锁
无论什么锁(互斥锁、自旋锁等等),对于用户的接口都是差不多的,都是为了保护临界区(可以把锁理解成为内存墙一样的东西):
lock()
//...
unlock()
天然原子的操作:
- 读操作,比如
print(a); - 写操作,比如
a = 5;
不原子的操作:
- 读加写,比如
a = a + 1。
futex()
是很底层的功能,可以构建更高等级更抽象的锁,比如互斥量,条件变量,读写锁,barriers 和信号量。因此,绝大多数程序都不会直接用到 futexes,而是使用一些系统类库提供的方法。 直接使用 futex 是很难用的,很多时候需要使用汇编。可以使用系统提供的 API 调用。
一个 futex 可以认定为一块内存,在进程或线程之间是共享的。在不同的进程之间,futex 不需要必须地址完全一样。本质上来说,futex 就像信号量一样,它是一个计数器,可以增加,也可以减少,进程需要一直等待,直到计数器的值变成了正数。
Futex 在整个用户层的操作都是非竞争性的。所有竞争性的判断都有内核完成。
从本质上来说,futex 就相当于一个始终保持一致性的整数,它只能通过原子性的汇编操作。进程可以使用 mmap,通过共享内存片段或是共享内存空间,在多线程之间共享它。
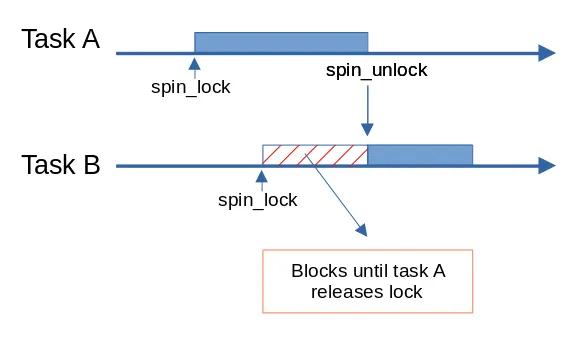
Spinlock
How does userspace use spinlock?
Spinlock 一般是实现在内核态还是用户态?
自旋锁(Spinlock)一般是实现在内核态,而不是用户态。
和原子变量的区别,请看原子变量^。
Linux 中主要有两种同步锁,一种是 spinlock,一种是 mutex。spinlock 和 mutex 的区别:spinlock 不会导致睡眠和调度,属于 busy wait 形式的锁,而后者可能导致睡眠和调度,属于 sleep wait 形式的锁。
spinlock 是最基础的一种锁,rwlock(读写锁),seqlock 等都是基于 spinlock 衍生出来的。就算是 mutex,它的实现与 spinlock 也是密不可分。
Linux kernel 的 spinlock 底层都是基于 queue spin lock 实现的。
先看看怎么用(使用 API):
static DEFINE_SPINLOCK(xxx_lock);
unsigned long flags;
// 可替换成 spin_lock_irq(), spin_lock()
spin_lock_irqsave(&xxx_lock, flags);
... critical section here ..
// 可替换成 spin_unlock_irq(), spin_unlock()
spin_unlock_irqrestore(&xxx_lock, flags);
spin_lock_irq(), spin_lock_irqsave(), spin_lock() 三者区别是什么?
spin_lock() 和 spin_lock_irq() 的区别仅仅在于,是否调用 local_irq_disable() 函数。即是否关中断。
在任何情况下使用 spin_lock_irq() 都是安全的。因为它既关中断,又关内核抢占。
spin_lock() 比 spin_lock_irq() 速度快。
举个例子: 进程 A 中调用了 spin_lock(&lock) 然后进入临界区,此时来了一个中断,该中断也运行在和进程 A 相同的 CPU 上,并且在该中断处理程序中恰巧也会 spin_lock(&lock) 试图获取同一个锁。由于是在同一个 CPU 上被中断,进程 A 会被设置为 TASK_INTERRUPT 状态,中断处理程序无法获得锁,会不停的忙等,由于进程 A 被设置为中断状态,schedule() 进程调度就无法再调度进程 A 运行,这样就导致了死锁!但是如果该中断处理程序运行在不同的 CPU 上就不会触发死锁。 因为在不同的 CPU 上出现中断不会导致进程 A 的状态被设为 TASK_INTERRUPT,只是换出。当中断处理程序忙等被换出后,进程 A 还是有机会获得 CPU,执行并退出临界区。所以在使用 spin_lock() 时要明确知道该锁不会在中断处理程序中使用。
spin_lock_irq() 与 spin_lock_irqsave() 区别。
-
spin_lock_irqsave()锁返回时,中断状态不会被改变,调用spin_lock_irqsave()前是开中断返回就开中断。 -
spin_lock_irq()锁返回时,永远都是开中断,即使spin_lock_irq()前是关中断。
看起来 spin_lcok_irqsave() 更智能一些,毕竟没有人希望自己 spin unlock 过后中断被打开了。那为什么还有人用 spin_lock_irq() 呢?
