 Claude 等模型,均采用 Decoder-only 架构。
Encoder-Only 架构,也被称为单向架构,仅包含编码器部分。它主要适用于不需要生成序列的任务,只需要对输入进行编码和处理的单向任务场景,如文本分类、情感分析等。这种架构的代表是 BERT 相关的模型,例如 BERT、RoBERT 和 ALBERT 等。
Decoder-Only 架构,也被称为生成式架构,仅包含解码器部分。它通常用于序列生成任务,如文本生成、机器翻译等。这种架构的模型适用于需要生成序列的任务,可以从输入的编码中生成相应的序列。同时,Decoder-Only 架构还有一个重要特点是可以进行无监督预训练。在预训练阶段,模型通过大量的无标注数据学习语言的统计模式和语义信息。Decoder-Only 架构的优点是擅长创造性的写作,比如写小说或自动生成文章。它更多关注于从已有的信息(开头)扩展出新的内容。
对于 LLM,首先排除 encoder-only,原因主要有两点:
- 生成能力天生不足;
- 繁琐的任务头不够优雅;
抛开 encoder-only 之后,现在只剩下 encoder-decoder 与 decoder-only 之争了。个人感觉其实这俩之间没啥好纠结的,大道至简的哲学告诉我,无脑选 decoder-only!
【OpenLLM 001】大模型的基石-架构之争,decoder is all you need? - 知乎
SGLang / vLLM / TensorRT-LLM / xDiT
SGLang 和 vLLM 都是伯克利团队开发的。是和 vLLM 在同一个身位竞争的,也就是大模型服务(Serving)框架。
SGLang 发展更快,代码更干净,性能也更好;vLLM 老牌一些,起步早,用的公司更多。
- vLLM:适合高并发场景,如在线客服、实时翻译等需要实时响应和处理大量并发请求的应用。
- SGLang:更适合多轮对话、推理任务和多模态输入等复杂场景,以及需要处理复杂逻辑和多步骤任务的应用。
- TensorRT-LLM:NV 自己的,性能应该很好。
- xDiT:多模态场景下的推理框架。
- xLLM:字节自研的推理框架。
MTP (Multi-Token Prediction) / Speculative Decoding
这两个是同一个概念,就是一次预测多个未来 Token。
EAGLE: SafeAILab/EAGLE: Official Implementation of EAGLE-1 (ICML'24), EAGLE-2 (EMNLP'24), and EAGLE-3.
什么是 LLM Agent?
LLM Agent 是一种基于大语言模型(如 GPT、PaLM、LLaMA 等)构建的智能系统,能够自主理解目标、规划任务、调用工具并完成复杂操作。它不仅是“生成文本的模型”,更是一个具备推理、决策和行动能力的智能代理,可类比为“能主动思考和行动的 AI 助手”。
和强化学习里的 Agent 是不一样的。
Dense / Sparse 模型
给定一个输入,如果模型的所有参数都参与了计算,那么这就是 dense 稠密模型。反之,如果模型只有部分参数用于处理输入。那就是 sparse 稀疏模型。举例来说。稀疏模型里有稀疏专家模型。这类模型的参数被划分为好几个专家。对于一个输入,只有最适合这个输入的专家将会参与计算,这就是稀疏计算。
Dense 模型一般比较小,一般单机或者说单卡都可以跑。
深度学习中的sparse和dense模型指的是什么? - 知乎
算子优化/加速库和项目
算子实际上是面向深度学习任务高度优化的函数,它是网络中层或者节点的计算逻辑,开发者在实现这些计算逻辑的时候,不仅要实现功能逻辑,还要考虑硬件指令的适配,如何支持不同大小/类型的输入,以及如何针对不同的输入 Shape 进行切分,并保证算子的运行性能。可见,一个算子的代码如此复杂,如果神经网络中的每一个算子都由开发人员实现一遍,那么可想而知,神经网络构建的工作量有多大,难度有多高,特别是面对当前日益复杂的大模型。能否针对某种计算逻辑开发一个通用实现?这样,开发者便像搭房子一样构建网络而无需关注具体的算子实现。
FlashAttention: Dao-AILab/flash-attention: Fast and memory-efficient exact attention
- FlashAttention 属于开源的算子优化项目之一,它主要针对 Transformer 模型中的注意力机制进行优化。本来是一篇论文,是一个新的 attention 算法,能够减小内存压力。
FasterTransformer: NVIDIA/FasterTransformer: Transformer related optimization, including BERT, GPT
- FasterTransformer 是一个用于加速 Transformer 模型推理的开源库。它提供了高度优化的 Transformer 编码器和解码器组件,支持多种模型和精度,包括 FP16、INT8 等。
什么是 context caching
什么是模型蒸馏?
