GPU
Tips:
- GPU 内存就是显存。
GPU 卡间架构
GPUDirect / GPDR
和 DMA 的关系?
NVLink
GPU 单卡架构
Nvidia driver 对上提供什么 API
DOCA
SIMT vs. SIMD
比如我们有四个数字要加上四个数字,那么我们可以用这种 SIMD 的指令来一次完成本来要做四次的运算。这种机制的问题就是过于死板,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外。
相比之下 SIMT 就更加灵活了,虽然两者都是将相同指令广播给多个执行单元,但是 SIMT 的某些线程可以选择不执行,也就是说同一时刻所有线程被分配给相同的指令,SIMD 规定所有人必须执行,而 SIMT 则规定有些人可以根据需要不执行,这样 SIMT 就保证了线程级别的并行,而 SIMD 更像是指令级别的并行。
SIMT 包括以下 SIMD 不具有的关键特性:
- 每个线程都有自己的指令地址计数器;
- 每个线程都有自己的寄存器状态;
- 每个线程可以有一个独立的执行路径;
而上面这三个特性在编程模型可用的方式就是给每个线程一个唯一的标号 (blckIdx, threadIdx),并且这三个特性保证了各线程之间的独立。
CUDA执行模型GPU架构 GPU架构是围绕一个流式多处理器(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件 - 掘金
线程束(Warps)/ Warp scheduler
CUDA 采用单指令多线程 SIMT 架构管理执行线程,不同设备有不同的线程束大小,但是到目前为止基本所有设备都是维持在 32,也就是说每个 SM 上有多个 block,一个 block 有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻 T,SM 上只执行一个线程束,也就是 32 个线程在同时同步执行,线程束中的每个线程执行同一条指令,但是使用的都是私有数据,也就是以不同的数据资源执行相同的指令。线程同时在相同的程序地址启动。
一个 SM 上在某一个时刻,有 32(目前都是 32,硬件工程师的选择,不保证未来也是)个线程在执行同一条指令,这 32 个线程可以选择性执行,虽然有些可以不执行,但是他也不能执行别的指令,需要执行这条指令的线程执行完,然后再继续下一条。
线程束是 SM 里的硬件概念,表示了这个 SM 所能同时执行的线程数量。
线程束和 SM 里的 CUDA core 数量相当吗?不是,后者一般是前者整数倍,一个 SM 的 CUDA core 会分成几个 warp(即 CUDA core 在 SM 中分组),由 warp scheduler 负责调度。warp scheduler 调度是硬件行为,warp scheduler 会自动感知当前的 warp 是否是等待的状态,然后切换到另外一个 warp。切换的时候应该就是改一下调度器的 PC,指到新的 warp。然后更新一下当前的寄存器集就行了。
一个 CUDA core 可以执行一个 thread。每一个 SM 有多个 warp scheduler,因为一个 warp 对应一个 scheduler。
线程束和线程块,一个是硬件层面的线程集合,一个是逻辑层面的线程集合。 一旦线程块被调度在一个 SM 上,线程块中的线程会被进一步划分为线程束,因此线程束(wraps)是比线程块(blocks)更小的单位。
了解 warp 可以帮助理解和优化特定 CUDA 设备上 CUDA 应用程序的性能。
SM详解与Warp Scheduler,合理块和线程的数量对GPU利用率非常重要 - 知乎
流式多处理器(SM, Streaming Multiprocessor)
Nvidia 特有概念,每个 GPU 通常有多个 SM,当一个 kernel 的 grid 被启动的时候,多个 block 会被同时分配给可用的 SM 上执行。
当一个 block 被分配给一个 SM 后,他就只能在这个 SM 上执行了,不可能重新分配到其他 SM 上了,多个 block 可以被分配到同一个 SM 上。因此同一块中的线程能够以不同于不同块之间的线程的方式相互交互(因为 share 同一个 SM)。
在 SM 上同一个块内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
为什么 GPU 要划分 SM?
