容器技术总览
OCI (Open Container Initiative) & CRI (Container Runtime Interface) & CNI (Container Network Interface) & CSI (Container Storage Interface)
https://my.feishu.cn/wiki/WsJLwYuULigw1Lkrw9cczCKKniL#share-UKUmdI3Sooj9WwxSwq1cwNowngf
一句话,kubelet 通过 CRI 调用到高级容器运行时、高级容器运行时 J 通过 OCI 的一套规范调用到低级容器运行时。
OCI:
The OCI Runtime Spec defines the behavior and the configuration interface of low-level container runtimes such as runc. The spec is also implemented by crun, youki, gVisor, Kata Containers, and others. These low-level container runtimes are usually called from high-level container runtimes such as containerd and CRI-O.
核心规范:
- 镜像规范(Image Spec):定义容器镜像的打包、存储、传输格式(即你下载的镜像如何解包成根文件系统)。
- 运行时规范(Runtime Spec):定义如何从镜像启动一个容器进程(包括生命周期管理、配置、钩子等)。
意义:有了 OCI,Docker 公司推广的镜像格式和运行时方式成为开放标准,避免了厂商锁定。例如,Podman 可以直接运行 Docker 构建的镜像,就是因为双方都遵守 OCI 规范。
CRI:
Kubernetes 要管理容器,但市面上的容器运行时多种多样(Docker、containerd、CRI-O 等)。如果 Kubernetes 为每种运行时都写一套底层代码(或者叫 shim),会非常臃肿且难以维护。Kubernetes 在 v1.5 版本后引入了 CRI。它定义了一套标准的 gRPC API 接口。每台节点上的 Kubelet 只需要调用这套标准接口,无需关心底层具体是什么运行时。
CNI:
是一套标准和规范。规定了 kubelet 和网络插件之间怎么通信。
Kata vs. Kubevirt
Kata 一个 Pod 提供一个 Guest OS,这个 Pod 的所有容器都运行在这个 Guest OS 里面。
Kubevirt 是一个 Pod 的概念包了一个 Guest OS,然后上面不会再启动新的容器了,就直接是虚拟机了。
Kata 的存储方案:Kata 因为是一个虚拟机,没有办法像传统容器那样,直接挂载一个 PV 上去(举个例子)。传统容器的直通很简单,因为都是基于 UnionFS 的,只要把宿主机文件系统上的这一层透传过去就可以了,但是 Kata 不行,Kata 是通过 virtio-fs^ 这个框架来实现的。
Kata 的网络方案:
KubeVela & OAM (Open Application Model)
OAM:一个应用描述规范,举个例子,docker-compose 本身也是基于 YAML 来描述应用服务组件网络。OAM 其实就是一个更加规范化的描述。
KubeVela:可以让应用工程师直接使用 OAM 然后 KubeVela 自动给你映射到对应的资源比如 Pod 等等。KubeVela 是一个 “运行在 K8s 上、用 OAM 模型给企业提供应用编排和多集群部署能力” 的平台——它的工作核心是把开发者写的应用 YAML 翻译成 k8s 资源、按工作流部署到多个集群、并把这一整套能力的扩展权交给平台工程师。
容器与宿主机共享/私有内容
| dmesg | 和宿主机共享 |
|---|---|
| 内核 | 和宿主机共享 |
| rocm-smi | 和宿主机共享 |
| nvidia-smi | 和宿主机共享 |
Run multiple processes in a container?
在 Docker 容器中虽然理论上可以运行多个应用进程,但实际上这并 G 不符合 Docker 设计的最佳实践。Docker 容器的核心理念是每个容器应该只包含一个主要的应用服务进程,这一理念被称为“单进程容器”模型。
一个容器只运行一个主进程。多个进程都部署在一个容器中,弊端很多。
可以通过这种方式来运行多个进程:docker/md/在一个docker容器中运行多个程序进程的Dockerfile编写.md at main · cucker0/docker
ps In container
看到的是限制之后的进程,比如 ps -A:
PID TTY TIME CMD
1 ? 00:02:58 light
599 ? 00:00:00 sshd
600 ? 00:00:00 crond
17463 ? 00:00:01 controller.sh
18344 ? 00:04:17 ld-linux-x86-64
19269 ? 16:48:26 java
90173 ? 00:00:00 syslog-ng
90179 ? 00:00:03 systemd-journal
148290 pts/0 00:00:00 bash
148368 ? 00:00:00 sleep
148640 pts/0 00:00:00 ps
...
容器 dmesg
因为容器和 host 是共享内核的,所以容器上执行 dmesg 是可以看到 host 上的 dmesg 的,两者是一致的。
Best practice to host containers?
是应该跑在 VM 里面还是跑在 Baremetal 的机器上。
跑在 VM 里的好处有:
- 因为 docker 对操作系统内核版本是有要求的,如果跑在 baremetal 上,只有一种 kernel 所以没有办法满足所有 docker 的需求,我们可以跑不同 VM 里面跑不同内核来满足这一个需求,kata 就是采用这种实现方式。
- 有一些 App 本来是跑在 baremetal 上的,调度也是基于 baremetal 来调度的,如果现在直接容器化需要对原来的调度框架有很大的改动,所以不如直接跑在虚拟机(runD, kata)里,这样调度系统也不需要改。
Container engine / Container runtime / 容器运行时
这些名字都来自于 OCI^(Open Container Initiative) 的定义。
所有的容器其实都是 kernel 里的 cgroup 而已,通过 cgroup 加了一些 CPU 计算资源/内存资源/存储上的隔离。
Container engines, runtimes and orchestrators: an overview - Stefano Alberto Russo 这里解释挺清楚的:
- A container engine is a piece of software that accepts user requests, including command line options, pulls images, and from the end user's perspective runs the container.
- A container runtime is a software which is in charge of managing the container lifecycle: configuring its environment, running it, stopping it, and so on. You can think about them as what's inside the engine (i.e valves and pistons). Runtimes can be further sub-divided in two types: high level and low level.
- high level container runtimes, or container runtime interfaces (CRI) for Kubernetes.
- low level container runtimes, or CRI runtimes for Kubernetes.
- Also note that some engines can behave as runtimes and can be thus used from within other engines, or orchestrators.
- Lastly, a container orchestrator is a software in charge of managing set of containers across different computing resources, handling network and storage configurations which are under the hood delegated to the container runtimes (or in some nearly legacy cases, engines).
While a container runtime is responsible for running containers, a container engine is a broader system that manages even more of the life cycle of containers.
运行时也分为低层运行时和高层运行时(高级运行时会调用低级运行时,比如当启动一个 docker 容器时,containerd 就会直接调用 runc):
-
低层运行时主要负责与宿主机操作系统打交道,根据指定的容器镜像在宿主机上运行容器进程,并对容器的整个生命周期进行管理,也就是负责设置容器 Namespace、Cgroups 等基础操作的组件(或者加入一些虚拟化的操作)。常见的低层运行时有:
-
runc:传统的运行时,基于 Linux Namespace 和 Cgroups 技术实现,负责实际的容器创建、隔离和执行操作。 -
runv/kata-runtime:kata 的诞生源自于 runV。通过虚拟化 guest kernel,将容器和主机隔离开来,使得其边界更加清晰。 -
runsc:runc + safety,通过拦截应用程序的所有系统调用,提供安全隔离的轻量级容器运行时沙箱,代表实现是谷歌的 gVisor。
-
-
高层运行时主要负责容器的生命周期管理、镜像管理、网络管理和存储管理等工作,为容器的运行做准备。主流的高层运行时包括 containerd、CRI-O。高层运行时与低层运行时各司其职,容器运行时一般先由高层运行时将容器镜像下载下来,并解压转换为容器运行需要的操作系统文件,再由低层运行时启动和管理容器。
- containerd 是一个面向容器生命周期管理的高层容器运行时。它提供了容器的生命周期管理、镜像管理、存储管理和网络管理等功能。containerd 可以与容器编排系统(如 Kubernetes)紧密集成,为容器的创建、启动、停止和销毁等操作提供 API 接口。
- CRI-O 是一个轻量级容器运行时,专注于在 Kubernetes 环境中运行容器,符合 Kubernetes CRI 规范,使用 runc 作为底层执行引擎。
OCI 规范保证了高低运行时之间的互换性,理论上任何两个运行时搭配都可以配合工作。但在实际生产中,为了获得更好的性能和功能(高级功能如流式日志、优雅关闭等),高层运行时往往会为特定的底层运行时开发专用的集成组件(Shim),这并非强制性的技术依赖,只是一种优化。
runtime 有:
- docker
- runC
- runD
engine 有:
- containerd
- Docker Engine
- Pouch
Pouch / Containerd
这两者好像是介于 k8s 这一层和 runC / runD 这一层之间的。
Docker
Image, container and instance / Docker 的三个重要概念
Image、Container(静态容器) 和 Instance(运行时容器) 的概念需要梳理:
- Image 和 Container 都是文件,其中 Container 是通过 image 加上一些 docker 参数创建的。
- Container 在 run 的时候会成为一个 Instance,Instance 运行时写在容器层(读写层)的数据在 Instance 关闭后还是存在的,保存在 container 当中,只有在删除 container 的时候才会消失。
- 当我们对 instance 执行 restart 后,其实容器中原本读写层里临时数据还在,因为读写层数据会写入到 container(注意不会写入到 image 当中)。只有我们删除了这个 container,重新创建的 container 是基于 image 的只读层然后挂载上新的空的读写层,此时临时数据是不在的。
【博客618】docker容器重启后读写层数据并不丢失的原理_docker mysql容器重启 数据还在吗-CSDN博客
Docker 与跨指令集架构 / 跨操作系统
Docker 镜像能跨平台运行;只要系统架构一样,是可以使用相同的镜像的,x86 的镜像只能在 x86 系统使用,arm 的镜像只能在 arm 系统使用。
Docker 利用宿主机内核提供了轻量级、可移植、高效的容器解决方案,但这也要求宿主机和容器之间保持内核层面的一致性和兼容性。Docker 确保容器内的应用与宿主机的内核版本和配置尽可能兼容。
如果宿主机运行的是 Linux 内核,那么它通常无法直接运行基于其他操作系统的容器,例如 Windows 容器。为了解决这个问题,Docker 使用了各种技巧和折衷方案,比如在非 Linux 系统上通过虚拟机来提供 Linux 内核环境,使 Docker 容器能够运行。
docker 镜像内核 和宿主机内核是什么关系 – PingCode
Docker 如何重新调整容器的启动参数?