因为不需要保存中断寄存器,所以性能更好,如果能确定之前就不是关中断的状态,那么使用 spin_lock_irq() 无疑具有更高的性能。
定义一个 spinlock 的实现
(4 封私信 / 24 条消息) linux 内核 spinlock 的实现 - 知乎
spinlock 的实现其实也是和硬件 ISA 架构强相关的,比如 x86 和 ARM 实现就是不一样的。
下面代码都是进行了合理简化之后的,可见还是基于 atomic_t 原子变量来实现的。
typedef struct qspinlock {
union {
atomic_t val;
/*
* By using the whole 2nd least significant byte for the
* pending bit, we can allow better optimization of the lock
* acquisition for the pending bit holder.
*/
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
};
} arch_spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
} raw_spinlock_t;
typedef struct spinlock {
struct raw_spinlock rlock;
} spinlock_t;
#define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)
Spinlock 拿锁的实现 spin_lock_irqsave(), spin_lock_irq(), spin_lock()
spin_lock_irqsave
raw_spin_lock_irqsave
_raw_spin_lock_irqsave
__raw_spin_lock_irqsave
static inline unsigned long __raw_spin_lock_irqsave(raw_spinlock_t *lock)
{
unsigned long flags;
// 关掉中断,关掉抢占
local_irq_save(flags);
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
/*
* On lockdep we dont want the hand-coded irq-enable of
* do_raw_spin_lock_flags() code, because lockdep assumes
* that interrupts are not re-enabled during lock-acquire:
*/
#ifdef CONFIG_LOCKDEP
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
#else
do_raw_spin_lock_flags(lock, &flags);
#endif
return flags;
}
spin_lock_irq
raw_spin_lock_irq
_raw_spin_lock_irq
static inline void __raw_spin_lock_irq(raw_spinlock_t *lock)
{
local_irq_disable();
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
spin_lock
raw_spin_lock
_raw_spin_lock
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
可以看到核心代码都是这两行:
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
lock_acquire_exclusive(&lock->dep_map, 0, 0, NULL, _RET_IP_)
lock_acquire(&lock->dep_map, 0, 0, 0, 1, NULL, _RET_IP_)
void lock_acquire(struct lockdep_map *lock, unsigned int subclass, int trylock, int read, int check,
struct lockdep_map *nest_lock, unsigned long ip)
{
unsigned long flags;
//...
