k8s (Kubernetes) Overview
期望状态 spec 和实际状态 status:Kubernetes 对象 | Kubernetes
k8s 学习资料
Minikube: 可以在 MacOS 上搭建一个 k8s 集群学习。
k8s 简单架构

Running And Ready status of a Pod in k8s
Running 状态并不等同于 Ready(可能容器已启动但未通过就绪探针)。
Probe(探针)in k8s / Liveness probe(存活探针)/ readiness probe(就绪探针)/ startup probe(启动探针)
K8s 中存在三种类型的探针:liveness probe、readiness probe 和 startup 探针。每类探针都支持三种探测方法
- liveness 探针:影响的是单个容器,如果检查失败,将杀死容器,根据 pod 的 restartPolicy 来操作。
- readiness 探针:影响的是整个 pod,即如果 pod 中有多个容器,只要有一个容器的 readiness 探针诊断失败,那么整个 pod 都会处于 unready 状态。
- startup 探针:指示容器中的应用是否已经启动。如果提供了启动探针 (startup probe),则禁用所有其他探针,直到它成功为止。如果启动探针失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探针,则默认状态为成功 Success。
apiVersion In k8s
PV / PVC in k8s
PersistenVolume and PersistenVolumeClaim.
持久卷(PersistentVolume,PV)是集群中由管理员配置的一段网络存储。它是集群中的资源,就像节点是集群资源一样。
PV 拥有独立于任何使用 PV 的 Pod 的生命周期。
持久卷申领(PersistentVolumeClaim,PVC)表达的是用户对存储的请求。概念上与 Pod 类似。
- Pod 会耗用 node 资源,Pod 可以请求特定数量的资源(CPU 和内存)。
- 而 PVC 申领会耗用 PV 资源。PVC 申领也可以请求特定的大小和访问模式。
- 挂载:在 Pod 或 Deployment 的 YAML 配置文件中,定义 volumes 字段并引用上面创建的 PVC,然后在 volumeMounts 字段中指定挂载到容器内部的目录路径。
多个机器可以同时绑定同一个 PVC 吗?
查看一个 Pod 所绑定的所有 PVC:
kubectl describe pod <pod-name> -n <namespace>
找到如下的字段:
Volumes:
my-pvc-volume: # 卷名称
Type: PersistentVolumeClaim
ClaimName: my-pvc # 关联的 PVC 名称
ReadOnly: false
分析卡 terminating 的原因
GVK
在 Kubernetes 中,GVK 是指 Group、Version 和 Kind 三个字段,用于唯一标识 Kubernetes 资源对象。
- Group 指的是 Kubernetes API 中的资源组,例如 apps、batch、core 等。
- Version 指的是资源对象的 API 版本,例如 v1、v1beta1、v2alpha1 等。
- Kind 指的是资源对象的类型,例如 Pod、Service、Deployment 等。
在 Kubernetes 中,所有的资源对象都必须要有一个 GVK,以便于 Kubernetes 控制器进行操作和管理。一个 GVK 其实就表示了一个 resource,而一个具体的 object(比如说一个具体的 Pod)其实就是一个 GVK 模版(resource)的实例化。
Controller manager in k8s
指的应该是 controller manager,也就是说管理所有 controller 的那个组件。
Kubernetes 控制器管理器是一个守护进程,内嵌随 Kubernetes 一起发布的核心控制回路。 在机器人和自动化的应用中,控制回路是一个永不休止的循环,用于调节系统状态。 在 Kubernetes 中,每个控制器是一个控制回路,通过 API 服务器监视集群的共享状态, 并尝试进行更改以将当前状态转为期望状态。 目前,Kubernetes 自带的控制器例子包括副本控制器、节点控制器、命名空间控制器和服务账号控制器等。
每个 Operator 通常部署 1 个 Manager。
管理一组控制器的启动、停止和协同工作。
一个系统可以有几个 manager?
kube-controller-manager | Kubernetes
Scheme in k8s
如上,一个 GVK 和一个 Resource 是关联的。但是 go 里的结构体也需要和一个 GVK 来关联。一个 Scheme 实例本质上是一个类型注册表,内部维护以下关键映射关系:
type Scheme struct {
// GVK → Go 类型
gvkToType map[schema.GroupVersionKind]reflect.Type
// Go 类型 → 可能的 GVK 列表(一个类型可能适用于多个版本)
typeToGVK map[reflect.Type][]schema.GroupVersionKind
// 类型转换函数(用于版本转换,将一个版本的 Go 类型转换成为另一个版本的 Go 类型)
converters map[typePair]TypeConverter
}
Object Names and UIDs/UUIDs in k8s
Each object in your cluster has a Name that is unique for that type of resource. Every Kubernetes object also has a UID that is unique across your whole cluster.
For example, you can only have one Pod named myapp-1234 within the same namespace, but you can have one Pod and one Deployment that are each named myapp-1234.
名字可以重,只要用 namespace 区分就行,UID 不可以。一般 k get po 指定的是 name 而不是 uid。
For non-unique user-provided attributes, Kubernetes provides labels and annotations.