只能通过 docker commit 来重新提交现有镜像保存更改,然后重新 run 一个参数了:
docker commit <container_name_or_id> new_image_name:tag
Docker 可以不指定任何一个 CMD / ENTRYPOINT 来运行一个进程吗?
基础镜像已定义默认命令:大多数官方镜像(如 ubuntu、nginx、alpine)已设置默认的 CMD 或 ENTRYPOINT 比如进入交互式终端。
或者直接指定一个永远不会退出的命令:
CMD ["sh", "-c", "tail -f /dev/null"]
如果要运行:
docker start
Docker kernel config
CONFIG_BPF, CONFIG_BPF_SYSCALL, CONFIG_CGROUP_BPF
Check if the kernel config is suitable for running docker:
Verify your Linux Kernel for Container Compatibility · Docker Pirates ARMed with explosive stuff
wget https://github.com/moby/moby/raw/master/contrib/check-config.sh
chmod +x check-config.sh
./check-config.sh
ADD And COPY in Dockerfile
Always use the COPY instruction instead of the ADD instruction when adding files into your Docker image.
Docker 的替代产品
| Orbstack | 和 docker 一样,需要商用。 |
| Lima | 只有一个虚拟机。 |
| Colima | 完全开源,Lima 的虚拟机,加上 docker 的容器运行时。 |
Docker 常用命令
# 基于 DOCKERFILE 来创建一个容器
docker build -t my-training-image:latest .
# 基于一个 image 地址创建一个容器
docker run <image name>
# 登入 docker shell
docker exec -it <mycontainer> sh
# 检查容器 log(失败 log)
docker logs <container_name>
# 查看所有容器状态
docker container ls --all
# 重新启动一个创建好的容器
docker start <container_name>
docker run --runtime=nvidia Vs docker run --gpus all
注意,不论哪种方式,都请注意下面副作用:
- 会把宿主机的 CUDA 目录(
/usr/lib/x86_64-linux-gnu/libcuda.so等等)透传进来。如果要避免这个副作用,使用容器内自己的镜像,可以使用下面这些方式来做:
--runtime=nvidia(旧版方式)
指定 Docker 使用 NVIDIA 提供的容器运行时(而非默认的 runc),该运行时负责自动挂载 NVIDIA 驱动和 GPU 设备文件。
通过环境变量 NVIDIA_VISIBLE_DEVICES 控制 GPU 可见性(如 all, 0,1)。
--gpus all(新版方式)
直接通过 Docker 原生 CLI 参数分配 GPU 资源(无需切换运行时)。推荐使用,是 Docker 官方支持的 GPU 分配方式。
Docker Compose 详解 / kompose / Compose Bridge
主要是为了从编排角度揭示 Docker 对于计算资源的抽象模型。
k8s 的语境下其实也有相似的概念,一个 Docker Compose 其实可以对应一些工作负载,可以通过 kompose 来转换,举个例子来说:假设你的 docker-compose.yml 里有 web 和 db 两个服务,直接运行:
kompose convert
会生成 4 个文件(每个服务一个 Deployment,一个 Service):
-
web-deployment.yaml:replica 个后端计算资源(Pod); -
web-service.yaml:请求入口,负责负载均衡和路由; -
db-deployment.yaml:replica 个后端数据库资源; -
db-service.yaml:请求入口,负责负载均衡和路由。
接下来我们可以仔细研究一下 docker compose 这个工具。
一个包含 docker-compose.yaml 所能包含的编排模型的能力边界示例:
# =============================================================================
# Compose Specification 完整功能演示文件
# 本文件覆盖 spec 中所有顶级元素与服务级、网络级、卷级等子属性,仅用于展示。
# 每个属性附简短中文注释。
# =============================================================================
# version:已废弃保留字段,仅作向后兼容(spec 04 章节)
version: "3.9"
# name:顶级项目名,未显式覆盖时作为默认 COMPOSE_PROJECT_NAME(spec 04 章节)
name: full-spec-demo
# -----------------------------------------------------------------------------
# include:声明对其他 Compose 应用的依赖,加载后资源合并到本模型(spec 14 章节)
# -----------------------------------------------------------------------------
include:
# 短语法:直接给出路径
- ./common/compose.yaml
# 长语法:可指定 project_directory 与 env_file
- path:
- ../shared/base.yaml
- ../shared/override.yaml
project_directory: ..
env_file:
- ../shared/.env
- ../shared/dev.env
# -----------------------------------------------------------------------------
# x-* 扩展字段:自定义可复用块,Compose 不会校验(spec 11 章节)
# 同时演示 YAML 锚点 & 别名(spec 10 章节 fragments)
# -----------------------------------------------------------------------------
x-common-env: &common-env # 锚点:通用环境变量
TZ: UTC
LOG_LEVEL: info
x-default-logging: &default-logging # 锚点:通用日志配置
driver: json-file
options:
max-size: "10m"
max-file: "3"
x-healthcheck: &default-healthcheck # 锚点:通用健康检查
test: ["CMD", "curl", "-fsS", "http://localhost/health"]
interval: 30s
timeout: 5s
retries: 3
start_period: 20s
start_interval: 5s
# =============================================================================
# services:核心顶级元素,定义所有计算单元(spec 05 章节)
# =============================================================================
services:
# ---------------------------------------------------------------------------
# frontend:演示绝大多数服务级属性(端口、网络、依赖、生命周期 hook 等)
# ---------------------------------------------------------------------------
frontend:
# annotations:容器注解(map 或 list 均可)
annotations:
com.example.role: "frontend"
# attach:是否收集服务日志,false 时除非显式请求否则不收集
attach: true
# build:从源码构建镜像,参见下方 build 详细字段(spec build.md)
build:
context: ./webapp # 构建上下文目录
dockerfile: Dockerfile # 指定 Dockerfile
# dockerfile_inline 与 dockerfile 互斥,此处仅注释展示用法:
# dockerfile_inline: |
# FROM nginx
# RUN echo hi
args: # 构建参数(对应 ARG)
GIT_COMMIT: "abcdef"
cache_from: # 缓存来源
- type=registry,ref=myorg/webapp:cache
cache_to: # 缓存导出
- type=local,dest=/tmp/.buildx-cache
additional_contexts: # 命名构建上下文
resources: ./resources
base: service:backend # 引用另一个服务作为基础镜像
extra_hosts: # 构建期 hosts 映射
- "buildhost=10.0.0.10"
isolation: default # 构建容器隔离技术
labels: # 镜像标签
com.example.image: "webapp"
network: host # 构建期网络模式
no_cache: false # 强制无缓存重建
pull: true # 强制 pull FROM 镜像
privileged: false # 特权构建
platforms: # 多平台构建目标
- linux/amd64
- linux/arm64
provenance: mode=max # 构建溯源证明
sbom: true # 生成 SBOM
secrets: # 构建期 secret 挂载
- source: server-certificate
target: cert
uid: "103"
gid: "103"
mode: 0440
ssh: # 构建期 SSH 代理
- default
- myproject=~/.ssh/myproject.pem
shm_size: "256mb" # 构建期 /dev/shm 大小
tags: # 额外镜像 tag
- "myorg/webapp:latest"
- "registry.example.com/webapp:1.0"
target: prod # 多阶段构建目标 stage
ulimits: # 构建期 ulimit
nproc: 65535
nofile:
soft: 20000
hard: 40000
entitlements: # 额外特权授权
- network.host
- security.insecure
image: example/webapp:1.0 # 运行镜像;同时存在 build 时受 pull_policy 控制
# command:覆盖镜像默认 CMD(exec form)
command: ["nginx", "-g", "daemon off;"]
# container_name:自定义容器名(限制副本数为 1)
container_name: webapp-frontend
# depends_on(长语法):声明启动顺序与等待条件
depends_on:
backend:
condition: service_healthy # 等待 backend 健康
restart: true # backend 更新后随之重启
required: true
cache:
condition: service_started
migrator:
condition: service_completed_successfully # 等待一次性任务完成
# deploy:部署元数据(spec deploy.md)
deploy:
mode: replicated # replicated 或 global
replicas: 3 # 副本数
endpoint_mode: vip # 服务发现模式
labels:
com.example.tier: "frontend"
placement: # 节点放置策略
constraints:
- "node.role==worker"
- "node.labels.disktype==ssd"
preferences:
- spread: node.labels.zone
resources: # 资源限制与预留
limits:
cpus: "0.50"
memory: 512M
pids: 200
reservations:
cpus: "0.25"
memory: 256M
devices: # 设备预留(GPU/TPU 等)
- capabilities: ["gpu"]
driver: nvidia
count: 1
options:
virtualization: "false"
restart_policy: # 容器重启策略
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
rollback_config: # 更新失败回滚配置
parallelism: 1
delay: 10s
failure_action: pause
monitor: 30s
max_failure_ratio: 0.2
order: stop-first
update_config: # 滚动更新配置
parallelism: 2
delay: 10s
failure_action: rollback
