2023-01 Monthly Archive
Misc ideas
x86 指令编码 (硬编码) 的结构 opcode 最少 1 个字节,最多 3 个字节:X86-64 Instruction Encoding - OSDev Wiki
ftruncate()
ftruncate() is a simple, single-purpose function, it simply sets the file to the requested length.
fallocate()
fallocate() is a Linux-specific function that does a lot more, and in very specific ways. fallocate() is used to manipulate the allocated disk space for a file, either to deallocate or preallocate it.
FALLOC_FL_PUNCH_HOLE: deallocates space (i.e., creates a hole) in the byte range starting at offset and continuing for len bytes. Within the specified range, partial filesystem blocks are zeroed, and whole filesystem blocks are removed from the file. After a successful call, subsequent reads from this range will return zeros. The FALLOC_FL_PUNCH_HOLE flag must be ORed with FALLOC_FL_KEEP_SIZE in mode; in other words, even when punching off the end of the file, the file size does not change.(memfd 是不是可以通过这种方式来把内存的映射置空?,反正实现函数是 specific 的)。
kvm_msr_user_space
/*
* Couldn't handle rdmsr or wrmsr in KVM, so handle it in userspace.
* index: The MSR index caused this
* exit_reason: can only be KVM_EXIT_X86_RDMSR or KVM_EXIT_X86_WRMSR
* data: The MSR data
* completion: A function to complete last vm exit before next kVM_RUN
* For more, please see the implementation of kvm_read_guest_virt_helper()
*/
static int kvm_msr_user_space(struct kvm_vcpu *vcpu, u32 index,
u32 exit_reason, u64 data,
int (*completion)(struct kvm_vcpu *vcpu),
int r)
Kthreadd (PID 2)
由 0 号进程创建。
所有其它的内核线程的 ppid 都是 2,也就是说它们都是由 kthreadd thread 创建的。
If you examine the list you will see all [] processes have ppid=2 (kthreadd) while all user space processes may have ppid=1 (systemd/init).
What really is kthreadd ? — Linux Foundation Forums
How to know a process's command line (not all)
sudo readlink -f /proc/<num>/exe
Wait queue in the kernel
struct wait_queue_entry {
unsigned int flags;
void *private;
wait_queue_func_t func; // this is the callback function
struct list_head entry;
};
struct wait_queue_head {
spinlock_t lock;
struct list_head head;
};
When something interesting occurs, you call every callback for each entry in the wait queue. aka, activating.
When we want to activate this queue, we call __wake_up_common on it.
Do not mix-up wait queue and list head, wait queue use list_head which means it can act as a list item in any list.
Implementation of Epoll ❚ fd3kyt's blog
Embedded Anchor in Linux / struct list_head
struct list_head {
struct list_head *next, *prev;
};
Design philosophy: internal link (method 2 below):
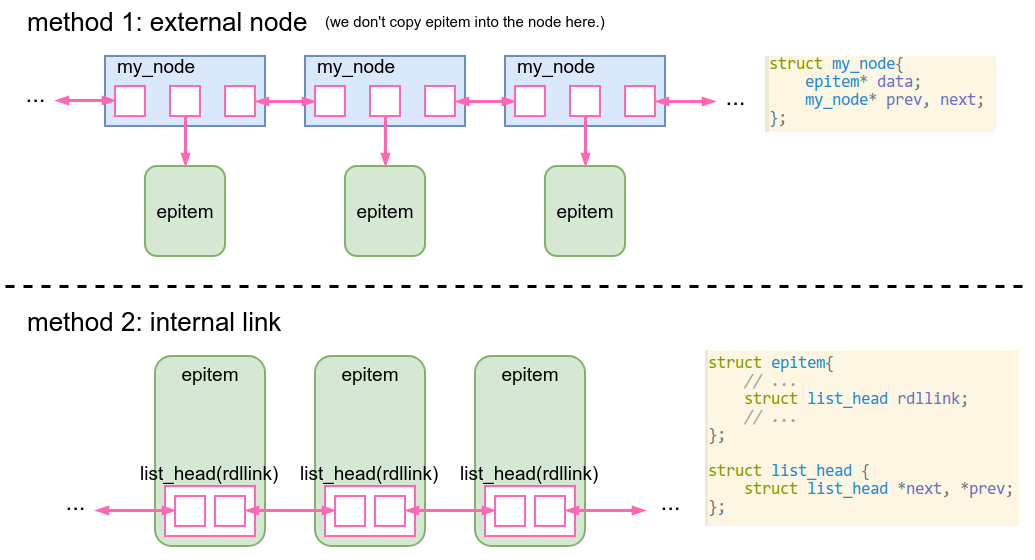
Pros:
- Don’t need a list type for every type of element
- Elements of a list can be of different types
Implementation of Epoll ❚ fd3kyt's blog
Array in struct in C / Flexible array member(FAM)
C struct data types may end with a flexible array member with no specified size.