Pod Pending 状态原因
List all pods under a workload in k8s
There's a label in the pod for the selector in the deployment. That's how a deployment manages its pods. For example for the label or selector app=http-svc you can do something like that this and avoid using grep and listing all the pods (this becomes useful as your number of pods becomes very large):
# single label
kubectl get pods -l=app=morphling-system
kubectl get pods --selector=app=http-svc
# multiple labels
kubectl get pods --selector key1=value1,key2=value2
Kubectl command to list pods of a deployment in Kubernetes - Stack Overflow
Objects in k8s / Spec / Status
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster.
A Kubernetes object is a "record of intent"--once you create the object, the Kubernetes system will constantly work to ensure that the object exists. By creating an object, you're effectively telling the Kubernetes system what you want your cluster's workload to look like; this is your cluster's desired state.
Object 看起来描述了期望的状态。从面向对象的角度来说,Object 是资源的具体实例,比如 Pod 是资源,但是一个具体的 Pod 就是对象,对象通过 metadata.name 和 metadata.namespace 唯一标识。
Spec 和 Status 也就是期望状态和实际状态:Kubernetes 对象 | Kubernetes 都是 Object 所有的属性。
Kind in k8s, resource in k8s, resource type / k8s 资源文件放在哪里
从面向对象的角度来说,Kind 其实就是一个类,用于描述对象的;而 Resource 就是具体的 Kind,可以理解成类已经实例化成对象了。
k8s 把所有的东西都抽象成了资源,比如说一个 pod,一个 workload,等等,我们可以通过 k get 来换取一个资源的定义的 yaml。
Note that, in general and informally we're using the terms resources and objects interchangeably and that's totally fine. Unless you're a Go developer, extending Kubernetes, you probably don't need to bother at all.
Difference between Kubernetes Objects and Resources - Stack Overflow
在一个资源的定义文件中,我们可以看到这个资源的类型是什么。
kind: Pod
一个资源是有自己的标识的,比如说 ump2-fb4cb4c4-4295-4980-81d7-ca2d9d8b9a47,唯一标识了一个资源。
A resource is part of a declarative API, used by Kubernetes client libraries and CLIs, or kubectl.
It can lead to "custom resource", an extension of the Kubernetes API that is not necessarily available in a default Kubernetes installation.
Resource type 有:k8s workloads refer to the various types of resources, such as Pods, Deployments, StatefulSets, DaemonSets, and Jobs.
k8s Object 之间的嵌套关系 / ownerReferences
子对象通过 metadata.ownerReferences 字段声明父对象,实现级联删除和状态同步,但父对象不直接包含子对象。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
ownerReferences: # 声明父对象为 ReplicaSet 类型的 my-rs 对象
- apiVersion: apps/v1
kind: ReplicaSet
name: my-rs
uid: 12345-abcde
spec:
containers: [...]
比如一个 Pod resource。
如果下面这个被置上了:
Owner References:
Block Owner Deletion: true
那么这个资源会 block 其父资源的删除(如果要删除父资源而子资源还没有被删除,那么父资源也不会被删除)。
k8s Resource 和 object 之间的关系
![[k8s_resource_and_object.excalidraw]]
我们知道 Pod 等等 resource 是可以有自己的 object,那么其他类型的资源呢?比如说一个 Deployment,可以有自己的一个 object 吗?当然是可以的:
- Deployment 资源:可以创建
deploy-app、deploy-db等对象。 - Service 资源:可以创建
frontend-svc、backend-svc等对象。
极少数资源类型可能设计为单例模式。
对象之间是可以进行级联的,比如说子对象可以通过 ownerReferences^ 的形式指定自己的父对象。属主与附属 | Kubernetes
暂时没有看到资源之间有什么关系(一个资源作为另一个资源的对象等),资源可以作为另一种资源的对象吗?不可以,应该说只能作为 CRD 资源的对象。
- CRD 可以理解成元类,其创建的对象是资源(比如我们可以通过 CRD 定义一个 pod 出来:指定
Kind: CRD); - 资源可以理解为类,可以创建出对象(指定
Kind: Pod)。
容器里的业务是如何看到自己的 CPU Core 数量的?
Cluster in k8s
一组运行容器化应用程序的计算节点或工作机,看起来应该是物理机 nodes 的集合。
A Kubernetes cluster consists of a control plane plus a set of worker machines, called nodes, that run containerized applications.
Namespace in k8s
在 Kubernetes 中,名字空间(Namespace) 提供一种机制,将同一集群中的资源划分为相互隔离的组。
名字空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑名字空间。可以隔离哪些资源?
如何删除一个 namespace:
Annotations in k8s
You can use Kubernetes annotations to attach arbitrary non-identifying metadata to objects. Clients such as tools and libraries can retrieve this metadata.
Annotation 和 Label 的区别:You can use either labels or annotations to attach metadata to Kubernetes objects. Labels can be used to select objects and to find collections of objects that satisfy certain conditions. In contrast, annotations are not used to identify and select objects.