monitor: 30s
max_failure_ratio: 0.1
order: start-first
# develop:开发模式 watch 同步(spec develop.md)
develop:
watch:
- path: ./webapp/html # 同步静态文件
action: sync
target: /var/www
initial_sync: true
ignore:
- node_modules/
- path: ./webapp/src # 源码变化时重建
action: rebuild
- path: ./webapp/config # 同步并执行命令
action: sync+exec
target: /etc/config
include: ["*.conf"]
exec:
command: nginx -s reload
user: root
privileged: false
working_dir: /etc/nginx
environment:
RELOAD: "1"
# 环境变量来源
env_file: # 从文件加载环境变量
- path: ./default.env
required: true
- path: ./override.env
required: false
format: raw
environment: # 直接声明(优先于 env_file)
<<: *common-env # 通过 YAML merge 复用锚点
NODE_ENV: production
DEBUG: "false"
# expose:仅对其他容器暴露端口,不发布到宿主
expose:
- "3000"
- "8080-8085/tcp"
# ports:发布端口,长语法
ports:
- name: web # 端口可读名
target: 80 # 容器内端口
host_ip: 127.0.0.1 # 宿主绑定 IP
published: "8080" # 宿主端口(字符串以避免 base-60 浮点)
protocol: tcp
app_protocol: http
mode: host # host 或 ingress
- name: web-secured
target: 443
host_ip: 127.0.0.1
published: "8443"
protocol: tcp
app_protocol: https
mode: ingress
- "6060:6060/udp" # 短语法
# configs:在容器内挂载配置(spec 05 + 08)
configs:
- source: http_config # 长语法
target: /etc/nginx/nginx.conf
uid: "103"
gid: "103"
mode: 0440
- app_config # 短语法
# secrets:挂载敏感数据
secrets:
- source: server-certificate
target: server.crt
uid: "103"
gid: "103"
mode: 0o440
- api-token # 短语法
# networks:服务接入的网络与网络级细化(长语法)
networks:
front-tier:
aliases: # 网络内别名
- webapp
- www
ipv4_address: 172.16.238.10 # 静态 IPv4
ipv6_address: 2001:3984:3989::10 # 静态 IPv6
link_local_ips: # 链路本地 IP
- 169.254.10.1
mac_address: 02:42:ac:11:00:02 # 网络级 MAC
driver_opts: # 驱动专属参数
com.docker.network.endpoint.foo: "bar"
interface_name: eth0 # 容器内网卡名
priority: 1000 # 网络连接顺序
gw_priority: 10 # 默认网关选择优先级
back-tier:
aliases:
- webapp-internal
# extra_hosts:注入 /etc/hosts
extra_hosts:
- "somehost=162.242.195.82"
- "otherhost:50.31.209.229"
- "myhostv6=[::1]"
# external_links:链接外部容器
external_links:
- legacy-redis:redis
# links:服务间链接(实现相关)
links:
- backend:api
# DNS 相关
dns:
- 8.8.8.8
- 1.1.1.1
dns_opt:
- use-vc
- no-tld-query
dns_search:
- example.com
- corp.example.com
domainname: example.com
hostname: webapp.example.com
# 健康检查(复用锚点)
healthcheck: *default-healthcheck
# init:注入 PID 1 进程负责信号转发与僵尸进程回收
init: true
# labels:容器标签
labels:
com.example.description: "webapp frontend"
com.example.department: "Engineering"
# label_file:从文件加载标签
label_file:
- ./app.labels
- ./additional.labels
# logging:日志驱动(复用锚点)
logging: *default-logging
# 进程/资源限制类(与 deploy.resources 互补)
mem_limit: 512m
mem_reservation: 256m
mem_swappiness: 60
memswap_limit: 1g
oom_kill_disable: false
oom_score_adj: -500
pids_limit: 200
shm_size: "128mb"
# CPU 相关
cpu_count: 2
cpu_percent: 75
cpu_shares: 1024
cpu_period: 100000
cpu_quota: 50000
cpu_rt_runtime: "400ms"
cpu_rt_period: "1400us"
cpus: 0.5
cpuset: "0,1"
# Block IO 限制
blkio_config:
weight: 300
weight_device:
- path: /dev/sda
weight: 400
device_read_bps:
- path: /dev/sdb
rate: "12mb"
device_write_bps:
- path: /dev/sdb
rate: "1024k"
device_read_iops:
- path: /dev/sdb
rate: 120
device_write_iops:
- path: /dev/sdb
rate: 30
# Linux capabilities 增删
cap_add:
- NET_ADMIN
cap_drop:
- SYS_ADMIN
# cgroup 命名空间
cgroup: private
cgroup_parent: m-executor-abcd
# devices:宿主设备映射
devices:
- "/dev/ttyUSB0:/dev/ttyUSB0:rwm"
- "vendor1.com/device=gpu" # CDI 语法
# device_cgroup_rules:设备 cgroup 规则
device_cgroup_rules:
- "c 1:3 mr"
- "a 7:* rmw"
# group_add:容器内用户附加组
group_add:
- mail
- "1001"
# gpus:GPU 设备分配(简化语法,与 deploy.resources.devices 等价)
gpus:
- driver: nvidia
count: 1
# 命名空间
ipc: "shareable"
pid: "host"
uts: "host"
userns_mode: "host"
isolation: default
# mac_address:服务级 MAC(部分 runtime 拒绝,推荐用 networks.mac_address)
mac_address: 02:42:ac:11:65:43
# platform:目标平台
platform: linux/amd64
# profiles:声明该服务所属的 profile(spec 15 章节)
profiles:
- frontend
- prod
# 生命周期 hooks
pre_start: # 服务启动前的初始化容器(spec 05)
- command: ["./manage.py", "migrate"]
- image: busybox
command: sh -c 'chown -R 1000:1000 /data'
user: root
privileged: true
working_dir: /data
environment:
- INIT=1
per_replica: false
post_start: # 启动后钩子
- command: ./do_something_on_startup.sh
user: root
privileged: true
working_dir: /app
environment:
- FOO=BAR
pre_stop: # 停止前钩子(与 post_start 同结构)
- command: ./graceful_shutdown.sh
user: root
# 容器停止行为
stop_grace_period: 1m30s
stop_signal: SIGTERM
# 镜像拉取策略
pull_policy: every_12h
# 重启策略(简化版,与 deploy.restart_policy 互斥)
restart: unless-stopped
runtime: runc
# privileged 与 read_only
privileged: false
read_only: false
# scale:默认副本数(与 deploy.replicas 必须一致)
scale: 3
# security_opt:覆盖默认 labeling
security_opt:
- label:user:USER
- label:role:ROLE
- no-new-privileges:true
# storage_opt:存储驱动选项
storage_opt:
size: "1G"
# stdin_open + tty:分别开启 stdin 与 tty
stdin_open: true
tty: true
# sysctls:内核参数
sysctls:
net.core.somaxconn: 1024
net.ipv4.tcp_syncookies: 0
# tmpfs:临时文件系统
tmpfs:
- /run
- /var/cache:mode=755,uid=1009,gid=1009
# ulimits
ulimits:
nproc: 65535
nofile:
soft: 20000
hard: 40000
# use_api_socket:允许容器通过 API socket 操作容器引擎
use_api_socket: false
# user 与 working_dir
user: "1000:1000"
working_dir: /app
# volumes:长/短混合
volumes:
- type: volume # 命名卷长语法
source: app-data
target: /data
read_only: false
volume:
nocopy: true
subpath: sub
consistency: consistent
- type: bind # bind 长语法
source: ./host-config
target: /etc/app
read_only: true
bind:
propagation: rshared
create_host_path: true
selinux: z
- type: tmpfs # tmpfs 长语法
target: /tmp/cache
tmpfs:
size: 67108864
mode: 0o700
- type: image # image 卷长语法
source: example/seed-data:1.0
target: /seed
image:
subpath: payload
- app-data:/var/lib/data:rw # 短语法
# volumes_from:复用其他服务的全部卷
volumes_from:
- backend:ro
- container:legacy-redis:rw
# credential_spec:Windows gMSA 凭据
credential_spec:
config: gmsa_config
# models:引用顶级 models(AI 模型)
models:
my_model:
endpoint_var: MODEL_URL
model_var: MODEL_ID
# x- 扩展字段也可放在服务级
x-team: "platform"
# ---------------------------------------------------------------------------
# backend:演示 extends 复用、network_mode 互斥情形等
# ---------------------------------------------------------------------------
backend:
image: example/backend:2.0
# extends:从同/异文件复用另一个服务定义(spec 05 章节)
extends:
file: common-services.yaml
service: base-app
environment:
<<: *common-env
DB_HOST: db
networks:
- back-tier
volumes:
- db-data:/var/lib/postgresql/data
healthcheck: *default-healthcheck
logging: *default-logging
depends_on:
- db
- cache