If there is an array in a struct, what's the size of the struct? For an example:
struct student
{
int stud_id;
int name_len;
int struct_size;
char stud_name[];
};
The size of the structure is 4 + 4 + 4 + 0 = 12. The size i.e length of array stud_name isn’t fixed and is an FAM.
Another example I encountered:
struct kvm_cpuid2 {
__u32 nent;
__u32 padding;
struct kvm_cpuid_entry2 entries[];
};
sizeof(kvm_cpuid2) is 8, sizeof(struct kvm_cpuid_entry2*) is also 8, but it become 0 because it is at the and of the struct definition.
Flexible array member - Wikipedia
Virtualization Exception (VE) / EPT-violation VE / Suppress VE bit
为什么要有 VE,一言以蔽之,有一些 EPT violation 并不一定就是因为 GPA->HPA 没有建立起来,也有可能是因为
VE 相比于 VM-exit 的好处是不需要进行模式切换。A virtualization exception can occur only in VMX non-root operation. 也就是说在 bare-metal 的情况下,不会出现 VE。
VEs occur only with certain settings of certain VM-execution controls. Generally, these settings imply that certain conditions that would normally cause VM exits instead cause virtualization exceptions.
In particular, the setting of the “EPT-violation #VE” VM-execution control causes some EPT violations to generate VEs instead of VM exits. If the control is 0, EPT violations always cause VM exits. If instead it is 1, certain EPT violations may be converted to cause VEs instead; such EPT violations are convertible.
暂时 VMX 和 TDX 都没有 enable 这个 feature 来做 EPT Violation handling 来处理 page fault,TDX 用 VE 来做一些 MMIO 相关的内容,详参 SHADOW_NONPRESENT_VALUE。
In the settings that Linux will run in, VEs are never generated on accesses to normal, TD-private memory that has been accepted (by BIOS or with tdx_enc_status_changed()).(想起 SHADOW_NONPRESENT_VALUE 了吗,就是会 suppress VE)。
不过如果你想进一步看 code,可以找 arch/x86/kernel/traps.c 里的 DEFINE_IDTENTRY(exc_virtualization_exception)。
Bit 63 of certain EPT PSE may be defined to mean suppress #VE。Bit 2:0 为 present or not:
- 如果是 non present,EPT 翻译 GPA 的时候 walk 到了这里,会出现 EPT Violation,如果 bit 63 也是 0(表示我们不 suppress VE),那么这个 EPT violation 就是 convertible 的,可以转为 VE;
- 如果 present:
- 如果这个 PTE 的值是非法的,这个时候应该产生的是 EPT Misconfiguration 而不是 EPT Violation,所有的 EPT Misconfiguration 都一定会出现 VM-exit。
- 否则:
- 如果是一个 PTE(而不是 PSE),说明其映射了一个页。这个 PTE 应该用来翻译一个 GPA,如果访问这个 GPA 的时候出现了 EPT Violation,那么其应该 VM-exit 还是 VE 取决于 suppress VE bit。
- 如果是一个 PSE,这个 PSE 的 suppress VE bit 是 ignore 的,不会对是否产生 VE 产生影响。
SDM
CHAPTER 26 VMX NON-ROOT OPERATION
26.5 FEATURES SPECIFIC TO VMX NON-ROOT OPERATION
26.5.7 Virtualization Exceptions
It is guest's responsibility to configure and setup #VE ISR (Interrupt Service Routine).
Like other exceptions, the processor also provides the corresponding exception information in Virtualization-Exception Information Area used by ISR, e.g. the violation permissions, guest linear and physical address. This area is populated by processor when such an exception happens.
如果不进行模式切换,那么 Host 如何帮忙设置好 EPT Violation 对应的页表并返回呢?