if (!debug_locks)
return;
if (unlikely(!lockdep_enabled())) {
/* XXX allow trylock from NMI ?!? */
if (lockdep_nmi() && !trylock) {
struct held_lock hlock;
hlock.acquire_ip = ip;
hlock.instance = lock;
hlock.nest_lock = nest_lock;
hlock.irq_context = 2; // XXX
hlock.trylock = trylock;
hlock.read = read;
hlock.check = check;
hlock.hardirqs_off = true;
hlock.references = 0;
verify_lock_unused(lock, &hlock, subclass);
}
return;
}
raw_local_irq_save(flags);
check_flags(flags);
lockdep_recursion_inc();
__lock_acquire(lock, subclass, trylock, read, check,
irqs_disabled_flags(flags), nest_lock, ip, 0, 0);
lockdep_recursion_finish();
raw_local_irq_restore(flags);
}
// 传进来一个 lock,一个
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
#define LOCK_CONTENDED(_lock, try, lock) \
do { \
if (!try(_lock)) { \
lock_contended(&(_lock)->dep_map, _RET_IP_); \
lock(_lock); \
} \
lock_acquired(&(_lock)->dep_map, _RET_IP_); \
} while (0)
queued_spin_lock_slowpath() Kernel
/**
* queued_spin_lock_slowpath - acquire the queued spinlock
* @lock: Pointer to queued spinlock structure
* @val: Current value of the queued spinlock 32-bit word
*
* (queue tail, pending bit, lock value)
*
* fast : slow : unlock
* : :
* uncontended (0,0,0) -:--> (0,0,1) ------------------------------:--> (*,*,0)
* : | ^--------.------. / :
* : v \ \ | :
* pending : (0,1,1) +--> (0,1,0) \ | :
* : | ^--' | | :
* : v | | :
* uncontended : (n,x,y) +--> (n,0,0) --' | :
* queue : | ^--' | :
* : v | :
* contended : (*,x,y) +--> (*,0,0) ---> (*,0,1) -' :
* queue : ^--' :
*/
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
struct mcs_spinlock *prev, *next, *node;
u32 old, tail;
int idx;
//...
// 如果是 pv spinlock,表示现在我们是在 guest kernel 中运行,
// 那么就走到 pv_queue 中去走 hypercall 路径。
if (pv_enabled())
goto pv_queue;
if (virt_spin_lock(lock))
return;
/*
* Wait for in-progress pending->locked hand-overs with a bounded
* number of spins so that we guarantee forward progress.
*
* 0,1,0 -> 0,0,1
*/
if (val == _Q_PENDING_VAL) {
int cnt = _Q_PENDING_LOOPS;
val = atomic_cond_read_relaxed(&lock->val,
(VAL != _Q_PENDING_VAL) || !cnt--);
}
/*
* If we observe any contention; queue.
*/
if (val & ~_Q_LOCKED_MASK)
goto queue;
/*
* trylock || pending
*
* 0,0,* -> 0,1,* -> 0,0,1 pending, trylock
*/
val = queued_fetch_set_pending_acquire(lock);
/*
* If we observe contention, there is a concurrent locker.
*
* Undo and queue; our setting of PENDING might have made the
* n,0,0 -> 0,0,0 transition fail and it will now be waiting
* on @next to become !NULL.
*/
if (unlikely(val & ~_Q_LOCKED_MASK)) {
/* Undo PENDING if we set it. */
if (!(val & _Q_PENDING_MASK))
clear_pending(lock);
goto queue;
}
/*
* We're pending, wait for the owner to go away.
*
* 0,1,1 -> 0,1,0
*
* this wait loop must be a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because not all
* clear_pending_set_locked() implementations imply full
* barriers.
*/
if (val & _Q_LOCKED_MASK)
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));
/*
* take ownership and clear the pending bit.
*
* 0,1,0 -> 0,0,1
*/
clear_pending_set_locked(lock);
lockevent_inc(lock_pending);
return;
/*
* End of pending bit optimistic spinning and beginning of MCS
* queuing.
*/
queue:
lockevent_inc(lock_slowpath);
pv_queue:
node = this_cpu_ptr(&qnodes[0].mcs);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
/*
* 4 nodes are allocated based on the assumption that there will
* not be nested NMIs taking spinlocks. That may not be true in
* some architectures even though the chance of needing more than
* 4 nodes will still be extremely unlikely. When that happens,
* we fall back to spinning on the lock directly without using
* any MCS node. This is not the most elegant solution, but is
* simple enough.
*/
if (unlikely(idx >= MAX_NODES)) {
lockevent_inc(lock_no_node);
while (!queued_spin_trylock(lock))
cpu_relax();
goto release;
}
node = grab_mcs_node(node, idx);
/*
* Keep counts of non-zero index values:
*/
lockevent_cond_inc(lock_use_node2 + idx - 1, idx);
/*
* Ensure that we increment the head node->count before initialising
* the actual node. If the compiler is kind enough to reorder these
* stores, then an IRQ could overwrite our assignments.