- 主要目的是提高 GPU 的并行计算能力和资源利用率。GPU 就可以通过将将计算任务分解成多个小部分的工作分配给不同的 SM 并行执行,从而加快计算速度。
- 避免不同计算任务之间的资源竞争,提高 GPU 并行性能。
体感认识:Ampere A100 GPU 具有 108 个 SM,每个 SM 有 64 个核心,总共在整个 GPU 中有 6912 个核心。
一般不支持乱序执行。
下图区分硬件和软件上的概念:
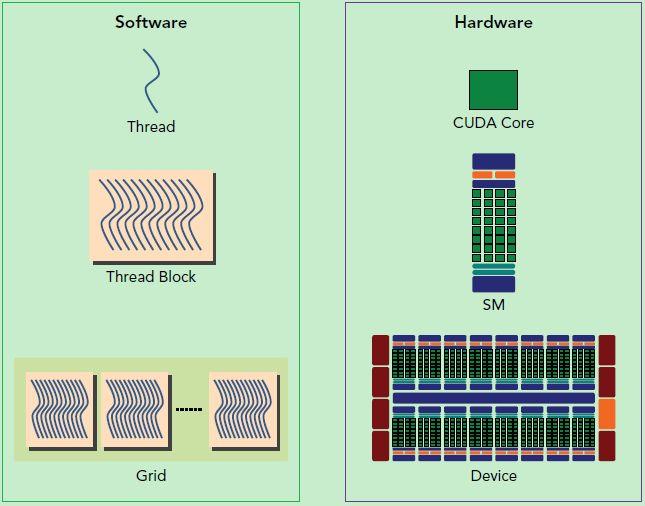
GPU 如何知道自己应该运行什么程序?
显存 / GPU Memory
显存大小和模型大小的对应关系:如果只是进行推理的话,还是比较容易计算的。目前模型的参数绝大多数都是 float32 类型, 占用 4 个字节。所以一个粗略的计算方法就是,每 10 亿(1B)个参数,占用 4G 显存 (实际应该是 ,为了方便可以记为 4G)。
HBM2 / HBM2e / GDDR
因为 DDR^ 是面向内存的,而内存带宽在 GPU 领域里还是不太够。因此如果我们想要以更快的速度访问显存的话,就需要 GDDR 了。
DDR 在下降沿和上升沿都传输,所以叫做 Double Rate,而 GDDR (Graphic DDR) 通过定义了多个沿来传输,实现了四倍甚至更高的速度。
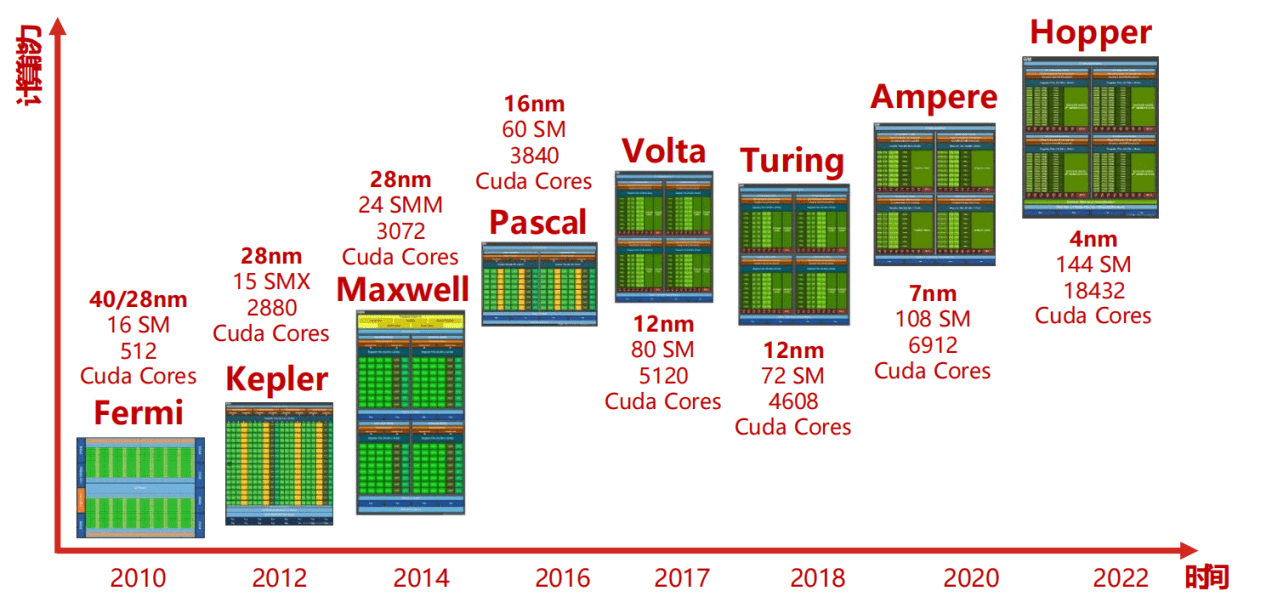
Nvidia GPU 架构演进 / A10
截止到 2024 年的所有 Nvidia GPU 架构:NVIDIA GPU 核心与架构演进史 – 陈少文的网站
区分系列名,架构名和型号名:
- GeForce 等等都是系列名;
- Ampere, Hopper 都是架构名;
- A100, H100 都是型号名。
可以看到,后面出的 CPU 型号名和架构名都是有关联的,比如:
- Ampere 架构:型号名 A100
- Hopper 架构:型号名 H100
- Blackwell 架构:型号名 B100
FYI: 3070ti 显卡用的是 Ampere 架构。
A10: NVIDIA A10 datasheet
- 24GB 显存。
A100: NVIDIA A100 | Tensor Core GPU
- 80GB 显存。
B200 和 GB200 区别
B200 表示的单纯是 GPU,而 GB200 是芯片的“组合”,如中间图所示,是通过一个板子将 2 颗 B200 加上一颗 Grace CPU(72 核心的 ARM 架构处理器)组合而成。
AMD GPU 架构演进
RDNA:架构名字,比如 RDNA, RDNA 2, RDNA 3, RDNA 4。
架构系列:
- Vega 架构:发布于 2017 年,特点是采用高带宽缓存控制器(HBCC),以及下一代计算单元设计,支持高级图形与高性能计算任务。比如 Radeon RX Vega 64/56 显卡。
- RDNA 2/3/4 架构:2019 年推出的第一代 RDNA 架构是 GCN 架构的重大革新,旨在提供更高的能效比,并首次应用于 Radeon RX 5000 系列显卡上,如 RX 5700 XT 和 RX 5700。偏向游戏玩家。
- CDNA 架构:专注于数据中心和高性能计算市场,具备高度优化的计算性能,适用于机器学习、深度学习、科学计算等领域。
主要 GPU 产品线:
- 消费级桌面显卡: • Radeon RX 系列:例如 RX 5000 系列、RX 6000 系列等,为个人电脑玩家和内容创作者提供中高端图形处理能力。
- 移动版显卡: • Radeon RX 移动版:针对笔记本电脑市场,如 Radeon RX 5000M 系列和最新的 RX 6000M 系列,为游戏本和平板电脑提供强劲的图形性能。
- 专业显卡: • Radeon Pro WX 系列:面向专业工作站用户,如 WX 7100、WX 8200 以及基于 Vega 架构的 WX 9100 等型号,满足 CAD、渲染、建模等专业应用需求。
AMD GPU体系知识大全_vega架构和rdna架构-CSDN博客
GPU 图形渲染
着色器(Shader)
是一个软件程序,不是一个硬件单元。
顶点着色器(Vertex Shader)
像素着色器(Pixel Shader)
Nvidia Confidential Computing / GPU TEE