Label in k8s
Labels 是附加到 Kubernetes 对象(比如 Pod)上的键值对。 标签旨在用于指定对用户有意义且相关的对象的标识属性,但不直接对核心系统有语义含义。 标签可以用于组织和选择对象的子集。标签可以在创建时附加到对象,随后可以随时添加和修改。 每个对象都可以定义一组键/值标签。每个键对于给定对象必须是唯一的。
kubeconfig
Kubernetes components like kubelet, kube-controller-manager, or kubectl use the kubeconfig file to interact with the Kubernetes API.
主要就是 client 端通过 kubectl 连接其他
The kubeconfig file is a YAML file containing groups of clusters, users, and contexts. 一个例子:
apiVersion: v1
kind: Config
clusters:
- name: minikube
cluster:
certificate-authority: /home/hector/.minikube/ca.crt
server: https://192.168.39.217:8443
users:
- name: minikube
user:
client-certificate: /home/hector/.minikube/profiles/minikube/client.crt
client-key: /home/hector/.minikube/profiles/minikube/client.key
contexts:
- name: minikube
context:
cluster: minikube
namespace: default
user: minikube
current-context: minikube
k8s 强行删除一个卡 terminating 的 Object
主要参考下面的命令(crd 可以替换成其他类型,比如说 pod, deploy 等等):
kubectl patch crd/此处写CRD的名字 -p '{"metadata":{"finalizers":[]}}' --type=merge
# 举个例子,可以在
kubectl delete crd profilingexperiments.morphling.kubedl.io samplings.morphling.kubedl.io trials.morphling.kubedl.io
# 之后
kubectl patch crd/trials.morphling.kubedl.io -p '{"metadata":{"finalizers":[]}}' --type=merge
patch trial.morphling.kubedl.io/test-tpp-5xtw97mr -p '{"metadata":{"finalizers":[]}}' --type=merge
感谢这篇文章:强制删除k8s Terminating 资源小技巧 - 亚里士多智 - 博客园
Delete a namespace in k8s
kubectl delete namespace morphling-system
Kubectl
普通语法:命令行工具 (kubectl) | Kubernetes
可以在这里看到所有的 k8s 命令:Kubernetes 备忘清单 & kubernetes cheatsheet & Quick Reference
# po 就是 pods 的缩写
k get po
k8s 找到一个 namespace 下面的所有的资源 / api-resources
# 先拿到整个系统的所有资源类型,然后按每一种资源找到 morphling-system 这个 namespace 下面的所有 object
kubectl api-resources -o name --verbs=list --namespaced | xargs -n 1 kubectl get --show-kind --ignore-not-found -n morphling-system
注意上面的输出形式都是类似 deployments.apps 这种形式,和真正的 get -oyaml 里的输出还是不太一样的。区别在于:
- 资源类型以
<简称>.<API 组>的形式显示(例如deployments.apps)。 - 复数形式 vs. 单数首字母大写的 kind:
services/Service - deployments 是复数形式,.apps 表示所属 API 组:
deployments.apps/Deployment
和下面这种方式有什么区别呢?
kubectl get all --namespace=morphling-system
"all" 是预定义的资源类别:它仅列出 Kubernetes 官方定义的“核心常见资源”,不包含 CRDs 以及其他的非核心资源。
Slices in k8s
Generally on the Kubernetes node there are three cgroups under the root cgroup, named as slices:
system.sliceuser.slicekubepods
The last one, kubepods is created by k8s to allocate the resource to pods.
In kubepods directory we can find two other folders - besteffort and burstable. Here is worth mentioning that Kubernetes have a three QoS classes:
GuaranteedBurstableBestEffort
Each pod has an assigned QoS class and depending on which class it is, the pod is located in the corresponding directory (except guaranteed, pod with this class is created in kubepods directory).
Sidecar 容器
通常,一个 Pod 中只有一个应用容器。边车容器是与主应用容器在同一个 Pod 中运行的辅助容器。
Pod
Pod 是对一组紧密关联容器以及他们之间关系的定义,Pod 之间的关系其实很像 docker-compose,可以说就是 k8s 的 docker-compose。甚至有一个工具 Kompose 都能专门把 docker-compose 文件转换成为多个 Pod 的定义文件。 一个 Pod 不能对应上一个 docker-compose,这是因为 Pod 设计主要是为了扩缩容,我们扩容业务容器其实没有必要扩容数据库容器。
A Pod (as in a pod of whales or pea pod) is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. A Pod's contents are always co-located and co-scheduled, and run in a shared context. A Pod models an application-specific "logical host": it contains one or more application containers which are relatively tightly coupled. In non-cloud contexts, applications executed on the same physical or virtual machine are analogous to cloud applications executed on the same logical host (pod).
In Kubernetes, a Pod represents a set of running containers on your cluster.
每一个 pod 里的每一个 container 都可以有自己的 request 和 limit。不论是 CPU 还是 memory,很简单,一个是上界,一个是下界。
- 可以看到 CPU 不只是一个一个分配,也可以是按照时间比如 500m 来分配的,500m 表示 500 milicore 也就是 0.5 core。那么如果请求是 1,是会就是 set 到一个核上还是说十个核上每一个核的 quota 是 0.1?