我们来深挖一下 VE 的使用场景。Guest OS 可以设置一个 VE 的 handler(这本身就已经表示 Guest 知道自己跑在一个虚拟化环境里了),当发生 VE 的时候,guest 可以 handle 这个 EPT violation 然后调用一个 VMFUNC,目前只有一个 function 就是 EPTP-switching,允许 guest OS 换一个 EPT 指针,也就是换一个 EPT 页表,然而只能在 root mode 预先配置好的几个 EPT 里面来换,那么,使用场景就来了:host VMM software can configure two different EPT paging-structure mappings pointed by two different EPTP pointer, one is a "privileged", the other is "unprivileged". When code running with "unprivileged" mapping attempts to access the guest physical memory referenced in "privileged" mapping, an EPT violation vmexit might happen, and then VMM can switch EPTP pointers to let access success if such an access is legitimate. 两个 EPT,每个只 map 了 GPA 的一部分 range,当访问一个的时候出现 EPT violation,我们可以切到另一个。这给了 guest OS 一次截获内存访问的机会,guest OS 可以做自己想做的事情。
VMFUNC, which can only be executed in guest OS (VMX non-root mode), allows software in VMX non-root operation (guest) to invoke a VM function, which is processor functionality enabled and configured by software in VMX root operation (host).
SIMPLE IS BETTER: Thoughts on Hardware Virtualization Exception
kvm_read_guest_virt
/*
* addr: guest virtual address
* val: the value we want
* bytes: how long we want to read?
* For more, please see the implementation of kvm_read_guest_virt_helper()
*/
int kvm_read_guest_virt(struct kvm_vcpu *vcpu,
gva_t addr, void *val, unsigned int bytes,
struct x86_exception *exception);
Seqlock
普通的 spin lock 对待 reader 和 writer 是一视同仁,RW spin lock 给 reader 赋予了更高的优先级,那么有没有让 writer 优先的锁的机制呢?答案就是 seqlock。
Printk stuck in kernel
Sometimes printk will stuck in the kernel such as epoll_wait function.
use trace_printk, then:
sudo cat /sys/kernel/debug/tracing/trace
c - Linux booting hang up after adding a printk statement in the kernel source code - Stack Overflow
Linux trace event subsystem
Using the Linux Kernel Tracepoints — The Linux Kernel documentation
sk_buff (skb)
sk_buff 是 Linux 网络中最核心的结构体,各层协议都依赖于 sk_buff 而存在。
sk_buff 结构体在各层协议之间传输不是用拷贝,而是通过增加协议头和移动指针来操作的。
- 高层协议往低层协议(比如 L4 -> L2):通过往
sk_buff中增加协议头。 - 低层到高层(比如 L2 -> L4):通过移动指针,不删除各层协议头,为了提高 CPU 的工作效率。
Intel IBT
Some times you may see ibt=off in kernel cmdline, which means disable the Indirect Branch Tracking security feature.
Indirect Branch Tracking (IBT) that is part of Intel's Control-Flow Enforcement Technology (CET).
Scheduling in kernel
内核有两个调度器:
- 主调度器:
schedule(); - 周期性调度器:
scheduler_tick()inkernel/sched/core.c。
其实任务切换的过程都是由这两个函数完成的:
- 主调度器:大多数场景是任务(task)主动去调用,完成进程切换;
- 周期性调度器:以定时器中断的方式定时触发。
kernel调度----基本知识介绍_扫地聖的博客-CSDN博客_kernel中断调度
Call trace for scheduler_tick():
update_process_times
scheduler_tick
Soft lockup/hard lockup 两种 Watchdog 事件
如下:
-
softlockup是该 CPU 的无法调度到其他的进程运行; -
hardlockup是该 CPU 不仅进程无法调度,而且中断也不能运行了(NMI 除外, NMI 是不可屏蔽的中断)。
形成 lockup 需要满足下面两个条件:
- 首先只有内核代码才能引起 lockup,因为用户代码是可以被抢占的,不可能形成 lockup。
- 其次内核代码必须处于禁止内核抢占的状态 (preemption disabled),或者内核没有开启内核抢占选项(
CONFIG_PREEMPT),所以 watchdog 内核线程没有办法被执行(因为没有调度)也就没有办法喂狗。因为 Linux 是可抢占式的内核(如果开启了CONFIG_PREEMPT),只在某些特定的代码区才禁止抢占,在这些代码区才有可能形成 lockup。
可以参考这篇文章:内核如何检测soft lockup与hard lockup? | Linux Performance
A soft lockup is the symptom of a task or kernel thread using and not releasing a CPU for a period of time.