# ---------------------------------------------------------------------------
# db:演示 secrets/configs 短语法、profile、最简服务
# ---------------------------------------------------------------------------
db:
image: postgres:16
environment:
POSTGRES_PASSWORD_FILE: /run/secrets/db-password
secrets:
- db-password # 短语法,默认挂到 /run/secrets/db-password
configs:
- my_other_config # 短语法
volumes:
- db-data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 10s
timeout: 3s
retries: 5
# ---------------------------------------------------------------------------
# cache:使用 network_mode(与 networks 互斥)演示
# ---------------------------------------------------------------------------
cache:
image: redis:7
# network_mode:none/host/service:xxx/container:xxx
network_mode: "service:backend"
# 注意:声明 network_mode 后不能再声明 networks
# ---------------------------------------------------------------------------
# migrator:一次性任务,被 depends_on.service_completed_successfully 等待
# ---------------------------------------------------------------------------
migrator:
image: example/migrator:1.0
command: ["./run-migrations.sh"]
restart: "no"
depends_on:
db:
condition: service_healthy
profiles:
- migrate # 仅在激活该 profile 时运行
# ---------------------------------------------------------------------------
# debugger:演示 profile 在调试场景下的使用
# ---------------------------------------------------------------------------
debugger:
image: nicolaka/netshoot
entrypoint: ["sleep", "infinity"]
network_mode: "container:webapp-frontend"
profiles:
- debug
# ---------------------------------------------------------------------------
# external-db:演示 provider,让 Compose 把生命周期托管给外部组件
# ---------------------------------------------------------------------------
external-db:
provider:
type: awesomecloud # 必填,第三方组件名
options: # provider 自定义键值
type: mysql
region: us-west-2
# ---------------------------------------------------------------------------
# ai-app:演示顶级 models 与服务级 models 关联
# ---------------------------------------------------------------------------
ai-app:
image: example/ai-app:1.0
models:
- ai_model # 短语法
# =============================================================================
# networks:顶级网络定义(spec 06 章节)
# =============================================================================
networks:
# default:可显式自定义默认网络
default:
name: full-spec-demo-default
driver_opts:
com.docker.network.bridge.host_binding_ipv4: 127.0.0.1
front-tier:
name: my-front-tier # 自定义名,不带项目前缀
driver: bridge # 网络驱动
driver_opts: # 驱动参数
com.docker.network.bridge.name: br-front
attachable: true # 允许独立容器加入
enable_ipv4: true
enable_ipv6: true
internal: false # true 表示外部隔离
ipam: # IPAM 配置
driver: default
config:
- subnet: "172.16.238.0/24"
ip_range: "172.16.238.0/26"
gateway: "172.16.238.1"
aux_addresses:
host1: "172.16.238.5"
host2: "172.16.238.6"
options:
foo: bar
labels:
com.example.network: "front"
back-tier: # 最简声明
driver: bridge
outside:
external: true # 已存在的外部网络
name: "${EXTERNAL_NETWORK_NAME:-outside}" # 演示 interpolation 与默认值
# =============================================================================
# volumes:顶级卷定义(spec 07 章节)
# =============================================================================
volumes:
# 演示锚点与 YAML merge(spec 10 fragments)
db-data: &default-volume
driver: local # 卷驱动
driver_opts: # 驱动选项
type: none
o: bind
device: /srv/db-data
labels:
com.example.volume: "db"
name: full-spec-demo-db # 自定义卷名
metrics:
<<: *default-volume # 复用并部分覆盖
name: full-spec-demo-metrics
app-data:
driver: local
shared-nfs:
driver_opts: # NFS 示例
type: "nfs"
o: "addr=10.40.0.199,nolock,soft,rw"
device: ":/exports/shared"
external-vol:
external: true # 外部托管
name: "${EXTERNAL_VOLUME_NAME:?must set EXTERNAL_VOLUME_NAME}" # 强制变量
# =============================================================================
# configs:顶级配置定义(spec 08 章节)
# =============================================================================
configs:
http_config:
file: ./httpd.conf # 来自文件
app_config:
content: | # 直接内联内容
debug=${DEBUG:-false}
project=${COMPOSE_PROJECT_NAME}
my_other_config:
environment: "APP_CONFIG_FROM_ENV" # 来自环境变量
gmsa_config:
file: ./gmsa-credential-spec.json # Windows gMSA 配置
external_http_config:
external: true # 外部已存在
name: "${HTTP_CONFIG_KEY}" # 实际查找名通过插值得到
# =============================================================================
# secrets:顶级敏感数据定义(spec 09 章节)
# =============================================================================
secrets:
server-certificate:
file: ./server.cert # 来自文件
api-token:
environment: "API_TOKEN" # 来自环境变量
db-password:
file: ./secrets/db_password.txt
external-cert:
external: true
name: "${CERTIFICATE_KEY}" # 平台外部 secret
# =============================================================================
# models:顶级 AI 模型定义(spec models.md,Compose v2.38.0+)
# =============================================================================
models:
ai_model:
model: ai/llama3 # OCI 模型工件标识,必填
my_model:
model: ai/mistral
context_size: 4096 # 上下文 token 数
runtime_flags: # 推理引擎运行参数
- "--temperature=0.7"
- "--top-p=0.9"
Docker in Docker (DinD)
应用场景:
- CI/CD:
底层容器一般都是特权容器,但是上层容器一般不是无根容器,技术上来讲可以是普通容器甚至可以是特权容器。
容器网络
这篇文档写的不错:https://quant67.com/post/containers/11-network-perf/network-perf.html。
容器网络的实现可以基于以下几种方案:
- veth pair^,也就是桥接模式;
- macvlan^。
是使用 veth pair 而不是 TUN/TAP 来实现的,可以看 veth pair^。因为不需要给用户态暴露接口。
也可以基于 macvlan 来实现(性能会比 veth pair 更好一些,性能几乎等于裸机)。
https://zhuanlan.zhihu.com/p/364886965
同一个 Pod 里的所有容器共享同一张网卡(准确说是共享同一个网络命名空间里的所有网络接口)。因为共享了同一张网卡,因此也共享同一个 IP。
k8s 集群里的 IP 分配不是通过一个专门的 DHCP Server 来分配的,而是由集群内部的 IP 地址管理(IPAM) 组件分配。
Pod 之间或者说容器之间有自己的网络和网段,请问是怎么进行路由的呢?
同一台宿主机:使用网桥。
不同的宿主机上的两个 Pod 进行通信:需要 CNI 插件负责跨主机路由。然后 CNI 插件可以通过 VXLAN 的方式进行路由。
Veth pair
veth pair 是一对“连在一起”的虚拟网卡,从一个设备发进去的数据包,会立刻从另一个设备收到,就像一根网线的两端。主要作用:连接不同的网络命名空间 (Network Namespace)。
宿主机上也能看到容器中的网卡,所以很多时候你能看到宿主机上出现了很多网卡比如 veth* docker* 这种命名规则,其实都是 veth pair。因为容器被赋予了 network namespace,只能看到 network namespace 里的网卡,也就是对应的那个 veth。
Docker 启动容器时,会创建一对 veth:
- 一端保留在容器自己的 network namespace 里,通常命名为 eth0,并配置容器 IP。
- 另一端插在宿主机的 Docker 网桥(比如 docker0)上。
容器通过 eth0 -> veth pair -> docker0 bridge -> 宿主机网卡/路由,实现与外界的通信。
容器 eth0,宿主机上 veth 和 宿主机上物理网卡接口 eth 使用的不是同一个 Mac 地址。但是最后发出去的包 Mac 地址是物理网卡的 Mac 地址,因为地址被内核协议栈改写了。
veth pair 的两端必须要分别关联一个 network namespace 吗?
不是。它的两端完全可以根据实际需求灵活放置:
- 两端均不关联:veth pair 的两端都可以保留在默认的 Root Network Namespace 中,作为普通的虚拟网卡设备使用;
- 一端关联,一端不关联:一端在新建的,另一端则留在 Root,并通常与网桥(Bridge)连接。这是 Docker 等容器技术的标准网络模式,用于实现容器与宿主机、容器与外界的通信;
- 两端分别关联到不同 namespace:veth pair 最广为人知的用途,是作为一根 “虚拟网线”,将两个独立的 network namespace 连接起来。通过这种方式,可以实现两个隔离网络环境之间的直接通信。
经过 veth pair 还要走协议栈吗?