- Pod 默认就是 CPU Share 化的吗?
kind: Deployment
apiVersion: extensions/v1beta1
…
template:
spec:
containers:
- name: redis
image: redis:5.0.3-alpine
resources:
limits:
memory: 600Mi
cpu: 1
requests:
memory: 300Mi
cpu: 500m
- name: busybox
image: busybox:1.28
resources:
limits:
memory: 200Mi
cpu: 300m
requests:
memory: 100Mi
cpu: 100m
Request 和 limit 是如何在 cgroup 中被保证的?
request 是如何保证的,可能就是 k8s 不超卖调度来保证? 这个问题可以回答 k8s 是如何保证资源的下限的,也就是 request。其实这个问题可以转化成,k8s 保证的是一个绝对值,比如说 200m 就表示五分之一的 CPU 时间,但是 kernel cgroup 的配置面并没有这种保证,cpu.shares 是相对其他 cgroup 的,即使你设置 1024,如果跑在同一个核上的另一个 cgroup 也设置了 1024,那么其实你也只能占用半个核,这个资源下限是没有办法保证的,所以我觉得就是通过 k8s 不超卖来保证。
cpu - What is the Exact use of requests in Kubernetes - Stack Overflow
cpu.shares 对应 k8s 内的 resources.requests.cpu 字段:值对应关系为:resources.requests.cpu * 1024 = cpu.shares。
cpu.cfs_period_us、cpu.cfs_quota_us 对应 k8s 中的 resources.limits.cpu 字段:
resources.limits.cpu = cpu.cfs_quota_us/cpu.cfs_period_us
quota/period 对应 limit 保证了上限,cpu.shares 对应 request 保证了下限。
Node on k8s
A Kubernetes node is either a virtual or physical machine that one or more pods run on.
QoS 资源类型
Guaranteed 、 Burstable 和 BestEffort。
- Guaranteed:有特定的资源配给,也就是资源上界 == 资源下界,资源紧张时最后被剥夺资源。
- Burstable Pod:有下界没上界,资源紧张时次优先被剥夺资源。
- BestEffort:没有上下界,资源紧张时优先被剥夺资源。
Guaranteed Pod 具有最严格的资源限制,并且最不可能面临驱逐。 在这些 Pod 超过其自身的限制或者没有可以从 Node 抢占的低优先级 Pod 之前, 这些 Pod 保证不会被杀死。这些 Pod 不可以获得超出其指定 limit 的资源。这些 Pod 也可以使用 static CPU 管理策略来使用独占的 CPU。
Pod 被赋予 Guaranteed QoS 类的几个判据:
- Pod 中的每个容器必须有内存 limit 和内存 request。
- 对于 Pod 中的每个容器,内存 limit 必须等于内存 request。
- Pod 中的每个容器必须有 CPU limit 和 CPU request。
- 对于 Pod 中的每个容器,CPU limit 必须等于 CPU request。
Burstable Pod 有一些基于 request 的资源下限保证,但不需要特定的 limit。 如果未指定 limit,则默认为其 limit 等于 Node 容量,这允许 Pod 在资源可用时灵活地增加其资源。 在由于 Node 资源压力导致 Pod 被驱逐的情况下,只有在所有 BestEffort Pod 被驱逐后这些 Pod 才会被驱逐。因为 Burstable Pod 可以包括没有资源 limit 或资源 request 的容器, 所以 Burstable Pod 可以尝试使用任意数量的节点资源。
Pod 被赋予 Burstable QoS 类的几个判据:
- Pod 不满足针对 QoS 类 Guaranteed 的判据。
- Pod 中至少一个容器有内存或 CPU 的 request 或 limit。
BestEffort QoS 类中的 Pod 可以使用未专门分配给其他 QoS 类中的 Pod 的节点资源。 例如若你有一个节点有 16 核 CPU 可供 kubelet 使用,并且你将 4 核 CPU 分配给一个 Guaranteed Pod, 那么 BestEffort QoS 类中的 Pod 可以尝试任意使用剩余的 12 核 CPU。
如果节点遇到资源压力,kubelet 将优先驱逐 BestEffort Pod。
只有当 Pod 中的所有容器没有内存 limit 或内存 request,也没有 CPU limit 或 CPU request 时,Pod 才是 BestEffort。Pod 中的容器可以请求(除 CPU 或内存之外的) 其他资源并且仍然被归类为 BestEffort。
Event in k8s
对资源的创建、更新、删除的动作都会被称为为事件(Event)。
Taint and Toleration in k8s
- Taint 是 Node 的属性;
- Toleration 是 Pod 的属性。
亲和性调度可以使得我们的 Pod 调度到指定的 Node 节点上,而污点(Taints)与之相反,它可以让 Node 拒绝 Pod 的运行,甚至驱逐已经在该 Node 上运行的 Pod。
污点是 Node 上设置的一个属性,通常设置污点表示该节点有问题,比如磁盘要满了,资源不足,或者该 Node 正在升级暂时不能提供使用等情况,这时不希望再有新的 Pod 进来,这个时候就可以给该节点设置一个污点。
一个污点的完整定义:key=value:Effect。对于 Effect,请看单独笔记。Effect 是必填字段。
但是有的时候其实 Node 节点并没有故障,只是不想让一些 Pod 调度进来,比如这台节点磁盘空间比较大,希望是像 Elasticsearch、Minio 这样需要较大磁盘空间的 Pod 才调度进来,那么就可以给节点设置一个污点,给 Pod 设置容忍(Tolerations)对应污点,如果再配合节点亲和性功能还可以达到独占节点的效果。
只要一个 node 配置了污点,那么对于所有的 pod ,如果这个 pod 想要调度到对应 node 上就必须要配置对应的 toleration 才可以吗?
