2023-03 Monthly Archive
Perl one line
Cover - Perl one-liners cookbook
/etc/passwd
Understanding /etc/passwd File Format - nixCraft
Yum/DNF 使用
# 查看安装的源
sudo dnf repolist enabled
# 安装一个 repo 到 /etc/yum.repos.d/
# the url should contain the repodata/ folder
sudo dnf config-manager --add-repo <url>
# change filename, id (the first line) and the repo name
sudo vim /etc/yum.repos.d/<name>.repo
sudo dnf makecache
# search a package from a specified repo
sudo dnf search qemu-kvm --disablerepo=\* --enablerepo=<repo_id>
# install a package from a specified repo
# Don't use --disablerepo=\*, because some dependencies maybe contained other repos
sudo dnf install qemu-kvm --enablerepo=<repo_id>
Note: repo_id can be seen in the file /etc/yum.repos.d/<filename.repo>.
Yum/DNF's equivalents with APT: APT command equivalents on Fedora with DNF :: Fedora Docs
RPM naming convention
包名 - 版本号 - 发布次数 - 发行商 -Linux 平台 - 适合的硬件平台 - 包扩展名。
tdx-migration-tools-0.1-1.el8.noarch.rpm:
-
tdx-migration-tools: 包名 -
0.1: 版本号 -
1: 发布次数 -
el8: 发行商,el8 表示此包是由 Red Hat 公司发布,适合在 RHEL 8.x 和 CentOS 8.x 上使用。 -
noarch: 硬件平台
QEMU_PKGVERSION Pkgversion
❯ build/qemu-system-x86_64 --version
QEMU emulator version 7.2.90 (v6.1.0-13152-g1c5c785656)
Copyright (c) 2003-2022 Fabrice Bellard and the QEMU Project developers
QEMU_PKGVERSION is the v6.1.0-13152-g1c5c785656.
It is generated by git describe --match 'v*' --dirty.
See git describe^.
Salt
What does .old suffix in kernel name mean?
When you are installing your kernel the responsible script is copying kernel image and initramfs into your /boot directory. If a previous kernel image with the same name already exist, it is renamed by appending .old to its name.
ls /lib/modules doesn't have .old suffix.
compiling - Linux kernel version suffix + CONFIG_LOCALVERSION - Unix & Linux Stack Exchange
Platform device
这些设备有一个基本的特征:可以通过 CPU bus 直接寻址(例如在嵌入式系统常见的 “寄存器”)。因此,由于这个共性,内核在设备模型的基础上(device 和 device_driver),对这些设备进行了更进一步的封装,抽象出 paltform bus、platform device 和 platform driver,以便驱动开发人员可以方便的开发这类设备的驱动。
Cannot mount AppImage, please check your FUSE setup
sudo yum -y install fuse
ID Allocation (IDR and IDA)
The IDR and the IDA provide a reasonable solution to the problem to avoid everybody inventing their own. The IDR provides the ability to map an ID to a pointer, while the IDA provides only ID allocation, and as a result is much more memory-efficient.
For IDA:
- The IDA handles its own locking. It is safe to call any of the IDA functions without synchronisation in your code.
- IDs are currently limited to the range [0-INT_MAX].
IDA 是一种基于 Radix 的 ID 分配机制。TDX 的 HKID 基于此进行分配。
ID Allocation — The Linux Kernel documentation
Linux boot to BIOS directly like Windows holding shift when click restart button
sudo systemctl reboot --firmware-setup
Linux on UEFI - how to reboot to the UEFI setup screen like Windows 8 can? - Super User
Save minicom log to a file
sudo minicom -C trist.log -D /dev/ttyUSB1
Shadow cache
写的时候把 shadow copy 一起写上,读的时候只需要读 shadow 即可。
Shadow 里的内容永远是保存的最新的状态。
Errno
include/uapi/asm-generic/errno-base.h
Reg cache
Reg cache 是不需要 cache 里面的内容永远保持最新的状态,只有它访问时才去更新。
How to load a kernel module with parameters
sudo modprobe kvm_intel tdx=1
How to list all the kernel modules
sudo lsmod
See all available parameters of a kernel module
sudo modinfo kvm_intel
KVM parameters
sudo ls /sys/module/kvm_intel/parameters
Specify kernel name when compile
make LOCALVERSION=-lei
KVM parameters
ll sys/module/kvm/parameters/
migratable Cmdline option in QEMU
If set, only migratable flags will be accepted when "enforce" mode is used, and only migratable flags will be included in the "host". If not specified in the cmdline, the default is true (you can see the code).