- soft lockup 是针对单个 CPU 而不是整个系统的。
- soft lockup 指的是发生的 CPU 上在 20 秒 (默认) 中没有发生调度切换。
As its name, it is a software-based problem, not a hardware problem (hardware has bus lock).
One possible soft lockup reason:
- Write a dead loop in kernel code;
-
CONFIG_PREEMPTis not enabled so kernel thread cannot be preempted.
This article is a good resource.
Linux内核为什么会发生soft lockup?_confirmwz的博客-CSDN博客
这边文章也不错:
如何启用linux内核异常自动重启机制_watchdog_thresh-CSDN博客
原理是利用了三级优先级:内核线程 < 时钟中断 < NMI 中断。
- soft lockup 仍然是响应中断的,但是内核不调度。watchdog 线程是一个高优先级内核线程,当调度到这个线程时,这个线程会更新一个值,内核不调度会导致 watchdog 没有被及时喂到(也就是没有及时更新这个值)。在 hrtimer 时钟中断的回调函数里面会检查这个 watchdog 线程有没有被调度过(值有没有被更新过),如果没有调度过那么这个回调函数会直接报一个 softlockup 出来。
-
Hard lockup 比 soft lockup 更加严重,CPU 不仅无法执行其它进程,而且不再响应中断。检测 hard lockup 的原理利用了 PMU 的 NMI perf event,因为 NMI 中断是不可屏蔽的,在 CPU 不再响应其他中断的情况下仍然需要响应 NMI 中断,因此仍然可以得到执行。具体来说:基于 PMU 的 perf event 会定期(默认每 10 秒)触发 NMI 中断;在 NMI 中断处理程序(
watchdog_overflow_callback())中,会检查 hrtimer 中断计数器(hrtimer_interrupts) 是否在递增;如果停滞则表明 hrtimer 中断未得到响应,也就是发生了 hard lockup。
How to know the file is in which filesystem?
mount -l
or
df .
Rcp connection refused
Use scp instead rcp.
Procfs / /proc / sysfs / /sys / debugfs / kernfs
两者都是由 systemd 挂载的:
/* Mount /proc, /sys and friends, so that /proc/cmdline and /proc/$PID/fd is available. */
r = mount_setup(loaded_policy, skip_setup);
区别在于:
-
/procwas originally intended to expose internal information about processes, but over time became a dumping ground to expose any kind of internal information from the kernel. -
/syswas created to expose this information in a standardized, structured, way.
Debugfs 一般是 mount 在 /sys/kernel/debug 下面的。所以 debugfs 一般都是挂载在 sysfs 下面的。
kernfs 是一个更基础的内核内置文件系统框架,用于实现内核中的其他特定文件系统,如 sysfs。主要用于提供支持核心文件系统特性,并允许内核子系统轻松创建其特殊用途的文件系统。提供的基本接口使得其他文件系统(如 sysfs, cgroupfs)可以利用它来实现各自的功能,而不需要重复底层代码。它并不会直接对用户空间提供可见的文件和目录,通常是更高层的文件系统如 sysfs 或 cgroupfs 对其进行实例化。
Watchdog
It is a hardware timer. Watchdog 也是内核里的一个 clocksource 哦。
Detect and recover from computer malfunctions.
During normal operation, the computer regularly restarts the watchdog timer to prevent it from elapsing, or "timing out". If, due to a hardware fault or program error, the computer fails to restart the watchdog, the timer will elapse and generate a timeout signal. The timeout signal is used to initiate corrective actions. The corrective actions typically include placing the computer and associated hardware in a safe state and invoking a computer reboot.
Watchdog 和 kernel panic 的区别
watchdog 这里讲的比较详细了:NMI watchdog: BUG: soft lockup
Why sometimes a process cannot be killed?
That usually indicates one of three things:
- a network filesystem that isn't responding;
- a kernel bug;
- a hardware bug.
linux - How to kill a process which can't be killed without rebooting? - Unix & Linux Stack Exchange
Install kernel by rpm
install the kernel:
- "i": install.
- "v": verbose. Print verbose information.
-
"h": hash. Print 50 hash marks as the package archive is unpacked. Use with -v --verbose for a nicer display.
sudo rpm -ivh <name>.rpm
Set default kernel in CentOS by grubby
List installed kernels:
sudo grubby --info=ALL | grep "^index\|^kernel"
choose the kernel:
sudo grubby --set-default-index=<num>
PIIX (PCI IDE ISA Xcelerator)
Is a family of Intel southbridge microchips.