是一种模型压缩技术。旨在把一个大模型或者多个模型(教师模型) ensemble 学到的知识迁移到另一个轻量级单模型(学生模型)上,方便部署。简单的说就是用新的小模型去学习大模型的预测结果,改变一下目标函数。听起来是不难,但在实践中小模型真的能拟合那么好吗?所以还是要多看看别人家的实验,掌握一些 trick。应用场景:
- 模型压缩与加速:在计算资源有限的情况下,例如移动设备和边缘计算,知识蒸馏可以用于将大模型转化为可以在资源受限的环境中高效运行的小模型。
- 实时推理:对于需要实时响应的应用(如视频监控、自动驾驶等),知识蒸馏可以使得模型在保持较高准确率的同时,减小延迟。
- 迁移学习:在迁移学习场景中,知识蒸馏可以帮助将源领域的知识迁移到目标领域,特别是在目标领域样本稀缺的情况下。
- 多模态学习:在多模态任务中,可以通过知识蒸馏将不同模态下训练得到的知识进行融合,提高模型的综合性能。
- 模型集成:通过将多个模型的知识进行蒸馏,可以在不增加计算复杂度的情况下,继承多个模型的优点,从而提升整体性能。
RAGs(检索增强生成, Retrieval-Augmented Generation)
In-context learning
单机单卡、单机多卡以及多机多卡的业务场景
MoE 架构需要用到多机?
什么是多轮对话?
- User:你好,System Response:你好呀。
- User:你好,你好呀,今天天气怎么样;System Response: 今天天气不错。
- User:你好,你好呀,今天天气怎么样,今天天气不错,所以我应该穿什么;System Response:穿大衣。
可以看到虽然每次我们都问了新问题,但是其实背后会带上之前所有的对话历史,只是我们看不到而已。
flash-attention
SFT (Supervised Fine-Tuning) 有监督微调
IFT (Instruction Fine-Tuning) 指令微调
RLHF (Reinforcement Learning from Human Feedback)
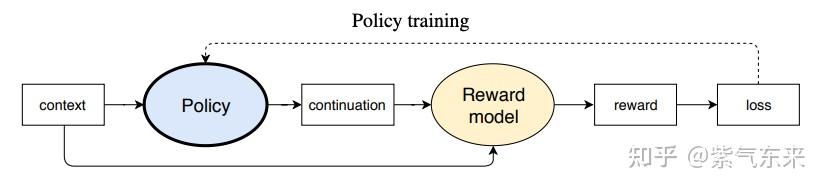
原理都在下面的图里:
https://ai.feishu.cn/docx/X2Q9dHfDUogpzkx9D8gc6NAonrd#share-G0NidYIvGoYhcSxj64hcoW37nxc
- context 就是 prompt,我们的输入,也就是状态 state;continuation 就是输出,每一个 token 是一个 action,转移到的新状态为输入 + 当前输出 + next token,也即 $s^\prime = (s, a)$;
- Policy 就是我们的 LLM,在 RL 的语境中就是智能体,也就是 Agent,以 context(state) 为输入,以 continuation token(action) 为输出;
- Reward model 也就是环境,接收 (context, continuation),评估好坏,打分生成 reward,这个 reward model 是预先训练好的;
- 基于 reward 来更新 policy。
奖励信号
在标准的 RLHF(尤其是使用 PPO 算法时)中,Reward Model 是在整个序列(即所有 token)生成完毕后,才对整个序列进行一次评估,并输出一个总的奖励值(scalar reward)。逐 token(per-token)的奖励是极其罕见且通常不实用的。
流程:
- 生成: 语言模型(Policy Model)接收一个提示(Prompt),并自回归地生成一个完整的响应(Response),由多个 token 组成。
- 评估: 将这个完整的响应(连同最初的提示一起)输入到奖励模型(Reward Model)中。
- 打分: 奖励模型对这个完整的响应进行整体评估,并输出一个单一的标量奖励值(Scalar Reward)。这个值代表了该响应整体上的“好坏”(例如,是否有帮助、是否无害、是否符合人类偏好)。
- 训练: 这个总奖励值被用于强化学习算法(如 PPO)中来更新策略模型(Policy Model)。PPO 会计算每个生成 token 的“优势”(Advantage),但这个优势是基于最终的总奖励回溯计算得出的,而不是来自多个独立的奖励信号。
Training 过程分为两步:Reward model training 和 Policy model training。
状态转移满足马尔可夫性吗?