*/
barrier();
node->locked = 0;
node->next = NULL;
pv_init_node(node);
/*
* We touched a (possibly) cold cacheline in the per-cpu queue node;
* attempt the trylock once more in the hope someone let go while we
* weren't watching.
*/
if (queued_spin_trylock(lock))
goto release;
/*
* Ensure that the initialisation of @node is complete before we
* publish the updated tail via xchg_tail() and potentially link
* @node into the waitqueue via WRITE_ONCE(prev->next, node) below.
*/
smp_wmb();
/*
* Publish the updated tail.
* We have already touched the queueing cacheline; don't bother with
* pending stuff.
*
* p,*,* -> n,*,*
*/
old = xchg_tail(lock, tail);
next = NULL;
/*
* if there was a previous node; link it and wait until reaching the
* head of the waitqueue.
*/
if (old & _Q_TAIL_MASK) {
prev = decode_tail(old);
/* Link @node into the waitqueue. */
WRITE_ONCE(prev->next, node);
pv_wait_node(node, prev);
arch_mcs_spin_wait(&node->locked);
/*
* While waiting for the MCS lock, the next pointer may have
* been set by another lock waiter. We optimistically load
* the next pointer & prefetch the cacheline for writing
* to reduce latency in the upcoming MCS unlock operation.
*/
next = READ_ONCE(node->next);
if (next)
prefetchw(next);
}
/*
* we're at the head of the waitqueue, wait for the owner & pending to
* go away.
*
* *,x,y -> *,0,0
*
* this wait loop must use a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because the set_locked() function below
* does not imply a full barrier.
*
* The PV pv_wait_head_or_lock function, if active, will acquire
* the lock and return a non-zero value. So we have to skip the
* atomic_cond_read_acquire() call. As the next PV queue head hasn't
* been designated yet, there is no way for the locked value to become
* _Q_SLOW_VAL. So both the set_locked() and the
* atomic_cmpxchg_relaxed() calls will be safe.
*
* If PV isn't active, 0 will be returned instead.
*
*/
if ((val = pv_wait_head_or_lock(lock, node)))
goto locked;
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));
locked:
/*
* claim the lock:
*
* n,0,0 -> 0,0,1 : lock, uncontended
* *,*,0 -> *,*,1 : lock, contended
*
* If the queue head is the only one in the queue (lock value == tail)
* and nobody is pending, clear the tail code and grab the lock.
* Otherwise, we only need to grab the lock.
*/
/*
* In the PV case we might already have _Q_LOCKED_VAL set, because
* of lock stealing; therefore we must also allow:
*
* n,0,1 -> 0,0,1
*
* Note: at this point: (val & _Q_PENDING_MASK) == 0, because of the
* above wait condition, therefore any concurrent setting of
* PENDING will make the uncontended transition fail.
*/
if ((val & _Q_TAIL_MASK) == tail) {
if (try_clear_tail(lock, val, node))
goto release; /* No contention */
}
/*
* Either somebody is queued behind us or _Q_PENDING_VAL got set
* which will then detect the remaining tail and queue behind us
* ensuring we'll see a @next.
*/
set_locked(lock);
/*
* contended path; wait for next if not observed yet, release.
*/
if (!next)
next = smp_cond_load_relaxed(&node->next, (VAL));
mcs_lock_handoff(node, next);
pv_kick_node(lock, next);
release:
/*
* release the node
*/
__this_cpu_dec(qnodes[0].mcs.count);
}
EXPORT_SYMBOL(queued_spin_lock_slowpath);
Locking lessons — The Linux Kernel documentation
应用场景:
- 可以在中断上下文执行。由于不睡眠,因此 spinlock 可以在中断上下文中适用。
- 执行时间短。由于 spin lock 死等这种特性,因此它使用在那些代码不是非常复杂的临界区(当然也不能太简单,否则使用原子操作或者其他适用简单场景的同步机制就 OK 了),如果临界区执行时间太长,那么不断在临界区门口“死等”的那些 thread 是多么的浪费 CPU 啊(当然,现代 CPU 的设计都会考虑同步原语的实现,例如 ARM 提供了 WFE 和 SEV 这样的类似指令,避免 CPU 进入 busy loop 的悲惨境地)
原子变量
一战爆发以后,大哲学家罗素不去参战而去反战,有个老太太很生气地对他说:“别的小伙子都为了保卫文明穿上军装打仗去了,你就不惭愧么?”罗素回答说:“我就是他们要保卫的那种文明。”
锁保持的是指令间的值不变,而原子变量保持的是指令内的值不变。不要把 atomic_t 的作用和锁弄混,他们不是一个生态位的。atomic_t 并不是一个锁可以 acquire/release,它代表了我们要保护的数据本身,对应到锁里,就是锁要保护的数据。
The purpose of atomic_t is to implement a type and a set of functions that can operate on it correctly from different threads without requiring synchronization like mutexes.