The property definition is in target/i386/cpu.c:
// host is the subclass of max. From here we can see, "migratable" option is only valid in max/host, it is meaningless is cpu model
static Property max_x86_cpu_properties[] = {
DEFINE_PROP_BOOL("migratable", X86CPU, migratable, true),
//...
};
See the following function for how do migratable, migratable_flags, unmigratable_flag and feature names influent if the feature will be exposed to guest.
static uint64_t x86_cpu_get_migratable_flags(FeatureWord w)
{
// ...
for (i = 0; i < 64; i++) {
// ...
if ((wi->migratable_flags & f) ||
(wi->feat_names[i] && !(wi->unmigratable_flags & f))) {
r |= f;
}
}
return r;
}
Exportfs
假设在第一次配置 NFS 的共享目录,之后需要新增、更改某些机器或共享的目录;首先需要更改配置文件,然后重启 NFS 服务,但如果远程客户端正在使用 NFS 服务,正在挂载着,如果你需要先停止 NFS 服务,那远程的客户端就会挂起,就会很大的影响,造成服务异常,进程异常,有很大可能导致系统坏掉。NFS 服务不能随便重启,要重启,就需要先去 client 上,把挂载的目录卸载下来。
在卸载目录后,在重启 NFS 服务。若是有很多 client 都挂载了,那么每台机器都需要去卸载,就会很麻烦。
方法:使用 exportfs 命令,重新加载下
exportfs 命令
-a 全部挂载或者全部卸载
-r 重新挂载
-u 卸载某一个目录
-v 显示共享目录
所以 exportfs 省力在什么地方?好像还是需要每一个 client 都操作一下。
/etc/exports
QDF / S-Spec
QDF Number is a four digit code used to distinguish between engineering samples. e.g.,
Once a processor is in pre-production, its S-Spec Number is used to represent it.
What's the difference of QDF and S-spec code ? - Intel Communities
cr4_guest_owned_bits And cr4_guest_rsvd_bits in vcpu
CR4 reserved bits
system reserved cr4
guest reserved cr4
How to write CPU model for QEMU
Fields:
- Model: 可以
cat /proc/cpuinfo | grep model,也可以直接看 SDM 上的值,Vol 4, Chapter 2, Table 2-1。 - Family: 可以
cat /proc/cpuinfo | grep family,也可以直接看 SDM 上的值,Vol 4, Chapter 2, Table 2-1。 -
.level: The maximum input value for Basic CPUID Information supported on this model.cpuid -1 -l 0 -r, the return EAX value is it. -
.xlevel: The maximum input value for Extended Function CPUID Information supported on this model.cpuid -1 -l 0x80000000 -r, the return EAX value is it. -
.stepping: The stepping info needs to read from physical SDP via CPUID tool (or simply lscpu), it may varies as BIOS/microcode changes. Simply pick the latest value when you develop the QEMU CPU model. -
.model_id:cat /proc/cpuinfo | grep model
Tail queue
QEMU 和 kernel 中都有实现。
双向链表,有头指针和尾指针,可以在头部插入和删除,也可以在尾部插入和删除。
Difference between a tail queue and a double-ended queue:
data structures - Difference between a Tail queue and a Double-ended queue - Stack Overflow
Irqchip
An "irqchip" is KVM's name called an "interrupt controller".