是的,如果一个节点被配置了污点(Taint),那么任何未明确配置对应容忍(Toleration)的 Pod 都无法调度到该节点上。这是 Kubernetes 污点(Taint)和容忍(Toleration)机制的核心规则。
关键规则:
- 默认排斥:
- 节点上的污点会排斥所有 Pod,除非 Pod 显式声明了匹配的容忍(Toleration)。
- 例如,若节点污点为 key=value:NoSchedule,Pod 必须配置完全匹配 key=value 和 effect=NoSchedule 的容忍才能调度(除非使用 operator: Exists)。
- 污点效果(Effect)的影响:
- NoSchedule:Pod 必须配置容忍才能调度到节点。
- PreferNoSchedule:K8s 会尽量避免调度 Pod 到此节点,但不强制阻止。
- NoExecute:不仅阻止调度,还会驱逐节点上已有的未容忍此污点的 Pod。
例外情况:以下情况即使存在污点,Pod 可能无需配置容忍也能调度:
- Kubernetes 系统组件自动容忍:系统级 Pod(如 kube-apiserver、kube-scheduler)默认容忍 node-role.kubernetes.io/master:NoSchedule 等污点,以确保关键组件能调度到 Master 节点。
- 特定 Operator 配置:
Taint Effect in k8s
定义了节点污点对 Pod 调度和运行的具体影响方式,决定两件事:
- 何时阻止 Pod 调度到节点;
- 是否驱逐已有 Pod?
k8s 支持三种类型 Effect:
- NoSchedule(最严格):
- 如果 Pod 未配置匹配的容忍(Toleration),完全禁止调度到该节点。
- 已有不会被驱逐。
- PreferNoSchedule:
- 尽量避免将其调度到此节点,但不强制阻止。
- 已有的 Pod 不受影响。
- NoExecute(最激进):
- 禁止调度到该节点。
- 根据 tolerationSeconds 设置决定是否被驱逐,如果 pod 设置了那么超时后驱逐,如果没有配置,立即驱逐。
Operator in k8s
Operator 是一种 kubernetes 的扩展形式,可以帮助用户以 Kubernetes 的声明式 API 风格自定义来管理应用及服务,operator 已经成为分布式应用在 k8s 集群部署的事实标准了。
WorkloadSpread 就是一种 operator。
operator 主要是为解决特定应用或服务关于如何运行、部署及出现问题时如何处理提供的一种特定的自定义方式。比如:
- 按需部署应用服务(总不能用一大堆 configmap 来管理吧,也会很混乱);
- 实现应用状态的备份和还原,完成版本升级;
- 数据库 schema 或额外的配置设置的改动;
- 为分布式应用进行 master 选举,例如 etcd,或者 master-slave 架构的 mysql 集群。
分为三部分,CRD, controller, webhook。
可以为不同的应用编写 operator,这里可以看到许多别人编写的 operator:OperatorHub.io | The registry for Kubernetes Operators
如果要开发 operator,有很多工具(下面只列我用过的):
十分钟弄懂 k8s Operator 应用的制作流程 - 知乎
CRD (Custom Resource Definition)
从 Kubernetes 的用户角度来看,所有东西都叫资源 Resource,资源有很多不同的种类,就是 yaml 里的字段 Kind 的内容,例如 Service、Deployment 等。除了常见内置资源之外,Kubernetes 允许用户自定义资源 Custom Resource,而 CRD 表示自定义资源的定义。
于 CRD 对象所创建的自定义资源可以是名字空间作用域的,也可以是集群作用域的, 取决于 CRD 对象 spec.scope 字段的设置。很多 Kubernetes 核心功能现在都用定制资源来实现,这使得 Kubernetes 更加模块化。
CRD 是通过 controller 来发生作用的。比如说 Pod 是一个 resource,有自己默认的 controller,其控制了作为一个 pod 的行为方式,比如拉起容器什么的。但是 CRD 作为自定义的 resource controller 需要自己来定义。
Controller in k8s
In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state.