看起来是非常满足的,因为的确下一个状态(或者说下一个 token/action)的生成概率仅仅基于当前所有的 tokens,也就是当前状态,和以前的走过的状态无关(到达这个状态也只有一条路能走,见上图,是一个倒 $N$ 叉树的结构,$N$ 非常大,取决于所有可能的取词空间,初始状态就是还没有 token 的时候)。有时间可以详细调研一下,这种模式和传统的状态转移模式在训练上的区别/对训练效果可能造成的影响。
Rollout
Rollout 指的是利用当前策略模型(actor)在给定的输入(prompt)下生成一系列回复,并对这些回复进行评估(如计算 log 概率、价值估计和奖励)的过程。
Context size / context length in LLM
什么是 LLM 中的 context length / context size?
在生成一个 token 的时候,我们能注意到前面多少个 token 的内容。
输入矩阵是 $M \times N$,$N$ 表示表示一个词语需要的向量空间长度,而 $M$ 也就是 token 数,表示 context size。
- GPT-3 的 context size 是 2048;
- Qwen3: 32768;
- llama2: 4096;
- DeepSeek-R1: 128k.
Context size 包含输入到输出的所有 token 吗?
是的。 输入 + 输出的总 token 数不能超过模型的上下文窗口。
如果输入 token 数超过了 context size 会怎样? / 模型截断
会发生截断,比如只保留后面部分的 token。
模型是如何做到输入 + 输出小于 context window 的时候就停止输出的?
当程序检测到生成了 <end> token 后就会终止。
Context length / context size 的时间复杂度和空间复杂度
时间复杂度 $O(n^2)$:
- Step 1:相似度计算可以看作大小为 $(n,d)$ 和 $(d,n)$ 的两个矩阵相乘:$(𝑛,𝑑)∗(𝑑,𝑛)=𝑂(𝑛^2⋅𝑑)$ ,得到一个 $(n,n)$ 的矩阵;
- Step 2:softmax 就是直接计算了,时间复杂度为 $𝑂(𝑛^2)$;
- Step 3:加权平均可以看作大小为 $(n,n)$ 和 $(n,d)$ 的两个矩阵相乘:$(𝑛,𝑛)∗(𝑛,𝑑)=𝑂(𝑛^2⋅𝑑)$ ,得到一个 $(n,d)$ 的矩阵。
因此,Self-Attention 的时间复杂度是 𝑂(𝑛^2⋅𝑑) 。$d$ 应该是一个不会变的常数。
空间复杂度:
存储 $𝑄𝐾^T$, 是 $𝑂(𝑁^2)$。
什么是 KV Cache
KV Cache 是 token 级的,一个 token 对应一个 KV Cache。不过推理引擎中一般是以 Block 的方式来管理 KV Cache 的。一个 Block 可以有几十个 token 的 KV Cache。
KV Cache 只在 decoder 当中才会有,encoder 中没有。