- 单核系统上,原子操作可以通过禁中断的方式来保证不调度到其他线程修改这块内存区域;
- 多核系统上,基于硬件机制比如锁总线。单核和多核的区别,在于单核的 race 只会发生在指令间,每一条单独的指令执行都是原子的;多核情况下,可能两个核在真并行地执行同一条汇编指令,比如同时增加一个内存的值,因为一条指令比如说
incl也分为读取修改写回三个阶段,不难想象,有可能导致两次增加的操作只执行了一次。
原子变量的实现,是和硬件的体系结构强相关的。在 x86 架构下,CPU 提供了在指令执行期间对总线加锁的手段。CPU 上有一根引线 #HLOCK pin 连到北桥,如果汇编语言的程序中在一条指令前面加上前缀 "LOCK",经过汇编以后的机器代码就使 CPU 在执行这条指令的时候把 #HLOCK pin 的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的 CPU 就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子性。这个 lock 锁的是片内总线也就是 Ring/Mesh^ 总线。这个 lock 指令也就隐含了全内存屏障(memory barrier)的效果。
因为 atomic 是借助硬件的,这个 lock 只能针对单条指令,能锁的也就一个 word,所以其能保存的数据只能是一个 word。因此原子变量能够让我们要保护的数据很小的情况下,不需要用锁,而是借助硬件的能力,保证多线程同时更新同一个数据时的正确性。
atomic_t / atomic64_t
typedef struct {
int counter;
} atomic_t;
typedef struct {
s64 counter;
} atomic64_t;
atomic_t 使用场景
原子变量并不是根据。
void kvm_inject_apic_timer_irqs(struct kvm_vcpu *vcpu)
{
struct kvm_lapic *apic = vcpu->arch.apic;
// read 和 set 之间肯定有可能被其他进程改吧。
if (atomic_read(&apic->lapic_timer.pending) > 0) {
kvm_apic_inject_pending_timer_irqs(apic);
atomic_set(&apic->lapic_timer.pending, 0);
}
}
atomic_t API
| 接口函数 | 描述 |
|---|---|
void atomic_add(int i, atomic_t *v) |
给一个原子变量 v 增加 i |
int atomic_add_return(int i, atomic_t *v) |
同上,只不过将变量 v 的最新值返回 |
void atomic_sub(int i, atomic_t *v) |
给一个原子变量 v 减去 i |
int atomic_sub_return(int i, atomic_t *v) |
同上,只不过将变量 v 的最新值返回 |
int atomic_cmpxchg(atomic_t *ptr, int old, int new) |
比较 old 和原子变量 ptr 中的值,如果相等,那么就把 new 值赋给原子变量。返回旧的原子变量 ptr 中的值 |
atomic_read |
获取原子变量的值 |
atomic_set |
设定原子变量的值 |
atomic_inc(v) |
原子变量的值加一 |
atomic_inc_return(v) |
同上,只不过将变量 v 的最新值返回 |
atomic_dec(v) |
原子变量的值减去一 |
atomic_dec_return(v) |
同上,只不过将变量 v 的最新值返回 |
atomic_sub_and_test(i, v) |
给一个原子变量 v 减去 i,并判断变量 v 的最新值是否等于 0 |
atomic_add_negative(i,v) |
给一个原子变量 v 增加 i,并判断变量 v 的最新值是否是负数 |
int atomic_add_unless(atomic_t *v, int a, int u) |
只要原子变量 v 不等于 u,那么就执行原子变量 v 加 a 的操作。如果 v 不等于 u,返回非 0 值,否则返回 0 值 |
atomic_inc() 函数在 x86 体系架构下的实现。可见前面加了 lock 的 prefix,这个 prefix 可以把整个系统总线(包括 Mesh 片内总线)锁住,从而保证指令的执行结果是原子的,同时我们也保证只生成一条指令,防止在 inc 的过程中被修改。
//arch/x86/include/asm/atomic.h
//...