所以像空调,就是逐渐把整个集群的状态向 spec 里定义的状态靠拢。在 k8s 中,Controller 是一个重要的组件,它可以根据我们的期望状态和实际状态来进行调谐,以确保我们的应用程序始终处于所需的状态。
Kubernetes 的 Controller Manager 负责 Event^ 监听,并触发相应的动作来满足期望(Spec),这种方式也就是声明式。
和 Resource 的关系:A controller tracks at least one Kubernetes resource type. These objects have a spec field that represents the desired state. The controller(s) for that resource are responsible for making the current state come closer to that desired state.
Controller 在系统中也是以一个 pod 的形式运行的:
WebHook in k8s
在 k8s 里主要是用来做准入控制。
是 web 里的概念,不是 k8s 才有的概念。Webhook 就是一种 HTTP 回调,用于在某种情况下执行某些动作,Webhook 不是 K8S 独有的,很多场景下都可以进行 Webhook,比如在提交完代码后调用一个 Webhook 自动构建 docker 镜像。
- 在资源持久化到 ETCD 之前进行修改(Mutating Webhook),比如增加 init Container 或者 sidecar Container
- 在资源持久化到 ETCD 之前进行校验(Validating Webhook),不满足条件的资源直接拒绝并给出相应信息
现在非常火热的的 Service Mesh 应用 istio 就是通过 mutating webhooks 来自动将 Envoy 这个 sidecar 容器注入到 Pod 中去的:https://istio.io/docs/setup/kubernetes/sidecar-injection/。
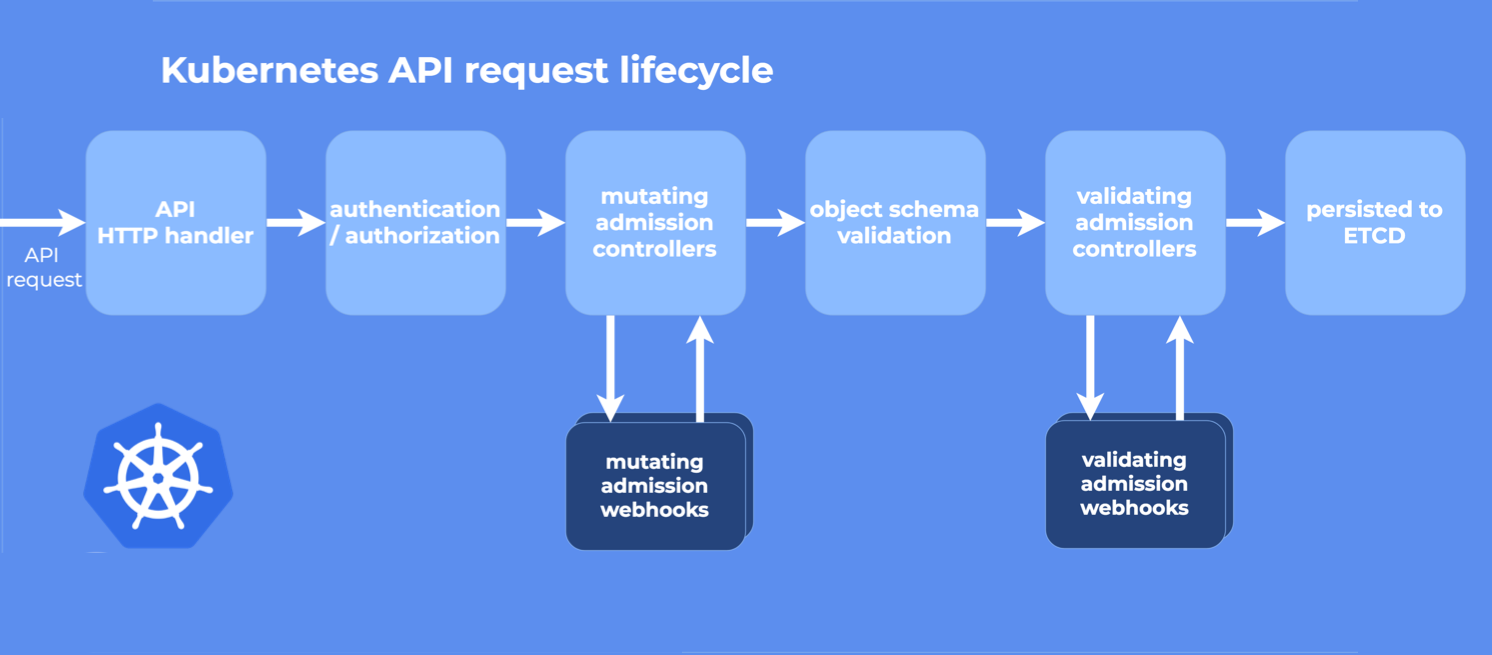
从图中可以看到,先执行的是 Mutating Webhook,它可以对资源进行修改,然后执行的是 Validating Webhook,它可以拒绝或者接受请求,但是它不能修改请求。
kubernetes的webhook开发 - 我给你一个大大的Yes - 博客园
Service in k8s / Selector in k8s
注意 k8s 中的 Service 并不是 workload 的一种,也就是和 Deployment, StatefulSets 什么的并不是一个并行的关系。
Service 是 Kubernetes 中用于网络抽象和服务发现的资源,为 Pod 提供稳定的访问入口。
Service 不运行容器,仅配置网络规则,提供 Pod 的网络访问入口和负载均衡,依赖 Pod(通过标签选择器关联)。
你可能好奇,如何知道一个 Deployment 的工作负载是如何对应到其所管理的所有 pod 的呢?就是通过 Selector。Selector 通过标签 label 匹配目标资源(如 Service 关联 Pod、Deployment 管理 Pod)。实现资源之间的逻辑绑定。允许在运行时通过更新标签动态调整资源关系。
# Workload(Deployment):定义应用 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
---
# Service:暴露 Deployment 的 Pod
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx # 关联 Deployment 的 Pod 标签
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
Workload in k8s
A workload is an application running on Kubernetes. Whether your workload is a single component or several that work together, on Kubernetes you run it inside a set of pods.