A VM needs an emulated interrupt controller. In a KVM VM, it is possible to have this emulated device be in userspace (ie QEMU) like all the other emulated devices. But because the interrupt controller is so closely involved with the handling of simulated interrupts, having to go back and forth between the kernel and userspace frequently as the guest manipulates the interrupt controller is bad for performance. So KVM provides an emulation of an interrupt controller in the kernel (the "in-kernel irqchip"). The default QEMU setting is to use the in-kernel irqchip.
linux - What is an “irqchip”? - Stack Overflow
How to know physical address and linear address length?
cpuid -1 -l 0x80000008
A sample output:
Physical Address and Linear Address Size (0x80000008/eax):
maximum physical address bits = 0x2e (46)
maximum linear (virtual) address bits = 0x39 (57)
In SDM, MAXPHYADDR always refer to the maximum physical address bits. MAXLINADDR always refer to the maximum linear address bits.
注意,MAXPHYADDR 不代表 CPU 实际支持的大小:But since no one will be using that much physical ram before current CPU models are obsolete, CPU chips don't actually support that much. They support various numbers of physical address bits from 36 up. 40, which you have, is pretty typical.
idle=poll
CPU idle time management is an energy-efficiency feature.
if idle=poll is used, idle CPUs will execute a more or less lightweight'' sequence of instructions in a tight loop.
CPU Idle Time Management — The Linux Kernel documentation
容器存储层
容器运行的文件系统是镜像层和容器层组成的,一层一层叠加,只有最上面的那层是可写的,其他层都是只读的。
Container 是在 Image 之上去创建的,不同于镜像(Image)就是一堆只读层(read-only layer),而 Container 最上面那一层(Container layer)是可读可写的。
有些容器会自动产生一些数据,为了不让数据随着 container 的消失而消失,就有了 Volume 的存在,其可以带来很好的性能表现,这是因为它 绕过 storage driver 直接将文件卸载宿主机上,不需要使用写时复制策略。正因如此,当需要大量的文件写操作时最好使用数据卷。
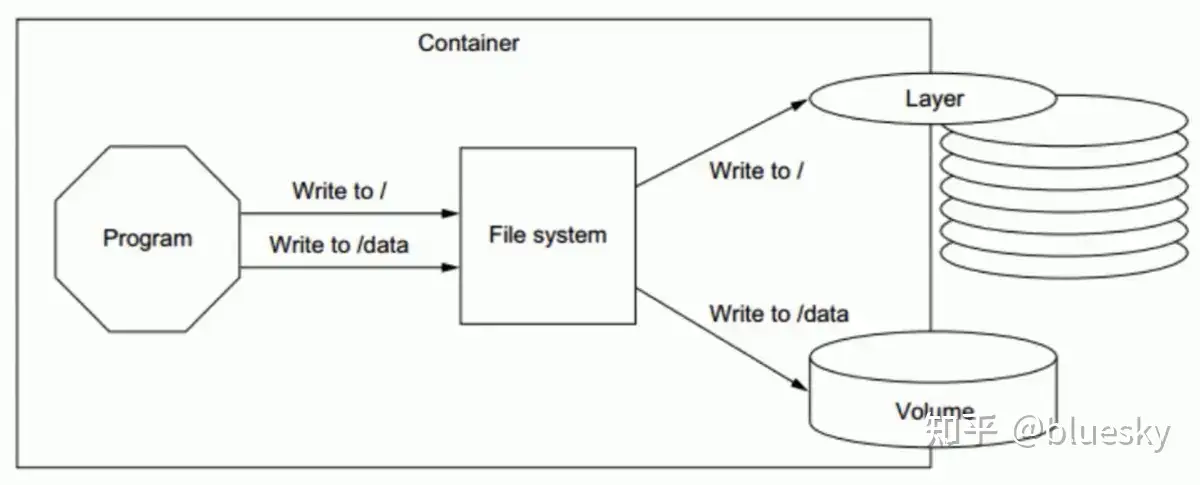
VOLUME in dockerfile vs. -v when docker run
一文说清楚Dockerfile 中VOLUME到底有什么用?_dockerfile volume_诺浅的博客-CSDN博客
How to change guest cmdline
sudo vim /etc/default/grub and append your kernel options between the quotes:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
# for Ubuntu
sudo grub-mkconfig -o /boot/grub/grub.cfg
# for CentOS
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Sometimes grub is not used, for example: systemd-boot (formerly known as gummiboot) boot loader.
Systemd-boot: an alternative to GRUB | Linux Addicts
edit the file in /boot/loader/entries/<kernel>.conf directly.