Prefill 阶段也可以利用上 KV Cache。
每一层 decoder 都有自己的 KV Cache。
生成 KV Cache 非常耗时,其计算复杂度随输入长度平方增长。然而在许多场景下,不同请求间存在重复或相似的上下文,例如相同的系统提示、多轮对话中的上下文复用、或多个代理任务共享部分知识。这就意味着如果能复用之前计算得到的 KV Cache,则无需每次都从零计算,能够显著降低延迟和计算消耗。
KV Cache 之所以存在,是因为 mask 机制。请看下面的例子。
理解了 mask 机制,你就会发现,直接:
\[Attention(Q,K,V)=sofltmax(\frac{QK^T}{\sqrt{d_k}})V\]其实是有误导,让我们以为我们是整个矩阵一起计算的,其实不是,而是一行一行进行计算的。
使用 KV Cache 加速 decode 阶段的一个例子
从上帝视角来看,假设我们最后 decode 要生成的是“遥遥领先”。当生成第一个“遥”时,attention 计算如下:
input="<s>"(因为还没有输出过任何内容所以只有一个起始字符,整个矩阵其他部分被 mask 掉了,不需要计算)。下面其实计算出来的是 <s> 和他自己的 attention。
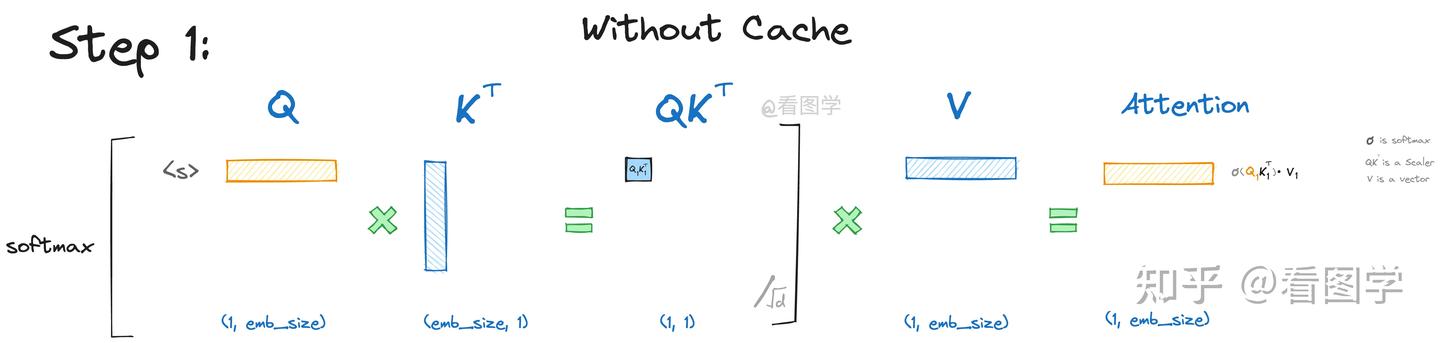 $$ \operatorname{Att}_1(Q, K, V)=\operatorname{softmax}\left(Q_1 {K_1}^T\right) \overrightarrow{V_1}=\operatorname{softmaxed}\left(Q_1 K_1^T\right) \overrightarrow{V_1}
$$ \operatorname{Att}_1(Q, K, V)=\operatorname{softmax}\left(Q_1 {K_1}^T\right) \overrightarrow{V_1}=\operatorname{softmaxed}\left(Q_1 K_1^T\right) \overrightarrow{V_1}
\begin{aligned}
& \operatorname{Att}_1(Q, K, V)=\operatorname{softmaxed}\left(Q_1 K_1^T\right) \overrightarrow{V_1} \
& \operatorname{Att}_2(Q, K, V)=\operatorname{softmaxed}\left(Q_2 K_1^T\right) \overrightarrow{V_1}+\operatorname{softmaxed}\left(Q_2 K_2^T\right) \overrightarrow{V_2}
\end{aligned}