There are some files in QEMU, such as hw/i386/pc_piix.c…
IDE, PATA, ATA
They are the same. Parallel ATA (PATA), originally ATA, also known as IDE(Integrated Drive Electronics).
It is a standard.
When SATA ( Serial ATA ) came out, people started using PATA (Parallel ATA) to refer to the older parallel connected bus.
Do not mix IDE up with ISA, ISA is an old technology that has been replaced by PCI, PCIe and so on.
What is the difference between ISA and PCI? - CAVSI
Zero copy
Zero copy 就是绕过了 page cache(内核缓冲区),直接将数据从设备读到用户空间。
Linux中的零拷贝技术,sendfile,splice和tee之间的区别是什么? - 知乎
readelf VS. objdump
两者都是用来查看一个 ELF 静态文件内容的工具。
The reason is that objdump sees an ELF file through a BFD filter of the world; if BFD has a bug where, say, it disagrees about a machine constant in e_flags, then the odds are good that it will remain internally consistent. The linker sees it the BFD way, objdump sees it the BFD way, GAS sees it the BFD way. There was need for a tool to go find out what the file actually says.
This is why the readelf program does not link against the BFD library - it exists as an independent program to help verify the correct working of BFD.
linux - readelf vs. objdump: why are both needed - Stack Overflow
Process image
Seems not used now time?
Now a days, process context switch occurs through exchanging PCBs (as in Process Context Blocks) with CPU registers. The outgoing process does not get moved to a disk image in secondary storage (ie swapping). That did happen in the old days before paging but no longer.
I don't believe that modern operating systems use what I described in the answer anymore. I'm pretty sure this is an artifact from Unix
memory - What's the difference between a process and a process image? - Stack Overflow
Why code shouldn't modify itself?
That's the restriction imposed by the Operating System, actually OS can modify themselves.
OS forbit self-modifying code due to the following reasons:
- Computer virus.
- Pipelines, when current instruction is executing, actually the next instruction is being decoded, so if you modify the next instruction, it will break the pipeline design.
What NOT to do: Self Modifying Code - Computerphile - YouTube
B4: Download applicable patch series from lore
Install: pip install b4
Download: b4 am <message_id>
apply: git am patch.mbx
Introducing b4 and patch attestation — Konstantin Ryabitsev
Pkg-config
Retrieve information about installed libraries in the system.
Here is a typical usage scenario in a Makefile:
gcc glib_event_loop.c `pkg-config --cflags --libs glib-2.0` # which flags should be used? which lib should be linked?
Instruction (mnemonic) and opcode
Instruction and opcode are not 1-to-1, they are many-to-many.
For example, je and jz share the same opcode: assembly - Why multiple instructions with same opcode and working? - Stack Overflow
Also, A jmp can be assembled to different opcodes:
There are different
jmpinstructions for relative or absolute jumps or far or near jumps. The assembler will choose one of them (e.g., the shortest one) and translate the mnemonic (jmp) to the corresponding machine code.
assembly - How do JMP and CALL work in assembler? - Stack Overflow
Obsidian code block supported language
UD1
Raise invalid opcode exception.
Use the 0F0B opcode (UD2 instruction), the 0FB9H opcode (UD1 instruction), or the 0FFFH opcode (UD0 instruction) when deliberately trying to generate an invalid opcode exception (#UD).
The instruction pointer saved by delivery of the exception references the UD instruction (and not the following instruction).
Undocumented instructions
UD1 is originally such an instruction which is used by the implementation of static_call.
- Intel Software Developers Manual, volume 2B (order no. 253667-060, September 2016) does not list UD0 and UD1.
- Intel Software Developers Manual, volume 2B (order no. 253667-061, December 2016) lists UD0 and UD1.
x86 instruction listings - Wikipedia
EXPORT_SYMBOL_GPL / modprobe --dump-modversions / Kernel symbol version
When a loadable module is inserted, any references it makes to kernel functions and data structures must be linked to the current running kernel. The module loader does not provide access to all kernel symbols, however; only those which have been explicitly exported are available. 也就是说,这些 symbol 是 kernel export 给 kernel module 来用的。以 KVM 来举例,这个函数(EXPORT_SYMBOL_GPU)一般是写在内核代码而非 KVM 代码中。
Exports come in two flavors: vanilla (EXPORT_SYMBOL) and GPL-only (EXPORT_SYMBOL_GPL). The former are available to any kernel module, while the latter cannot be used by any modules which do not carry a GPL-compatible license.