一个应用如果访问很多,需要分布式,因此一个 pod 可能是不够的,所以我们有了 Workload 的概念,对应于多个跑着相同内容的 pod。
Deployment 无状态负载
Deployment 适用于对数据持久化和请求顺序不敏感的场景,例如 Web 服务器、微服务架构服务等,也就是 stateless 的。
StatefulSets 有状态应用
StatefulSet 运行一组 Pod,并为每个 Pod 保留一个稳定的标识。 这可用于管理需要持久化存储或稳定、唯一网络标识的应用。
在 Deployment 中,每个 Pod 都是独立且无状态的,不存在相互依赖关系。但在某些场景中,Deployment 控制器并不能满足需求,例如在分布式数据库场景中,Pod 之间存在状态信息和依赖关系,例如主备模式。这种情况下,使用 StatefulSet 能够更有效地管理有状态且互相关联的 Pod。
StatefulSet 适用于需要持久化存储和有序部署实例的场景,例如数据库、分布式存储系统等。
每个 Pod 拥有独立持久化存储卷声明和固定命名,确保数据持久性和一致性。当 Pod 重启或重新调度时持久化存储保持不变。
Pod 拥有固定标识其格式为 <StatefulSet 名>-<序号>,例如 web-0、web-1 等。当 Pod 发生重启,其名称也不会改变。
controller-runtime / k8s Operator 开发
controller-runtime 框架实际上是社区帮我们封装的一个控制器处理的框架,底层核心实现原理和我们前面去自定义一个 controller 控制器逻辑是一样的,只是在这个基础上新增了一些概念,开发者直接使用这个框架去开发控制器会更加简单方便。包括 kubebuilder、operator-sdk 这些框架其实都是在 controller-runtime 基础上做了一层封装,方便开发者快速生成项目的脚手架而已(It is leveraged by Kubebuilder and Operator SDK)。
所有的子 packages 都可以在这里看到:pkg package - sigs.k8s.io/controller-runtime/pkg - Go Packages
sigs.k8s.io/controller-runtime/pkg/reconcile
有一个案例库可以学习:kubedl-io/morphling: Automatic tuning for ML model deployment on Kubernetes
client.Client
对于集群的所有操作的真正的更新都是通过 client 来做的,比如说:
type Client interface {
// 读集群中的数据,比如说 Get, List 函数定义在这里
Reader
// Create(), Delete(), Update(), Patch(), DeleteAllOf()
Writer
// 获取当前状态:Status()
StatusClient
}
k8s Controller 劫持
或许有参考?在本地调试基于 controller-runtime 的 webhook | Laminar
Manager in k8s controller-runtime
Manager is required to create controllers and provide shared dependencies such as clients, caches, schemes, etc.
k8s 开发 API
ConditionStatus
通常用于描述资源的特定条件状态,比如 "True", "False", "Unknown"。例如,像 Pod 的 Ready 条件,或者 Deployment 的 Available 状态都使用这个类型。
典型场景:
- 检查资源状态
- 更新资源的条件状态
- …
corev1
struct Node
type Node struct {
//...
Spec NodeSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
//...
Status NodeStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
struct StatefulSet
你看,每一种资源都有自己的 Spec 和 Status。
type StatefulSet struct {
//...
Spec StatefulSetSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status StatefulSetStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
struct NodeStatus
type NodeStatus struct {
// 每一个资源的大小
Capacity ResourceList `json:"capacity,omitempty" protobuf:"bytes,1,rep,name=capacity,casttype=ResourceList,castkey=ResourceName"`
// 每一个资源剩余大小
Allocatable ResourceList `json:"allocatable,omitempty" protobuf:"bytes,2,rep,name=allocatable,casttype=ResourceList,castkey=ResourceName"`
// NodePhase is the recently observed lifecycle phase of the node.
// More info: https://kubernetes.io/docs/concepts/nodes/node/#phase
// The field is never populated, and now is deprecated.
// +optional
Phase NodePhase `json:"phase,omitempty" protobuf:"bytes,3,opt,name=phase,casttype=NodePhase"`
// Conditions is an array of current observed node conditions.