\[你会发现,由于 $Q_1K_2^T$ 这个值会被 mask 掉: - $Q_1$ 在第二步参与的计算与第一步是一样的(都是在 $Att_1$ 中进行了计算),而且 $Att_1$ 也仅仅依赖于 $Q_1$ ,与 $Q_2$ 毫无关系。 - $Att_2$ 的计算也仅仅依赖于 $Q_2$ ,与 $Q_1$ 毫无关系。 **第三步**: 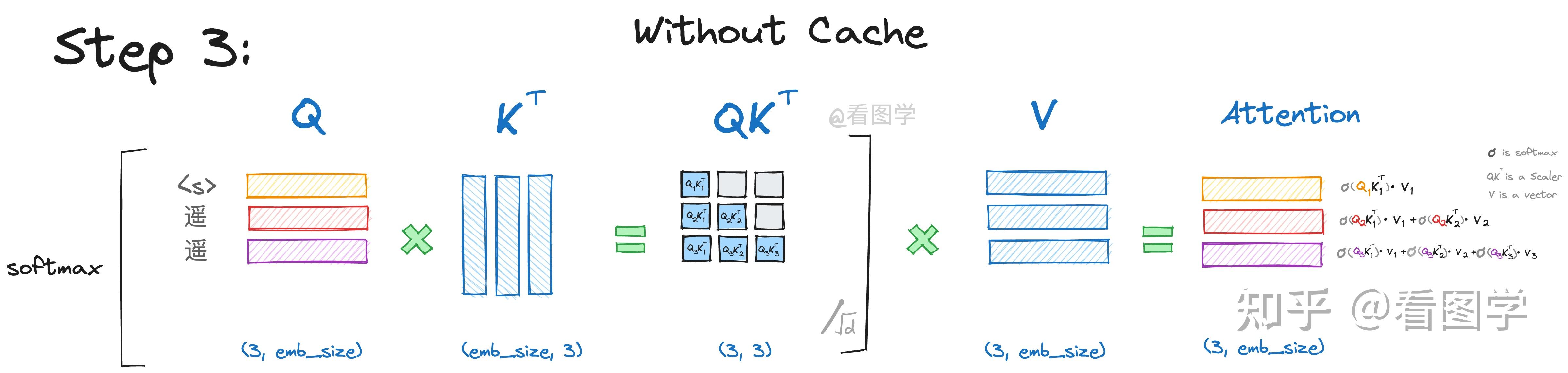 可以看到在每一步的计算中,$QK^T$ 矩阵的右上角部分都是灰色的。这是为什么呢?看起来是每一个 $Q$ 里的每一行(token)在乘到自己的 $K^T$ 里的那一列之后就不会再往后算了。**这是因为 Decoder 有 Casual Mask,在推理的时候前面已经生成的字符不需要拿到其后面的字符所贡献的 attention(一篇文章的内容都是渐进式的,前面的内容会对后面的内容有贡献,但是后面的内容对前面的内容少有贡献),从而使得前面已经计算的 $K$ 和 $V$ 可以缓存起来。**\]\begin{aligned}
& \operatorname{Att}_1(Q, K, V)=\operatorname{softmaxed}\left(Q_1 K_1^T\right) \overrightarrow{V_1} \
& \operatorname{Att}_2(Q, K, V)=\operatorname{softmaxed}\left(Q_2 K_1^T\right) \overrightarrow{V_1}+\operatorname{softmaxed}\left(Q_2 K_2^T\right) \overrightarrow{V_2} \
& \operatorname{Att}_3(Q, K, V)=\operatorname{softmaxed}\left(Q_3 K_1^T\right) \overrightarrow{V_1}+\operatorname{softmaxed}\left(Q_3 K_2^T\right) \overrightarrow{V_2} + \operatorname{softmaxed}\left(Q_3 K_3^T\right) \overrightarrow{V_3}
\end{aligned}
$$
同样:$Att_k$ 只与 $Q_k$ 有关。在每次生成新 token $i$ 时,只需要计算 $Att_i$ 了。
我们每一步其实只需要根据 $Q_k$ 计算 $Att_k$ 就可以,之前的 $Q$ 可以都丢掉,而且之前已经计算的 Attention 完全不需要重新计算。但是 $K$ 和 $V$ 是全程参与计算的,所以这里我们需要把每一步的 $K_i$ 和 $V_i$ 缓存起来,以供下一次使用。衍生问题: 是不是 Prefill 阶段之前的 Q 和 Attention 都不需要计算?因为我们只基于最后一个 attention 值来预测。
所以说叫 KV Cache 好像有点不太对,因为 KV 本来就需要全程计算,可能叫增量 KV 计算会更好理解。可以看到,KV Cache 也是随着推理过程而逐渐变大的。 KV Cache 的大小主要是和 token 数量是成平方比的。 因为需要存对角矩阵个 K 和 V。