Symbol version 是一种细粒度的接口兼容性控制机制,其核心目的是保证内核模块与内核的二进制兼容性,每一个 export 出来的 kernel function 都有自己的 version。
- 为每个内核导出的符号(函数、变量)分配唯一标识符(如 CRC 校验值)。
- 模块在编译时记录依赖符号的版本。
- 加载模块时,内核检查模块的符号版本是否与当前内核一致,若不一致则拒绝加载。
当内核编译时启用 CONFIG_MODVERSIONS 选项,会为每个导出的符号生成 CRC(Cyclic Redundancy Check)校验值。
macros - What is EXPORT_SYMBOL_GPL in Linux kernel code? - Stack Overflow
一个模块可以通过 EXPORT_SYMBOL_GPL 的方式暴露 symbol 给其他模块来用吗?
可以的。
如何查看一个 kernel module 所依赖的所有 symbols 的 version 值?
modprobe --dump-modversions 这个命令会列出这个 module 所依赖的所有的函数的 version 值。
如何查看当前正在运行的 kernel 的 export 出来的 symbols 的 version 值?
Why rebasing onto a previous commit will have conflicts?
Maybe there are merge commits.
Try to add --rebase-merges option:
git rebase -i --rebase-merges <commit>
Rebasing a Git merge commit - Stack Overflow
Header guard
#ifndef HEADER_H_NAME
#define HEADER_H_NAME
/*…
…*/
#endif
SwitchyOmega forgetting
部分切换规则重启后不见了 · Issue #1476 · FelisCatus/SwitchyOmega
Directive (programming)
In C preprocessor: such as #define and #include are referred to as preprocessor directives.
In Assembly: directives, also referred to as pseudo-operations or "pseudo-ops", which are keywords beginning with a period that behave similarly to preprocessor directives in C.
请启用虚拟机平台 Windows 功能并确保在 BIOS 中启用虚拟化
管理员打开 powershell,输入:
bcdedit /set hypervisorlaunchtype auto
重启电脑。
Hyper-V,Windows 虚拟机监控程序平台,虚拟机平台
虚拟机平台:底层的虚拟机平台。
Hyper-V:上层的虚拟机管理软件,相当于微软开发的类似 VMware 的产品。
Hyper-V 基于虚拟机平台。
WSL2 只需要虚拟机平台打开。
WSA 需要虚拟机平台和 Hyper-V 都打开。
Symbol
Types
function, indirect function, data object, thread local data object, common data object, globally unique data object.
Sendmsg(), write(), send(), Etc.
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags);
Destination: the address of the target is given by dest_addr with addrlen specifying its size. For sendmsg(), the address of the target is given by msg.msg_name, with msg.msg_namelen specifying its size.
The send() call may be used only when the socket is in a connected state.
The only difference between send() and write() is the presence of flags. With a zero flags argument, send() is equivalent to write().
If sendto() is used on a connection-mode socket, the arguments dest_addr and addrlen are ignored. (sendto 可用于无连接).
readv() / writev()
readv() 称为散布读,即将文件中若干连续的数据块读入内存分散的缓冲区中。
writev() 称为聚集写,即收集内存中分散的若干缓冲区中的数据写至文件的连续区域。
Defined in fs/read_write.c.
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
writev() is a bit similar to sendmsg(), except:
- with
sendmsg(), you can specify a destination address for use with connectionless sockets like UDP. - with
sendmsg(), you can also add ancillary data
sendmsg()
You can implement the functionality of sendto() using sendmsg(), but sendmsg() also lets you do lots of other nifty stuff you can't do via sendto()… Eg: send control/ancillary messages, or send multiple separate chunks of data in a single operation (via iovec scatter/gather arrays)… Basically, sendmsg() is the ultimate low-level socket sending function.
When will sendmsg block:
- If space is not available at the sending socket to hold the message to be transmitted
-
O_NONBLOCKnot set: shall block until space is available. -
O_NONBLOCKis set: shall fail.
-
For datagram or message sockets, you send just one datagram or message with a single sendmsg call; not one per buffer element.
It looks like send, and sendto are just wrappers for sendmsg in source code, that build the struct msghdr for you. And in fact, the UDP sendmsg implementation makes room for one UDP header per sendmsg call.
It can send file descriptor to another process (Maybe the descriptor will have another value after the duplicating).