GPU TEE 是从 Hopper 架构才开始支持的:
NVIDIA was the first GPU to deliver Confidential Computing on the NVIDIA Hopper™ architecture with the unprecedented acceleration of NVIDIA Tensor Core GPUs. NVIDIA Blackwell architecture has taken Confidential Computing to the next level with nearly identical performance compared to unencrypted modes for large language models (LLMs)
引用自 Confidential Computing | NVIDIA
普通情况下,GPU 显存,虚拟机 guest 可以读,VMM / Host 也可以读,都是明文。
GPU TEE 之后,VMM / Host 无法读取里面内容。这种保护是通过对显存进行访问控制来实现的(显存并未加密)。Nvidia 驱动运行在 TDX 中。
开启后,GPU 显存分成两部分:
- Compute Protected Region(CPR)
- GPU Unprotected Memory
GPU TEE 和 TDXIO / TDX Connect 之间的关系
GPU TEE 保护显存数据,TDX Connect 把设备纳入 TCB,能让设备做 DMA,是正交的关系。
- TDX off & GPU TEE off;
- TDX on & GPU TEE off;
- TDX Connect off &
- TDX Connect on & GPU TEE off:虽然在 DMA 时,支持 vt-d 页表设置 key 做加解密,
两者使用需要同时打开吗?不需要。比如可以使用 GPU TEE 的同时不使用 TDX Connect。
CUDA (Compute Unified Device Architecture)
CUDA 提供了对其它编程语言的支持,如 C/C++,Python,Fortran 等语言。CUDA 程序中既包含 host 程序,又包含 device 程序,它们分别在 CPU 和 GPU 上运行。
典型的 CUDA 程序的执行流程如下:
- 分配 host 内存,并进行数据初始化;
- 分配 device 内存,并从 host 将代码和数据拷贝到 device 上。因为 CPU 本身代码数据也都位于内存中进行计算,因此 GPU 也可以根据 device 内存(显存)里的代码和数据来进行计算;
- 调用 CUDA 的核函数在 device 上完成指定的运算(应该是类似发送一个信号的方式?);
- 将 device 上的运算结果拷贝从显存拷贝到 host 内存上;
- 释放 device 和 host 上分配的内存。
一些代码在 CPU 上跑,一些代码在 GPU 上跑,需要区分 host 和 device 上的代码,在 CUDA 中是通过函数类型限定词开区别 host 和 device 上的函数,主要的三个函数类型限定词如下:
-
__global__:在 device 上执行,从 host 中调用(一些特定的 GPU 也可以从 device 上调用),返回类型必须是 void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的 kernel 是异步的,这意味着 host 不会等待 GPU 上的 kernel 执行完就执行下一步。 -
__device__:在 device 上执行,单仅可以从 device 中调用,不可以和__global__限定词同时用。 -
__host__:在 host 上执行,仅可以从 host 上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在 device 和 host 都编译。
好文精读:CUDA编程入门极简教程 - 知乎
CUDA 对 Linux 和 Windows 适配。
异构计算
要了解 CUDA,就要先明白什么是异构计算。为什么 GPU 和硬盘、网卡都是外设,那么 CPU + 硬盘或者说 CPU + 网卡就不叫异构计算,而 CPU + GPU 就叫做异构计算?