这么来说,好像 $Att_i$ 计算一次之后后面也不需要再计算,也可以叫做 Cache?不过应该不需要对 Att 的结果做 Cache,因为我们每次都是用最后一列 Att 来预测下一个词的。
这篇文章讲的非常好,强烈推荐:(55 封私信 / 80 条消息) 大模型推理加速:看图学KV Cache - 知乎
KV Cache 在多层 Attention 中会有变化吗?
KV Cache 可以跨对话复用吗?/ Prefix Caching / RadixAttention
这是两个问题:
- 多个会话:这个应该是不可以的,但是 maybe system prompt 可以复用(如果所有 user 用的是同一个 system prompt 的话)?
- 多轮对话:可以复用。
结论:本质上来说,都是仅有公共前缀部分可以复用。
从单个 token 的视角来看,对于一个 token,只有第一层 Attention 计算出来的 $Q$, $K$, $V$ 的每一行的值是固定的(行排列可能不一样),因为都是基于原始 embedding 与 $W^Q$, $W^K$, $W^V$ 计算出来的,这两部分是确定的,因此出来的内容是固定的。
但是因为从第二层开始,每一个 token 的 embedding 融入了周边 token 的信息,因此就变得不一定了,所以没有办法复用。
但是从多轮对话的形式来看,因为每次都会带上之前对话历史作为前缀,所以是可以复用的。
但是现在有多轮对话复用 KV Cache 技术,本质上是:
由于大部分自回归模型的 Attention Mask 都是下三角矩阵,即某一位置 token 的注意力与后续 token 无关,因此两轮对话公共前缀部分的 KV cache 是一致的。 通过复用这些 KV cache,可以减少下一轮需要生成 KV cache 的 token 数,从而减少 FTT。
这给了我们一个启发,那就是区分 system prompt 和 user prompt,这样 system prompt 就可以作为公用前缀复用 KV cache 了。
采用了前缀 KV Cache 复用的叫做 Prefix Caching 技术,SGLang 的 Prefix Caching 技术叫做
KV Cache 的代码实现
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
LLM Inference Process Overview
大模型推理阶段分为两个过程,prefill 和 decode:
- prefill 是用户输入完 prompt 到生成首个 token 的过程,
- decode 则为生成首个 token 到推理停止的过程。
Prefill (where large prompt embeddings are generated) is highly compute-intensive, while decode (where tokens are generated) is latency-sensitive.