Defined in net/socket.c.
c - How to use sendmsg to send a file-descriptor via sockets between 2 processes? - Stack Overflow
struct msghdr {
void *msg_name; /* ptr to socket address structure */
int msg_namelen; /* size of socket address structure */
int msg_inq; /* output, data left in socket */
struct iov_iter msg_iter; /* data */
/*
* Ancillary data. msg_control_user is the user buffer used for the
* recv* side when msg_control_is_user is set, msg_control is the kernel
* buffer used for all other cases.
*/
union {
void *msg_control;
void __user *msg_control_user;
};
bool msg_control_is_user : 1;
bool msg_get_inq : 1;/* return INQ after receive */
unsigned int msg_flags; /* flags on received message */
__kernel_size_t msg_controllen; /* ancillary data buffer length */
struct kiocb *msg_iocb; /* ptr to iocb for async requests */
struct ubuf_info *msg_ubuf;
int (*sg_from_iter)(struct sock *sk, struct sk_buff *skb,
struct iov_iter *from, size_t length);
};
Will sendmsg copy the user specified data in the iovec to kernel space?
默认应该不是 zero-copy,但是这个 patch set 引入了对于 zero-copy 的支持 socket sendmsg MSG_ZEROCOPY [LWN.net]。加了一个 MSG_ZEROCOPY 的 flag。
msg_name
This one is the address of the destination and is optional, because the socket may in a connected state.
msg_control, msg_controllen
msg_control points to a buffer for other protocol control-related messages or miscellaneous ancillary data(指向与协议控制相关的消息或者辅助数据)。
Ancillary data is a sequence of cmsghdr structures with appended data. See the specific protocol man pages for the available control message types:
struct cmsghdr {
size_t cmsg_len; /* Data byte count, including header (type is socklen_t in POSIX) */
int cmsg_level; /* Originating protocol */
int cmsg_type; /* Protocol-specific type */
/* followed by unsigned char cmsg_data[]; */
};
msg_controllen is for counting the number of msg_control entries.
msg_flags
There are 2 flags:
- One is served as the parameter of this function, the
int flagsfield. - The other is the
msg_flags, which is in themsghdr.
在 sendmsg 中,会忽略 msg_flags 成员,它会按照参数 flags 直接处理。那么当我们去设置 MSG_DONTWAIT(临时非阻塞)是就把 flags 设为 MSG_DONTWAIT 而不是 msg_flags。
在 recvmsg 中,内核会使用 msg_flags 参数地址来存放一些输出(On successful completion, the msg_flags member of the message header is the bitwise-inclusive OR of all of the following flags that indicate conditions detected for the received message)。
sendmsg() -- send message from socket using structure
send System call
A call to send has 3 possible outcomes:
- There is at least one byte available in the send buffer →
sendsucceeds and returns the number of bytes accepted (possibly fewer than you asked for). - The send buffer is completely full at the time you call
send.- if the socket is blocking,
sendblocks - if the socket is non-blocking,
sendfails withEWOULDBLOCK/EAGAIN
- if the socket is blocking,
- An error occurred (e.g. user pulled network cable, connection reset by peer) →
sendfails with another error
Socket
struct socket {
socket_state state;
short type;
unsigned long flags;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
struct socket_wq wq;
};
Socket type
enum sock_type {
SOCK_DGRAM = 1,
SOCK_STREAM = 2,
SOCK_RAW = 3,
SOCK_RDM = 4,
SOCK_SEQPACKET = 5,
SOCK_DCCP = 6,
SOCK_PACKET = 10,
};
Connection-mode socket includes: SOCK_STREAM, SOCK_SEQPACKET.
listen(fd, backlog)
在某一时刻同时允许最多有 backlog 个客户端要和服务器端进行连接。
The backlog argument defines the maximum length to which the queue of pending connections for sockfd may grow. If a connection request arrives when the queue is full, the client may receive an error with an indication of ECONNREFUSED or, if the underlying protocol supports retransmission, the request may be ignored so that a later reattempt at connection succeeds.
socket->sk, Struct sock
每个 socket 数据结构都有一个 sock 数据结构成员,sock 是对 socket 的扩充,两者一一对应:
- socket->sk 指向对应的 sock;
- sock->socket 指向对应的 socket;
socket 和 sock 是同一事物的两个侧面,为什么不把两个数据结构合并成一个呢?这是因为 socket 是 inode 结构中的一部分(union):
struct inode {
union {
//...
struct ext2_inode_info ext2_i;
struct ext3_inode_info ext3_i;
struct socket socket_i;
//...