仍然要走协议栈,你可能会问,直接把 veth0 的应用层报文转发路由到 veth1 就好了把,跳过协议栈可以大幅提升性能吧。
这是因为协议处理不一定是在 veth1 上的应用处理,可能 veth1 接了一个 bridge,然后这个带协议栈各层报文的包就通过 bridge 转发走了,在另一台主机上的网卡以及协议栈处理了。
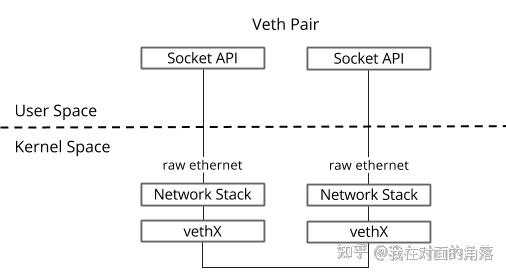
整个过程不涉及 TUN/TAP 设备。为什么呢?
- veth 网卡:数据包从 A 卡出去,直接出现在对端 B 卡的接收队列(就像一根网线的两头)。整个搬运工作由内核网络栈在内核空间完成,不需要任何用户态程序参与。
- TUN/TAP 网卡:数据包从网卡出去(或从内核协议栈送到网卡),会被送进用户态程序打开的那个字符设备文件(如
/dev/net/tun),这样子像 clash 这种用户态程序才能从这里接收用户请求进行代理转发。如果没有任何用户态程序去读/写这个设备,数据包就会永远堵在那里,容器侧得到的感受就是网络不通。
核心区别是 veth 是两张虚拟网卡连接、TUN/TAP 是虚拟网卡和用户态程序连接。
Network Namespace (netns)
macvlan
是一个 Linux kernel 的特性,一般是以内核模块的形式存在。是一个网络虚拟化的解决方案(但是其实和我们平时用的 VirtIO 啥的方案还不太一样)。macvlan 可以把一张物理网卡虚拟化成多张虚拟网卡:
- 因为是内核特性,理论上来说,内核可以创建无限个 macvlan 来使用;
- 对网卡也没有要求,不需要网卡硬件支持任何虚拟化的功能。唯一一个要求,就是网卡需要支持混杂模式^,但是这个大多数网卡其实都是支持的。
macvlan 会根据收到包的目的 MAC 地址判断这个包需要交给哪个虚拟网卡,虚拟网卡再把包交给上层的协议栈处理:
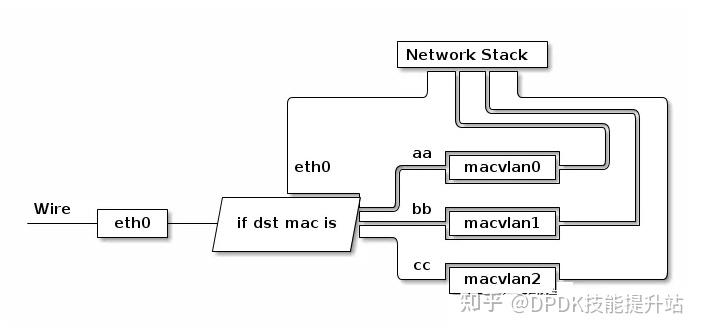
1. macvlan 会绕过宿主机的内核网络栈吗?
内核通用网络栈(排除了网卡驱动)主要处理三层:TCP 层、IP 层和 MAC 层,macvlan 因为是一个内核模块,它绕过了 TCP 层和 IP 层。MAC 层其实还是靠内核网络协议栈来进行处理的。因为 macvlan 需要有自己的 MAC,所以才没有绕过内核网络协议栈的 MAC 层,需要借助这一层的能力来进行 MAC 的封装以及最后和物理网卡的交互,这也是这个技术叫做 macvlan 的原因。
2. macvlan 创建出来的网络设备一般都叫什么名字?
一般就是比如 macvlan0 这种形式的网卡名称。
3. macvlan 虚拟网卡如何和宿主机网卡进行通信?
问题其实是可以转换为:宿主机上和容器里的两个 App 能互相通过网络访问吗?
默认 macvlan 的虚拟网卡和宿主机网卡之间是没有办法直接通信的。
你会认为,开了混杂模式,宿主机发的包出去转一圈又被自己网卡接收到,自己网卡收到后判断 Mac 发现是 macvlan 然后包交上去。
真实是:一张物理网卡维护了一个 MAC 地址列表(主 MAC + 所有 macvlan 子接口的附加 MAC)。当宿主机向 macvlan 的子接口的 MAC 发送帧时,网卡硬件会检查目的 MAC。网卡认为“这是发给我的”,直接在芯片内部把帧从发送队列转到接收队列,就是内部环回,并不会发出去,接着这个帧的接收队列会被丢弃。
混杂模式 / Promiscuous Mode
混杂模式一个非常重要的场景就是支持基于 macvlan 的容器网络,所以把它放在了这部分。
- 没有开启时的默认行为:它只接收并处理目标 MAC 地址正好是自己的数据帧。如果看到一个帧不是给自己的,它就直接在硬件层面丢弃,系统内核根本感觉不到;
- 开启后监听一切:它会把所有能从网线上“听到”的数据帧都收下,完整地交给上层的系统内核去处理,无论这些帧是发给谁的。
基于 veth pair 的容器网络不需要开启混杂模式:因为我们在往外发送的时候,只需要用物理网卡的 Mac 地址就好了(内核协议栈会改写为物理网卡的 Mac)。
基于 macvlan 的容器网卡,绕过了宿主机内核的 IP 协议栈(三层),是经过 macvlan 驱动直接转发的。
ipvlan 其实也不需要开启混杂模式。
ipvlan
和 macvlan 比较相似的地方:
- 也是一种网卡虚拟化的方式,和
macvlan一样,展示一个网卡接口出来; - 也是一个内核模块;
- 也是 bypass 了一部分网络协议栈。
和 macvlan^ 的最直观的区别在于,ipvlan 其实是共享了网卡的 mac 地址,也就是所有容器都使用了网卡的同一个 mac 地址;而 macvlan 是每一个虚拟网卡都有自己的 mac 地址。
- ipvlan 可以直接和宿主机进行通信,而 macvlan 不能^:好像是内核网络栈会充当路由器,在本地进行路由?
- macvlan 需要开启混杂模式来监听所有 Mac 帧,但是 ipvlan 其实不需要进行监听,因为 Mac 已经复用了。
ipvlan 的网卡命名规则是什么?
ipvl1, ipvl1 这种。
容器存储
Container 的容器层在每次 run 的时候会被持久化吗。
UnionFS / OverlayFS
Union 在英语里是并集的意思,正如其名字,UnionFS 相当于对各层的文件系统进行了一个并集。
UnionFS 是一个抽象概念,它的一个具体实现叫做 OverlayFS。
OverlayFS 是如何实现容器存储的?
OverlayFS 支持多个 lowerdir 和一个 upperdir(可选) 和一个工作目录 workdir(可选)。
mount -t overlay overlay -o lowerdir=/high_priority:/medium:/low_priority,upperdir=/upper,workdir=/work /merged
如果想要这个 FS 是可写的,那么就需要 upperdir 和 workdir,两者缺一不可。
只要你以可读写模式挂载 OverlayFS(即同时指定了 upperdir 和 workdir),整个合并后的文件系统对用户来说就是完全可写的,无论 upperdir 最初是否为空,也无论它是否包含了 lowerdir 中的文件。
你无法为某个 lowerdir 或 upperdir 单独指定一个“挂载位置”,比如让 /layerA 只覆盖合并视图里的 /usr,而 /layerB 覆盖 /etc。OverlayFS 的工作方式是将每个目录都以完整的目录树形式参与合并,对齐点是根目录 /。
多个 lowerdir 中存在同名文件时,最终在合并视图中看到的是优先级最高的那个 lowerdir 中的版本。
OverlayFS 并不要求 upperdir “覆盖” lowerdir 中的内容。挂载时,upperdir 完全可以是一个空目录,这恰恰是最常见的用法。
- 读取:如果文件只存在于 lowerdir,就从 lowerdir 读取;如果 upperdir 中也有同名文件,则以 upperdir 中的版本为准(覆盖 lowerdir)。
- 写入/修改:
- 当你修改一个只存在于 lowerdir 的文件时,OverlayFS 会自动触发 copy-up:先将该文件从 lowerdir 原样复制到 upperdir(保持目录结构),然后在 upperdir 的副本上进行修改。lowerdir 中的原始文件保持不变。
- 当你创建一个新文件或新目录时,会直接创建在 upperdir 中。
- 当你删除一个文件时,如果文件只存在于 lowerdir,会在 upperdir 中创建一个特殊的“whiteout”文件,使该文件在合并视图中隐藏,而 lowerdir 原文件不受影响。
fuse-overlayfs
OverlayFS 本身是实现在内核中的。
fuse-overlayfs 可以把 Overlay 的逻辑实现在用户态,最主要的好处是:无需特权,支持“无根”(Rootless)容器。
无根容器(Rootless Container)/ 特权容器(Privileged Container)
容器可以有三种形态,从权限级别依次上升:
- 无根容器:
- 普通容器:
- 特权容器:
容器内用户 ID 和容器外用户 ID 的关系
我们进入容器后,经常能看到容器里面我们的用户名是 root,这个容器里面的 root 就是容器外面(宿主机上的)root 用户吗?是的。绝大多数你接触的 Docker 容器都是这种模式:
- 容器内的 root 用户,UID 就是 0。
- 宿主机上的 root 用户,UID 也是 0。
- 因为宿主机和容器共享同一个内核,而内核只认 UID 数字,不认名字。
无根容器
什么是无根容器:
- 容器内看到的还是 root;
- 连 Docker 守护进程本身都以普通用户身份运行,完全不需要宿主机的 root 权限;
- 底层利用 user_namespaces、rootlesskit 等技术,让普通用户也可以创建容器、挂载文件系统等。
- 容器内看到的 root,实际上被映射为该普通用户所拥有的子 UID/GID(通过 /etc/subuid 分配)。
应用场景:
- 安全:能让普通用户(非 root)在主机上运行和管理容器,即使容器被攻破,攻击者也无法获得宿主机的 root 权限;
- CI/CD 流水线:在自动化构建、测试和部署的流水线中,无根容器能以最小权限运行任务,缩小攻击面,提升整个交付流程的安全性。
- 将 dockerd 守护进程也以非 root 用户运行,是 Rootless Docker 模式的核心,其根本目的是彻底消除 Docker 自身可能成为攻击跳板的隐患。传统的 Docker 模式中,dockerd 守护进程以 root 权限运行。这意味着,任何能连接到 Docker 守护进程的用户或服务,都可能通过 Docker API 间接获得宿主机 root 权限。这相当于在系统上留下了一个巨大的安全隐患。
特权容器
特权容器是一种具有主机的所有功能的容器,它解除了常规容器的所有限制。注意并不是虚拟机。
实际上,这意味着特权容器可以执行几乎所有可以直接在主机上执行的操作,特权容器就是提权的进程,See Linux capabilities^。
Memcg / Memory Cgroup
What will happen when exceed memory cgroup limit?