Prefill 长度和 Decode 长度的区别:可能一个是指用户输入的长度,一个是指回答的长度。如何两者相差太大,PD 分离是一个好的选择。
- Prefill 阶段:将用户输入的 prompt 拆成 tokens 并并行生成 KV,只计算最后一个 token 和之前所有 token 的 $Att_i$ 值?所以只需要计算最后一个 token 的 Q 也就是 $Q_i$? 把 KV(因为 decode 时不依赖之前的 Q 所以可以不存 Q)存入 KV Cache(为 decode 阶段缓存)。这一步计算并行好,是计算密集型 compute bound;
- Decode 阶段:由最新产生的 token $i$ 生成 $Q_i$, $K_i$, $V_i$,计算它与之前所有 tokens 的 attention,这一步需要从 KV Cache 中读取前面所有 token 的 key、value,因此是内存密集型 memory bound。
大模型推理阶段KV计算分析:prefill和decode - 知乎
LLM Prefill Phase
是 Inference 中的一个阶段,不要把它当成训练中的阶段。
如果有基础不理解,建议补充下 [[#什么是 KV Cache]] 的内容。Prefill 阶段需要计算所有的 KV Cache,是计算密集型的。


Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
注意不要弄混 Prefill 和 Encoder,这两个不是同一个东西。很多 LLM 都是 Decoder-Only 架构,是没有 encoder 的,但是都还是有 Prefill 阶段的。
在 prefill 阶段,大模型一次性对 prompt 中所有 token(也就是 sequence) 并行进行计算 QKV,由于不同 token 的计算是独立的,因此该过程可以并行。在 attention 部分,由计算得到的 QKV 进一步计算出 Output 矩阵,再经过后续的 FFN 层和解码得到首字母 token。
Prompt token 的 KV Cache 是在这里生成的,注意是 prompt token,而不是输出的 token。
这一步是计算密集型的。Prefill 阶段的计算量通常较大,尤其是在处理长提示时。
为什么 Prefill 阶段可以并行对每一个 token 进行计算?
仔细想想:Prefill 阶段其实就是没有 cache 可用的 Decode 阶段。
还是以 [[#什么是 KV Cache]] 为例,我们假设第三步的时候,第一个遥字其实是用户的输入,就好理解了。所谓对每一个 token 进行并行计算 KV Cache,其实就是把所有 token 还是组合放到一个矩阵里面,然后直接乘以 $W_Q$, $W_K$, $W_V$ 就可以同时得到每一个 token 的 $Q_i$, $K_i$ 和 $V_i$ 了。
LLM Decode Phase
Decode 阶段负责根据 Prefill 阶段生成的 KV 缓存,依次解码生成后续输出 token,对内存带宽和缓存依赖更强。Decode 阶段的显存消耗通常较大,因为 KV 缓存会随着生成过程不断增长。
基于当前 token 和历史 KV Cache 以自回归(会进行多轮计算,每一轮计算的输出会作为下一次计算的输入,也就是多轮计算)的方式来逐个生成新的 token,在新生成 token 的过程中,会保存当前 token 的 KV Cache。
在 decode 阶段,计算原理和 prefill 完全相同,但计算方式不一样的。原因有两个。一是随着 seqlen 增加,Attention 计算复杂度平方级增长,直接计算代价很大,导致长序列的推理时间极慢,甚至不可行。二是对 decode 阶段的计算过程简单分析发现,该过程可以复用 prefill 阶段的 KV 结果,也可以复用 docode 阶段已经产生的 KV 结果。综上,可以把已产生的 KV 存起来,不必重新计算,这就是 KV cache。对于 Q 矩阵,每次需要计算的只是 Q 的最后一行 q,计算关于 qKV 的 attention,而不是关于 QKV 的 attention,这样复杂度降低了一个量级,实现以存换算。
Decode 过程输出的 token 的长度是由谁决定的呢?
自回归过程直到满足停止条件:
- 所有 LLM 都有一个硬性限制,即输入 + 输出的总 token 数不能超过其上下文窗口大小。例如:GPT-4 通常为 8k/32k tokens,Llama 3 为 8k tokens。因此,如果输入(prompt)过长,剩余可生成的 token 数会减少。
- 调用生成接口(如 model.generate())时,可通过以下参数显式控制生成长度:
max_new_tokens,max_length,min_new_tokens/min_length。 - …
P/D 分离
传统集成式推理流水线往往将 LLM 的 Prefill 和 Decode 阶段置于同一 GPU 上运行,资源需求不匹配导致 GPU 利用率不高。在推理服务中,如果用户请求 prefill 长度和 decode 长度非常不匹配,PD 分离是一个很好的选择。这项技术是由 DistServe 和 Splitwise 等 paper 提出来的。
Prefill 先计算出来 KV Cache,然后发送给 Decode 节点?
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。