Dracut
Dracut is a set of tools that provide enhanced functionality for automating the Linux boot process.
dracut is capable of embedding the kernel parameters in the initramfs, thus allowing to omit them from the boot loader configuration.
Change home directory for a user in Linux
login as root, then:
usermod -m -d /newhome/username username
Grub-install
install GRUB to a device. (Not install a kernel to grub!).
--bootloader-id=ID: the ID of bootloader. This option is only available on EFI and Macs.
GUID (Globally Unique Identifier)
In UEFI, a GUID is a 128-bit value used to uniquely identify a wide range of objects, including EFI system partitions, boot entries, hardware devices, firmware volumes, and more.
GUIDs are used extensively in UEFI to provide a standardized way of identifying various objects across different platforms and firmware implementations. This ensures that firmware and software components can reliably and accurately locate and interact with these objects, even when running on different systems with different firmware versions.
Example: Each partition has a "partition type GUID" that identifies the type of the partition and therefore partitions of the same type will all have the same "partition type GUID". For ESP^, it is C12A7328-F81F-11D2-BA4B-00A0C93EC93B.
GUID Partition Table - Wikipedia
How does OS know the size of the physical memory?
BIOS: An OS that boot from a BIOS-based system query the Query System Address Map function using INT 0x15, AX=0xE820.
UEFI: A UEFI-based OS would typically get the physical memory map using the GetMemoryMap() interface.
linux - how does the OS know the real size of the physical memory? - Stack Overflow
MBR
The Master Boot Record (MBR) is the information in the first sector of a hard disk.
- Will be of 512 bytes.
- Contains partition tables to mount partitions ( i.e., details related to Primary, Logical and Extended partitions)
- Holds Stage 1 of GRUB (boot loader).
Primary function of stage 1 of Grub is to locate stage 2 of GRUB, which eventually helps in booting of OS.
Offset Size Description
0x000 446 Boot Code
0x1BE 64 Partition Table (4 entries, 16 bytes each)
0x1FE 2 Boot Signature (0x55AA)
CentOS dependencies for building kernel
sudo yum install ncurses-devel
CentOS dependencies for building QEMU
sudo yum install ninja-build glib2-devel pixman-devel
Bind address
Bind to 0.0.0.0, any NIC can receive.
Bind to localhost, only can receive the data send from local.
Bind to <ip>, only can receive the data sent to this NIC.
Windows 取消登录密码
Windows 10 如何取消开机密码? - 知乎
https://www.zhihu.com/question/33600594/answer/1362750202
How to change from Jekyll to Hugo?
3 approaches: https://gohugo.io/tools/migrations/#jekyll
Docker windows image 下载加速
设置 ->Docker Engine->添加一个字段:
"registry-mirrors": [
"https://<your_code>.mirror.aliyuncs.com"
]
这个 URL 需要去阿里云申请(推荐阿里云,速度最快最稳定):容器镜像服务
Container proxy to host clash for when using docker desktop on Windows
Add following to devcontainer.json:
"containerEnv": {
"http_proxy": "http://host.docker.internal:7890",
"https_proxy": "http://host.docker.internal:7890",
"HTTP_PROXY": "http://host.docker.internal:7890",
"HTTPS_PROXY": "http://host.docker.internal:7890",
}
CFS 算法
Completely Fair Scheduler (CFS) 的设计目标是尽可能地公平地分配 CPU 时间片。CFS 采用红黑树来维护进程的优先级,通过计算每个进程的虚拟运行时间(vruntime)来选择下一个应该执行的进程。
每个进程的虚拟运行时间是指该进程占用 CPU 的时间,与该进程的优先级成反比。CFS 通过不断调整进程的优先级来使得每个进程的虚拟运行时间大致相同。
在选择下一个进程时,CFS 会从红黑树中选择一个 vruntime 最小的进程,将其调度到 运行队列 中。由于红黑树的查找时间复杂度是 O (logN),因此 CFS 的调度时间复杂度也是 O (logN)。
当一个进程被调度到运行队列中执行时,它会被分配一个 timeslice,长度是可配置的。当时间片用完后,进程会被重新放回就绪队列中,等待下一次调度。与传统的时间片轮转算法不同,CFS 的时间片是动态调整的,取决于进程在队列中等待的时间和其优先级的大小。CFS 认为,时间片越长的进程应该更容易获得 CPU 的执行时间,以保证吞吐量和响应时间的平衡。
https://www.kernel.org/doc/Documentation/scheduler/sched-design-CFS.txt
Run Queue(运行队列)
Different scheduling algorithm may have different explanation on this concept.