当 memory cgroup 用超之后,是会发生 OOM 并 kill 掉进程还是会 swap 这个进程的内存出去?
My model of memory limits on cgroups was always “if you use more than X memory, you will get killed right away”. It turns out that that assumptions was wrong! If you use more than X memory, you can still use swap!
And apparently some kernels also support setting separate swap limits. So you could set your memory limit to X and your swap limit to 0, which would give you more predictable behavior. Swapping is weird and confusing.
怎么样去设置 swap limit 呢?
kernel.org/doc/Documentation/cgroup-v1/memory.txt 这里提到:memory+swap usage can be accounted and limited.
memory.limit_in_bytes # set/show limit of memory usage
memory.memsw.limit_in_bytes # set/show limit of memory+Swap usage
上面两个可以控制 memory limit 和 swap limit 分别是多少。
Swapping, memory limits, and cgroups
Cgroup
这篇文章讲的不错,很适合入门和看一些 high level 的东西:Linux资源管理之cgroups简介 - 美团技术团队。
术语 cgroup 在不同的上下文中代表不同的意思,可以指整个 Linux 的 cgroup 技术,也可以指一个具体进程组。
一个 cgroup 在不同的子系统之间是相同的吗?比如说我这个 cgroup 有 5 个进程,希望他们在 CPU 使用上共享一个 quota,但是如果切换到内存子系统,那么可能我们希望其中两个进程和这个 cgroup 之外的进程 share memory,所以就不存在一个 cgroup 能包含这 5 个进程了,cgroup 的实现和使用支持这种方式吗,还是说不同子系统的 cgroup 其实也是不一样的?实验了一下,改一个子系统下的 cgroup,比如说在 cpu/kubepods/tasks 下加入一个 pid,memory/kubepods/tasks 下面是没有的,所以不同的树下应该是不同的 cgroup?
- cgroup v2 下的 cgroup 应该是相同的。因为其配置结构就是 cgroup 文件下配子系统;
- cgroup v1 下是允许不同树下有不同 cgroup 的。这是 cgroup v1 相比于 v2 更加灵活的地方。
也就是说,cgroup v1 下的 cgroup 概念和 cgroup v2 是不一样的,前者是一个更小的概念,表示一个层级下面的 cgroup,而后者可以包含多个层级。
cgroup 是 Linux 下的一种将进程按组进行管理的机制,在用户层看来,cgroup 技术就是把系统中的所有进程组织成许多独立的层级树,每棵树都包含系统的所有进程,树的每个节点是一个进程组 cgroup,而每颗树又和一个或者多个 subsystem(也可以没有)关联,树的作用是将进程分组,而 subsystem 的作用就是对这些组进行操作。为了更好地理解这个概念,我们可以用一个类比来帮助理解。
- 一个 subsystem 只能同时属于一个层级树 (hierarchy)。例如 memory 子系统不能同时属于两个层级树,也就是说 subsystem 到层级树之间是多对一的映射关系。
- 在每个树中,一个 task 只能属于其中一个 cgroup,当添加 task 到新的 cgroup 时,会默认从旧的 cgroup 中移除。但是一个 task 可以同时存在于不同的树中。
subsystem 和资源是对应的,每个子系统都负责管理系统的某个特定资源,比如用于内存管理的 memory 子系统,用于 CPU 时间分配的 CPU 子系统等。
Linux Cgroup 入门教程:基本概念 · 云原生实验室
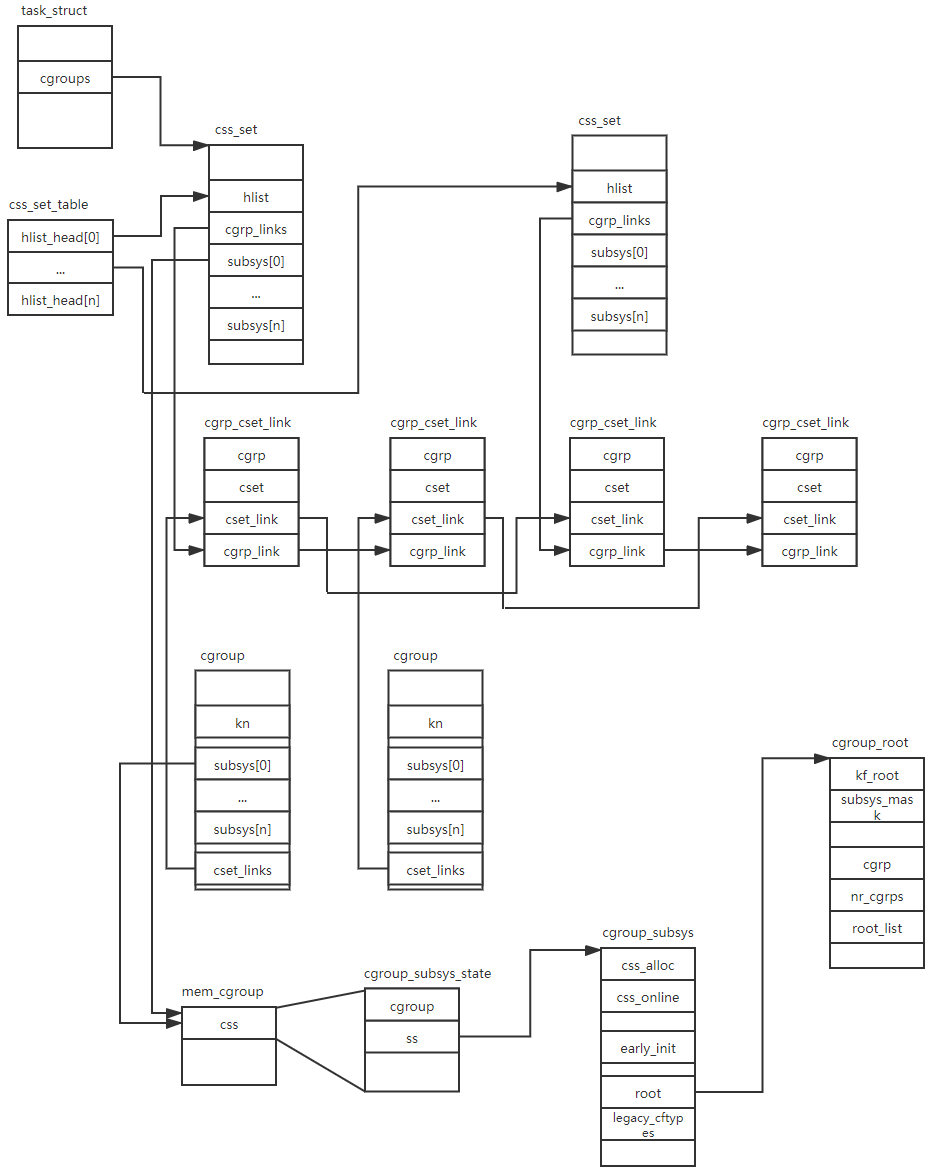
核心数据结构类图:
tasks 和 cgroup.proc 的区别
tasks 文件:
- 用途: 列出当前 cgroup 中所有的进程,包括其所有的线程。
- 使用场景: 如果你需要看到 cgroup 中的所有任务,包括每个进程的各个线程,那么应查看 tasks 文件。
- 内容: 包含每个任务(包括主线程及其子线程)的 PID。
cgroup.procs 文件:
- 用途: 列出当前 cgroup 中的所有进程和线程组的 leader 进程,但不包括单独的线程(只列出线程组的主进程)。
- 使用场景: 如果你只需要看到进程级别的信息,而不需要查看每个线程的详细信息,那么应查看 cgroup.procs 文件。
- 内容: 只包含每个进程的 PID(即线程组的 leader)。
tasks 更详细: 显示每个进程和它们的所有线程。 用于更细粒度的资源管理和监控。
Processes in container
一个容器一般来说有一个主进程,但是也有可能有一些辅助进程,比如 crond, light, sshd, ld-linux-x86-64, systemd-journal。这个在对应的 /sys/fs/cgroup/cpu/kubepods/pod…/<container hash>/cgroup.procs 能够看到对应的 pid。
一般来说如何定位哪一个是容器的主进程呢?进到容器里面直接 ps -A 看 TIME 这一列表示使用掉的 CPU 时间,最大的那个应该就是。
cpu.shares
- nice value 是针对一个进程的权重设置,a nice value applies to a task, that is a process or threada nice value applies to a task, that is a process or thread;
- shares 是针对一个进程组的权重设置,a "CPU shares" value applies to a task group。
Share 值和内核里面的 Weight 值是同一个单位。
static struct cftype cpu_legacy_files[] = {
//...