我觉的这是因为网卡/硬盘在设计之初就不是为了计算功能,而是为了其他功能(存储/网络);而 GPU,尤其是 GPGPU 在设计之初就是为了计算,就是为了卸载 CPU 的一部分的计算功能到 GPU 上,因此 CPU + GPU 叫做异构计算。
CUDA 和 GPU Driver 的区别
In the NVIDIA driver package, there is a libcuda.so.
CUDA driver is libcuda.so which is included in Nvidia driver and used by CUDA runtime api.
CUDA 测试带宽:cuda-samples/Samples/1_Utilities/bandwidthTest/bandwidthTest.cu at master · NVIDIA/cuda-samples
GPU 线程 / CUDA 线程 / CUDA Grid / CUDA Block
Grid, block 和 thread 都是一个软件概念。
Kernel 在 device 上执行时实际上是启动很多线程:
- 一个 kernel 所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间;
- Grid 是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次;
// 表示一个 grid 有 6 个 block,3 * 2 进行排列
dim3 grid(3, 2);
// 表示一个 block 有 15 个 thread,5 * 3 进行排列
dim3 block(5, 3);
// 因此,一共有多少个线程,可以通过 3 * 2 * 5 * 3 的方式计算出来
kernel_fun<<< grid, block >>>(prams...);
上面代码会生成下面这样的架构:
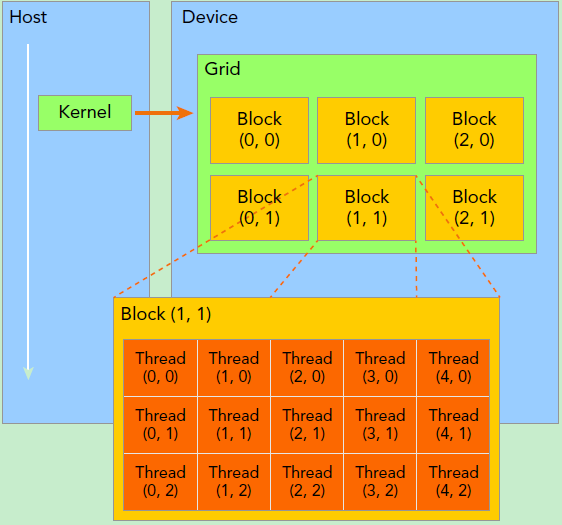
一个线程需要两个内置的坐标变量 (blockIdx, threadIdx) 来唯一标识,
CUDA kernel / Operator 算子
Kernel 是在 device 上线程中并行执行的函数。在调用时需要用 <<<grid, block>>> 来指定 kernel 要执行的线程数量,在 CUDA 中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号 thread ID,这个 ID 值可以通过核函数的内置变量 threadIdx 来获得。
算子其实是从神经网络模型架构的角度来说的,深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称 OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。再例如:tanh、ReLU 等,为在网络模型中被用做激活函数的算子。
算子其实就是一个函数。Kernel 和 Operator 可能不是一对一的关系,一个 Operator 下可能有多个 Kernel。
算子是实现在哪里?
- GPU 驱动?❌
- CUDA 驱动?❌
- 推理框架层比如 PyTorch/Tensorflow ✅
- 大模型推理服务层比如 vLLM/SGLang(也是通过 torch extension 的方式实现的算子) ✅
因此不同的推理框架里的算子实现是不一样的。
AMD ROCm
就是 AMD 版的 CUDA。
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。