static __always_inline void arch_atomic_inc(atomic_t *v)
{
asm_inline volatile(LOCK_PREFIX "incl %0"
: "+m" (v->counter) :: "memory");
}
atomic_sub_and_test() 函数可以生成两条指令:lock subl i, (v->counter) 和 sete %al。后者通过判断 ZF 位来进行判断,这个 ZF 位在第一条指令执行完就置上了,所以虽然是两条分开的指令,但是不会和其他核之间产生 race condition。这个 test 的能保证就是上一条指令 subl 执行完后这个变量的值,但是并不保证当下的值是多少。
//arch/x86/include/asm/atomic.h
static __always_inline bool arch_atomic_sub_and_test(int i, atomic_t *v)
{
return GEN_BINARY_RMWcc(LOCK_PREFIX "subl", v->counter, e, "er", i);
}
atomic_read() 和 atomic_write() 这两个函数其实不需要 LOCK 前缀,因为没有读取修改写回三个阶段,只有读取/修改。
atomic_cmpxchg() 也是基于一个硬件指令(需要 lock 住)来保证正确性:lock cmpxchg 指令。
Compare and Swap (CAS)
CAS 操作基于 CPU 提供的原子操作指令实现。对于 Intel x86 处理器,可通过在汇编指令前增加 LOCK 前缀来锁定系统总线,使系统总线在汇编指令执行时无法访问相应的内存地址。比如 atomic_cmpxchg() 函数。
无锁(Lock-Free)
不存在真正的无锁。任何涉及到多线程并行的东西,想要保证正确性都是需要锁的。所谓无锁,指的是仅仅使用硬件锁(比如 x86 LOCK 指令前缀),而不是基于硬件锁来实现软件锁。
无锁队列
无锁队列的典型应用场景是同时存在单(多)线程写入与单(多)线程读取。
static inline AtomicWord AtomicExchangeExplicit(volatile AtomicWord* p, AtomicWord val)
{
// 把 p 的值更新成 val 并返回原来 p 的值。
return (AtomicWord)_InterlockedExchange64((volatile long long*)p, (long long)val);
}
static inline bool AtomicCompareExchangeStrongExplicit(volatile AtomicWord* p, AtomicWord* oldval, AtomicWord newval)
{
// 把 p 的值和 oldval 比,如果相等则赋值为 newval。
long long res = _InterlockedCompareExchange64((volatile long long*)p, (long long)newval, (long long)*oldval);
if(res == *oldval)
return true;
*oldval = res;
return false;
}
void Enqueue(AtomicNode* node) {
AtomicNode* prev;
node->_next = 0;
prev = (AtomicNode*)AtomicExchangeExplicit(&_tail, (AtomicWord)node);
prev->_next = (AtomicWord)node;
}
AtomicNode* Dequeue() {
AtomicNode* res, * next;
void* data;
AtomicWord head = _head;
AtomicWord newHead;
do
{
// 出队的时候最后剩下的是最后一次入队的节点
res = (AtomicNode*)head;
next = (AtomicNode*)res->_next;
if (next == nullptr)
return nullptr;
data = next->data;
newHead = (AtomicWord)next;
// 比较_head指针是否是我们之前获取的,成功则设置newHead,失败则自旋
} while (!AtomicCompareExchangeStrongExplicit(&_head, &head, newHead));
res->data = data;
return res;
}
往队列尾部加元素分为两步:
- tail 变量的值更新成我们要加的节点;
- 原来 tail 的 next 连到我们要加的节点上。
仔细分析可以发现,不同线程的步骤 2 之间不会出现 race condition,不同线程的步骤 1 和步骤 2 之间也不会出现 race condition,但是不同线程的步骤 1 之间会出现 race condition:更新的顺序会影响到正确性。
因此
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。