{
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
},
//...
}
// 找到对应的 task_group
sched_group_set_shares(css_tg(css), scale_load(shareval));
sched_group_set_shares
__sched_group_set_shares
// 因为已经 scale_load() 了,所以和 load 是一个量纲了
tg->shares = shares;
for_each_possible_cpu(i)
for_each_sched_entity(se)
update_cfs_group
shares = READ_ONCE(gcfs_rq->tg->shares);
shares = calc_group_shares(gcfs_rq);
// 会把这个 task_group 上的 share 值设置到这个
// task_group 对应的每一个 cfs_rq 对应的每一个 schedule entity
// 的 weight 值上。
reweight_entity(cfs_rq_of(se), se, shares);
cgroup_idle
cpuset,cpu,cpuacct / CPU isolation
-
cpuset: allows you to assign individual CPUs (or groups of CPUs) and memory nodes to cgroups. This is useful for controlling which CPUs a set of processes can execute on and from which memory nodes they can allocate memory, effectively confining the processes to specific hardware resources. It's often used to improve performance for applications that benefit from being restricted to specific CPUs, especially in a multi-core system, enhancing cache locality. 指定的 cgroup 只能跑在cpuset分组里的 CPU 区间,但是其他 cgroup 仍然可以跑在这些 CPU 上。 -
cpu: used to share CPU time between cgroups. You can set the CPU shares for each cgroup, influencing how much CPU time a group's processes receive relative to others when the system is under full load. Additionally, you can set CPU limits and quotas to enforce absolute limits on CPU usage over defined periods, which is important for ensuring that no single group can monopolize the CPU. 这个其实就是用来限制 cgroup CPU 使用率的。 -
cpuacct: provides accounting for CPU usage in cgroups. It tracks CPU time consumed by the group's processes, helping monitor and analyze application behavior, load balancing, and performance tuning. With cpuacct, you can obtain detailed statistics about CPU usage, which can aid in making informed decisions about resource allocation.
cgroup 的 CPU set 和 task set 其实都是一样的。
Cgroup in sysfs / cgroupfs
表现在操作界面就是 sysfs 里可以进行配置。
Mount on /sys/fs/cgroup/:
CPU 子系统常见配置:
-
/sys/fs/cgroup/cpuset,cpu,cpuacct/cpu.shares: 表示一个 CPU 的资源被分成了多少份。cpu.shares用来设置 CPU 的相对值,并且是针对所有的 CPU,默认值是 1024 等同于一个 cpu 核心。 CPU Shares 将每个核心划分为 1024 个片,并保证每个进程将按比例获得这些片的份额。如果有 1024 个片 (即 1 核),并且两个进程设置 cpu.shares 均为 1024,那么这两个进程中每个进程将获得大约一半的 cpu 可用时间。 所以这个cpu.shares其实也是一个保证的上限而不是下限。k8s 的一个 pod 对于 CPU 的 request 应该反映到内核 cgroup 上就是cpu.shares.
简单的使用:控制组简介 · Linux 内核揭秘@Js中文网-免费编程书籍
Namespace in Linux
Namespaces provide isolation of system resources, and cgroups allow for fine‑grained control and enforcement of limits for those resources.
- Cgroups = limits how much you can use;
- namespaces = limits what you can see (and therefore use).
namespace 和 cgroup 之间并不是前辈和后继者的关系,两者是可以同时用的。
Namespaces are a feature of the Linux kernel that partition kernel resources such that one set of processes sees one set of resources, while another set of processes sees a different set of resources.
struct task_group
// Task group related information
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se;
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq;
unsigned long shares;
/* A positive value indicates that this is a SCHED_IDLE group. */
int idle;
#ifdef CONFIG_SMP
/*
* load_avg can be heavily contended at clock tick time, so put
* it in its own cacheline separated from the fields above which
* will also be accessed at each tick.
*/
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
#ifdef CONFIG_UCLAMP_TASK_GROUP
/* The two decimal precision [%] value requested from user-space */
unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */
struct uclamp_se uclamp_req[UCLAMP_CNT];
/* Effective clamp values used for a task group */
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
};
Resource control in cgroup
配置的地方在:sys/fs/cgroup/cpu/cpu.cfs_period_us,如果要具体到某一个 cgroup,只能
-
cpu.cfs_period_us: If tasks in a cgroup should be able to access a single CPU for 0.2 seconds out of every 1 second, setcpu.cfs_quota_usto 200000 andcpu.cfs_period_usto 1000000. The upper limit of thecpu.cfs_quota_usparameter is 1 second and the lower limit is 1000 microseconds. -
cpu.cfs_quota_us: As soon as tasks in a cgroup use up all the time specified by the quota, they are throttled for the remainder of the time specified by the period. Note that the quota and period parameters operate on a CPU basis. To allow a process to fully utilize two CPUs, for example, setcpu.cfs_quota_usto 200000 andcpu.cfs_period_usto 100000.
如何设置某一个 cgroup 对应的值呢?/sys/fs/cgroup/cpuset,cpu,cpuacct/<container>/cpu.cfs_period_us
struct task_group
Difference between cgroup and namespace in Linux
cgroup 和 namespace 类似,也是将进程进行分组,但它的目的和 namespace 不一样,namespace 是为了隔离进程组之间的资源,而 cgroup 是为了对一组进程进行统一的资源监控和限制。
In short:
- Cgroups = limits how much you can use;
- namespaces = limits what you can see (and therefore use)
这是两个平行互补的机制,也就是说,可以只使用 cgroup 也可以只使用 namespace,一个决定进程能不能看见资源,一个决定能用多少资源。
linux - difference between cgroups and namespaces - Stack Overflow
Cgroup 常用命令 / cgcreate / cgexec / cgget / cgset
cgclassify -- cgclassify命令是用来将运行的任务移动到一个或者多个cgroup。
cgclear -- cgclear 命令是用来删除层级中的所有cgroup。
cgconfig.conf -- 在cgconfig.conf文件中定义cgroup。
cgconfigparser -- cgconfigparser命令解析cgconfig.conf文件和并挂载层级。
cgcreate -- cgcreate在层级中创建新cgroup。
cgdelete -- cgdelete命令删除指定的cgroup。
cgexec -- cgexec命令在指定的cgroup中运行任务。
cgget -- cgget命令显示cgroup参数。
cgred.conf -- cgred.conf是cgred服务的配置文件。
cgrules.conf -- cgrules.conf 包含用来决定何时任务术语某些 cgroup的规则。
cgrulesengd -- cgrulesengd 在 cgroup 中发布任务。
cgset -- cgset 命令为 cgroup 设定参数。
lscgroup -- lscgroup 命令列出层级中的 cgroup。
lssubsys -- lssubsys 命令列出包含指定子系统的层级
举个例子:
# 创建 CPU cgroup
cgcreate -g cpu:/freeze_test
# 查看刚刚创建的 cgroup
ls /sys/fs/cgroup/cpu/freeze_test
# 查看当前 cgroup 设置
cgget -g cpu:freeze_test
# 限制 CPU 使用率 10%
cgset -r cpu.cfs_period_us=100000 freeze_test
cgset -r cpu.cfs_quota_us=10000 freeze_test
# 使用设置的 CPU cgroup 来运行 python
cgexec -g cpu:freeze_test python3
# 在解析器中执行:
while True: a=1+1
lssubsys / Linux cgroup 子系统 / Linux cgroup subsystem
这个是 cgroup 专有的概念。 A subsystem is a kernel component that modifies the behavior of the processes in a cgroup. Various subsystems have been implemented, making it possible to do things such as limiting the amount of CPU time and memory available to a cgroup, accounting for the CPU time used by a cgroup, and freezing and resuming execution of the processes in a cgroup.