Other scheduling algorithms in the Linux kernel may use different data structures to manage the runnable processes, and may not necessarily use the concept of a "run queue" in the same way that CFS does. For example,
- the O(1) scheduler in Linux divides the run queue into several priority arrays, with each array containing a set of runnable tasks with the same priority. The scheduler selects the task to run from the highest-priority array that contains tasks.
- The deadline scheduler, on the other hand, maintains a set of queues, with each queue holding tasks with the same deadline. The scheduler selects the next task to run from the earliest expiring deadline queue.
So while the concept of a run queue is specific to CFS, other scheduling algorithms may have similar data structures to hold runnable processes, but with different names and implementation details.
Vruntime
Essentially, vruntime is a measure of the "runtime" of the thread - the amount of time it has spent on the processor. The whole point of CFS is to be fair to all; hence, the algo kind of boils down to a simple thing: (among the tasks on a given runqueue) the task with the lowest vruntime is the task that most deserves to run, hence select it as 'next'.
linux - What is the concept of vruntime in CFS - Stack Overflow
nr_running
This is a CFS-specific parameter, other schedules don't use it.
运行队列和就绪队列的区别
就绪队列存储所有 可以运行(但是调度算法还暂时不想让其运行)的进程。当进程调度器需要为某个 CPU 分配一个新的进程时,它会从就绪队列中选择一个进程,并将其移动到对应的运行队列中。
运行队列是一个在 CPU 上运行的队列,用来存储当前正在执行的进程。当一个进程被分配到一个 CPU 运行时,它就会 从就绪队列中被移动到对应的运行队列 中。在运行队列中,进程会占用 CPU 的处理能力,直到它完成了它的任务或者被中断或者被挂起。
KVM source files organization
| Visible to all (must in include/uapi/) | visible to all except userspace (must in include/) | only visible to current and sub folder | |
|---|---|---|---|
| Arch-agnostic | include/uapi/linux/kvm.h | include/linux/kvm_host.h | virt/kvm/kvm_mm.h |
| Arch-specific (must in arch/x86) | arch/x86/include/uapi/asm/kvm.h | arch/x86/include/asm/kvm_host.h | arch/x86/kvm/x86.h |
| Vendor-specific | arch/x86/include/uapi/asm/vmx.h | arch/x86/include/asm/vmx.h | arch/x86/kvm/vmx/vmx.h |
I think all files can be categorized into these 9 classes.
How does userspace use VMX?
Q: In arch/x86/include/uapi/asm/vmx.h, there are only exit reasons. How does QEMU (userspace) use it?
A: QEMU will sync with the kernel about the number of exit reasons in linux-headers/linux/kvm.h.
arch/x86/kvm/x86.h
It is arch-specific, so couldn't in virt/, thus in arch/x86.
It is just for KVM, so couldn't in arch/x86/include, thus in arch/x86/kvm
kvm.h will sound like it can be used in any architecture, and because this is not vendor-specific, so cannot be named vmx.h or svm.h, so the name x86.h .
vmx.h(s)
arch/x86/include/uapi/asm/vmx.h
Just VM Exit reasons.
arch/x86/include/asm/vmx.h
supposed to be included by any file in any places.
arch/x86/kvm/vmx/vmx.h
Because it is not in the include folder, so it is only included in the source files in the same folder arch/x86/kvm/vmx.
Q: Why don't merge it into the arch/x86/include/asm/vmx.h?
A: I think it is because the code in arch/x86/include/asm/vmx.h will be included in any source files in any places, to avoid bloating, extract the contents needn't to be globally imported to arch/x86/kvm/vmx/vmx.h.
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。