// More info: https://kubernetes.io/docs/concepts/nodes/node/#condition
// +optional
// +patchMergeKey=type
// +patchStrategy=merge
Conditions []NodeCondition `json:"conditions,omitempty" patchStrategy:"merge" patchMergeKey:"type" protobuf:"bytes,4,rep,name=conditions"`
// List of addresses reachable to the node.
// Queried from cloud provider, if available.
// More info: https://kubernetes.io/docs/concepts/nodes/node/#addresses
// Note: This field is declared as mergeable, but the merge key is not sufficiently
// unique, which can cause data corruption when it is merged. Callers should instead
// use a full-replacement patch. See http://pr.k8s.io/79391 for an example.
// +optional
// +patchMergeKey=type
// +patchStrategy=merge
Addresses []NodeAddress `json:"addresses,omitempty" patchStrategy:"merge" patchMergeKey:"type" protobuf:"bytes,5,rep,name=addresses"`
// Endpoints of daemons running on the Node.
// +optional
DaemonEndpoints NodeDaemonEndpoints `json:"daemonEndpoints,omitempty" protobuf:"bytes,6,opt,name=daemonEndpoints"`
// Set of ids/uuids to uniquely identify the node.
// More info: https://kubernetes.io/docs/concepts/nodes/node/#info
// +optional
NodeInfo NodeSystemInfo `json:"nodeInfo,omitempty" protobuf:"bytes,7,opt,name=nodeInfo"`
// List of container images on this node
// +optional
Images []ContainerImage `json:"images,omitempty" protobuf:"bytes,8,rep,name=images"`
// List of attachable volumes in use (mounted) by the node.
// +optional
VolumesInUse []UniqueVolumeName `json:"volumesInUse,omitempty" protobuf:"bytes,9,rep,name=volumesInUse"`
// List of volumes that are attached to the node.
// +optional
VolumesAttached []AttachedVolume `json:"volumesAttached,omitempty" protobuf:"bytes,10,rep,name=volumesAttached"`
// Status of the config assigned to the node via the dynamic Kubelet config feature.
// +optional
Config *NodeConfigStatus `json:"config,omitempty" protobuf:"bytes,11,opt,name=config"`
}
struct ResourceList
一个 map,从 resource name map 到剩余资源的 Quantity。
OpenKruise
OpenKruise 提供的绝大部能力都是基于 CRD 扩展来定义的,它们不存在于任何外部依赖。
WorkloadSpread
WorkloadSpread can distribute Pods of workload to different types of Node according to some polices.
WorkloadSpread 就是 OpenKruise 提供的一种 CRD。所有 OpenKruise 的功能都是通过 kubernetes CRD 来提供的。
WorkloadSpread 和 StatefulSet 的区别是,后者是一个 workload,而前者是一种 CRD,定义了如何进行部署。
Subset in WorkloadSpread
Each WorkloadSpread defines multi-domain called subset. Each domain may provide the limit to run the replicas number of pods called maxReplicas.
看下面这个就知道 subset 是什么意思了:可以看到它定义了两个 subset,每一个 subset 有不同的 node 池。这种对 node 分池的操作能够让调度变得更加灵活。
apiVersion: apps.kruise.io/v1alpha1
kind: WorkloadSpread
metadata:
name: workloadspread-demo
spec:
targetRef:
apiVersion: apps/v1 | apps.kruise.io/v1alpha1
kind: Deployment | CloneSet
name: workload-xxx
subsets:
- name: subset-a
requiredNodeSelectorTerm:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- zone-a
preferredNodeSelectorTerms:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
maxReplicas: 3
tolerations: [ ]
patch:
metadata:
labels:
xxx-specific-label: xxx
- name: subset-b
requiredNodeSelectorTerm:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- zone-b
scheduleStrategy:
type: Adaptive | Fixed
adaptive:
rescheduleCriticalSeconds: 30
Kustomize
原来是一个工具,现在已经在命令行里了:Now, built into kubectl as apply -k。
相比于传统方式,直接变成声明式了。允许用户自定义 Kubernetes 资源配置,而无需直接修改原始的 YAML 文件。
kustomization.yaml
Kustomize is a standalone tool to customize Kubernetes objects through a kustomization file.
Kustomization 也是一种 CRD 定义的资源类型。
Helm Charts
Helm 是 k8s 的包管理工具,那 Helm Chart 应该是用来打包和部署应用的。
一个应用被称为一个 chart,可以在这里看到所有的 charts:Artifact Hub。
k8s Package / k8s 包
所以首先要明白 k8s 为什么需要有包的概念,他不就是一个调度系统吗?
原生 YAML 的缺陷:
- 重复配置:多环境(开发/生产)需维护大量相似的 YAML 文件。
- 缺乏依赖管理:部署一个应用时,需手动处理其依赖(如数据库、中间件)。
- 版本控制困难:YAML 文件本身无版本化机制,回滚复杂。
Kubernetes 的“包”(如 Helm Chart):
- 封装应用:将多个 k8s 资源(Deployment、Service 等)打包成一个逻辑单元。
- 参数化配置:通过变量动态生成 YAML,避免硬编码。
- 依赖声明:例如,部署 WordPress 时自动安装 MySQL。
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。