Subsystems are sometimes also known as resource controllers (or simply, controllers).
$lssubsys
cpuset,cpu,cpuacct
blkio
memory
devices
freezer
net_cls,net_prio
perf_event
hugetlb
pids
rdma
每个 cgroup 子系统是否被支持均与相关配置选项有关。例如,cpuset 子系统应该通过 CONFIG_CPUSETS 内核配置选项启用,io 子系统通过 CONFIG_BLK_CGROUP 内核配置选项等。所有这些内核配置选项都可以在 General setup → Control Group support 菜单。
看起来子系统和有哪些 cgroups 是正交的概念。
-
cpu子系统cpu/kubepods/控制每一个 pod 的限额; -
cpuset子系统cpuset/kubepods控制每一个 pod 设置的 CPU 区间; -
cpuacct子系统cpuacct/kubepods控制每一个 pod 对应的统计信息。
可以进入到每一个的目录下面 ls:
-
/sys/fs/cgroup/cpu/kubepods/besteffort; -
/sys/fs/cgroup/cpuset/kubepods/besteffort; -
/sys/fs/cgroup/cpuacct/kubepods/besteffort。
会发现 pods 的 id 都是一样的。
Linux cgroup subsystem controller 联合挂载
linux 系统通常已经将多个 controller 挂载在 /sys/fs/cgroup 目录中了,下面的例子用另一个目录演示。
将多个 controller 挂载到同一个目录,如下:
mkdir -p /tmp/cgroup/cpu,cpuacct
# 同时挂载多个子系统
sudo mount -t cgroup -o cpu,cpuacct none /tmp/cgroup/cpu,cpuacct
# 可以一次挂载所有的controller
mount -t cgroup -o all cgroup /tmp/cgroup
有时候 ls /sys/fs/cgroup 可以看到三个子系统并不是分开的,比如可能会看到 cpuset,cpu,cpuacct 目录,这是因为三个子系统联合挂载了,可配置项还是不变的,比如说在这个目录下面还是可以看到 cpu., cpuset., cpuacct. 等等配置项。
联合挂载的一个好处就是直接指定一个挂载的目录就可以了,当然每一个子系统也是可以分开挂载的。
Cpuacct 子系统
CPU accounting,显示 cgroup 中任务所使用的 CPU 资源,其中包括子群组任务。报告有两大类:
- usage: 统计 cgroup 中进程使用 CPU 的时间,单位为纳秒。
- stat: 统计 cgroup 中进程使用 CPU 的时间,单位为
USER_HZ。
(注意,统计的都是此 cgroup 中所有任务以及子孙层级中的所有任务的)
usage*:
-
cpuacct.usage: 使用 CPU 的总时间(纳秒),该文件时可以写入 0 值的,用来进行重置统计信息。 -
cpuacct.usage_user: 使用用户态 CPU 的总时间(纳秒)。 -
cpuacct.usage_sys: 使用内核态 CPU 的总时间(纳秒)。 -
cpuacct.usage_percpu: 在每个 CPU 使用 CPU 的时间(纳秒)。 -
cpuacct.usage_percpu_user在每个 CPU 上使用用户态 CPU 的时间(纳秒)。 -
cpuacct.usage_percpu_sys:在每个 CPU 上使用内核态 CPU 的时间(纳秒)。 -
cpuacct.usage_all:详细输出文件cpuacct.usage_percpu_user和cpuacct.usage_percpu_sys的内容。
stat*:
-
cpuacct.stat:使用的 user 和 sys CPU 时间,方式如下:- user: user 中任务使用的 CPU 时间
- system: sys 中任务使用的 CPU 时间
- 其单位为
USER_HZ
阿里龙蜥操作系统专有:
-
cpuacct.sched_cfs_statistics:CFS 相关数据统计,例如运行时间,等待同级/非同级 cgroup 的时间等。 -
cpuacct.wait_latency:进程在队列中等待的延迟分布。
除此之外也有 cpu.stat 有便于统计的信息:
nr_periods 0
nr_throttled 0
throttled_time 0
wait_sum 6250967972385
current_bw 18446744073709551615
nr_burst 0
burst_time 0
Cgroup之cpuacct子系统 - Notes about linux and my work
cpuacct.proc_stat: 包含与 proc 文件系统中 /proc/stat 类似的 CPU 使用统计信息,单位是 ticks,
throttled_time
Cgroup 中的进程被限制使用 CPU 的总用时。其实就是 throttle_cfs_rq() 函数到 unthrottle_cfs_rq() 函数之间的时间。
throttle_cfs_rq
cfs_rq->throttled = 1;
// 记录时间
cfs_rq->throttled_clock = rq_clock(rq);
unthrottle_cfs_rq
// 当前时间减去当时记录的时间
cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock;
struct cgroup Kernel
表示一个 cgroup 节点,可以被不同的层级树中的对应节点指向,可以看函数 cgroup_css()。
这是一个更加通用的结构体,和 cpu, mem 等等子系统无关,所以里面其实是不适合放 task_group 相关的 field 的,因为和调度的相关性太大了。
struct cgroup {
// 这个表示挂载在 null subsystem 上的,会重新指回这个 cgroup,不重要,可能是为了代码实现考虑?
struct cgroup_subsys_state self;
// 这个 cgroup 在不同子系统下的控制方案
struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];
}
struct css_set Kernel
A css_set is a structure holding pointers to a set of cgroup_subsys_state objects.
struct cgroup_subsys Kernel
表示一个子系统。
/*
* Control Group subsystem type.
* See Documentation/admin-guide/cgroup-v1/cgroups.rst for details
*/
struct cgroup_subsys {
struct cgroup_subsys_state *(*css_alloc)(struct cgroup_subsys_state *parent_css);
//...
int id;
// 名字,比如 memory, cpu 等等
const char *name;
//...
};
struct cgroup_subsys_state Css Kernel
对应一个 cgroup,对应一个 subsytem,表示一个 subsystem 对应的某一个 cgroup,简称一个 css。
表示一个 cgroup 在某一个/几个子系统上的具像化。
所有的此结构体组成了一个树形的结构,应该就是对应层级树。
struct cgroup_subsys_state {
/* PI: the cgroup that this css is attached to */
// 对应哪一个 cgroup
struct cgroup *cgroup;
/* PI: the cgroup subsystem that this css is attached to */
// 对应哪一个 subsystem
struct cgroup_subsys *ss;
/* reference count - access via css_[try]get() and css_put() */
struct percpu_ref refcnt;
/* siblings list anchored at the parent's ->children */
struct list_head sibling;
struct list_head children;
/* flush target list anchored at cgrp->rstat_css_list */
struct list_head rstat_css_node;
/*
* PI: Subsys-unique ID. 0 is unused and root is always 1. The
* matching css can be looked up using css_from_id().
*/
int id;
/* number of procs under this css and its descendants */
int nr_procs;
unsigned int flags;
/*
* Monotonically increasing unique serial number which defines a
* uniform order among all csses. It's guaranteed that all
* ->children lists are in the ascending order of ->serial_nr and
* used to allow interrupting and resuming iterations.
*/
u64 serial_nr;
/*
* Incremented by online self and children. Used to guarantee that
* parents are not offlined before their children.
*/
atomic_t online_cnt;
/* percpu_ref killing and RCU release */
struct work_struct destroy_work;
struct rcu_work destroy_rwork;
CK_KABI_RESERVE(1)
CK_KABI_RESERVE(2)
CK_KABI_RESERVE(3)
CK_KABI_RESERVE(4)
/*
* PI: the parent css. Placed here for cache proximity to following
* fields of the containing structure.
*/
struct cgroup_subsys_state *parent;
};
Cgroup v2
代码上,cgroup v2 并不是另外设计了一套代码,而是基于 cgroup v1 进行重构的。所以相当于一套代码支持了 v1 和 v2 的两套逻辑。
Cgroup v1 和 v2 的区别
v1 一般长这样(不同的子系统是不同的目录):
[root@localhost zorro]# mount
......
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
来看一下 cgroup v2 的目录树结构:
[root@localhost zorro]# ls -p /sys/fs/cgroup/
cgroup.controllers cgroup.stat cpuset.cpus.effective machine.slice/
cgroup.max.depth cgroup.subtree_control cpuset.mems.effective memory.pressure
cgroup.max.descendants cgroup.threads init.scope/ system.slice/
cgroup.procs cpu.pressure io.pressure user.slice/
主要的区别在于这个文件:cgroup.controllers。这个文件显示了当前 cgoup 可以限制的相关资源有哪些?v2 之所以叫 unified,除了在内核中实现架构的区别外,体现在外在配置方法上也有变化。比如,这一个文件就可以控制当前 cgroup 都支持哪些资源的限制。而不是像 v1 一样资源分别在不同的目录下进行创建相关 cgroup。
默认创建出来的 zorro 组中的 cgroup.controllers 内容为:
[root@localhost cgroup]# cat zorro/cgroup.controllers
memory pids
还有一个文件叫做 cgroup.subtree_control,子层级的 cgroup 资源限制范围被上一级的 cgroup.subtree_control 文件内容所限制。
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。