} u;
};
由于 socket 有大量的结构成分,如果把这些成分全部放到 socket 结构中,则 inode 结构中的这个 union 就会变得很大,而对于其他文件系统(ext2_i, ext3_i)这个 union 是不需要这么大的,所以会造成巨大浪费。
系统中使用 inode 的频率要远远超过使用 socket 的频率,所以 socket 应该为 inode 做出让步。解决的办法就是分成两部分:
- 把与 文件系统 关系密切的放在 socket 结构中;
- 把与 通信 关系密切的放在另一个单独结构 sock 中。
socket和sock的一些分析 - kk Blog —— 通用基础
sk_data_ready
sk_data_ready: callback to indicate there is data to be processed.
使用此函数来唤醒等待的进程。
UDS 的 sk_data_ready 指向的应该是 sock_def_readable() in net/core/sock.c。这个函数会进一步 wake up 对应的 wait queue,为其中的每一个 entry 调用其之前注册的 func,对于 epitem 就是 ep_poll_callback。
Unix domain socket (UDS) IPC
Exchanging data between processes executing on the same host operating system.
Can be connection-oriented (type SOCK_STREAM) or connectionless (type SOCK_DGRAM).
Address Family: AF_UNIX (also known as AF_LOCAL).
Code analysis: Linux 网络IO 优化篇 : 一种本机网络 IO 方法,让你的性能翻倍! | HeapDump性能社区
Diff. with named pipe?
c - unix domain socket VS named pipes? - Stack Overflow
Misc
wake_up_interruptible_sync_poll,只是会调用到 socket 等待队列项上设置的回调函数,并不一定有唤醒进程的操作。
图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的! - 知乎
Clocksource
Typically the clock source is a monotonic, atomic counter which will provide n bits which count from 0 to (2^n-1) and then wraps around to 0 and start over.
系统中可能会同时 注册 多个 clocksource,only 1 clocksource can be current (jiffies is the default clocksource).
如果你用 linux 的 date 命令获取当前时间,内核会读取当前的 clock source,转换并返回合适的时间单位给用户空间。
内核用一个 struct clocksource 对真实的时钟源进行软件抽象。
/**
* struct clocksource - hardware abstraction for a free running counter
* Provides mostly state-free accessors to the underlying hardware.
* This is the structure used for system time.
*
* @read: Returns a cycle value, passes clocksource as argument
* @mask: Bitmask for two's complement
* subtraction of non 64 bit counters
* @mult: Cycle to nanosecond multiplier
* @shift: Cycle to nanosecond divisor (power of two)
* @max_idle_ns: Maximum idle time permitted by the clocksource (nsecs)
* @maxadj: Maximum adjustment value to mult (~11%)
* @uncertainty_margin: Maximum uncertainty in nanoseconds per half second.
* Zero says to use default WATCHDOG_THRESHOLD.
* @archdata: Optional arch-specific data
* @max_cycles: Maximum safe cycle value which won't overflow on
* multiplication
* @name: Pointer to clocksource name
* @list: List head for registration (internal)
* @rating: Rating value for selection (higher is better)
* To avoid rating inflation the following
* list should give you a guide as to how
* to assign your clocksource a rating
* 1-99: Unfit for real use
* Only available for bootup and testing purposes.
* 100-199: Base level usability.
* Functional for real use, but not desired.
* 200-299: Good.
* A correct and usable clocksource.
* 300-399: Desired.
* A reasonably fast and accurate clocksource.
* 400-499: Perfect
* The ideal clocksource. A must-use where
* available.
* @id: Defaults to CSID_GENERIC. The id value is captured
* in certain snapshot functions to allow callers to
* validate the clocksource from which the snapshot was
* taken.
* @flags: Flags describing special properties
* @enable: Optional function to enable the clocksource
* @disable: Optional function to disable the clocksource
* @suspend: Optional suspend function for the clocksource
* @resume: Optional resume function for the clocksource
* @mark_unstable: Optional function to inform the clocksource driver that
* the watchdog marked the clocksource unstable
* @tick_stable: Optional function called periodically from the watchdog
* code to provide stable synchronization points
* @wd_list: List head to enqueue into the watchdog list (internal)
* @cs_last: Last clocksource value for clocksource watchdog
* @wd_last: Last watchdog value corresponding to @cs_last
* @owner: Module reference, must be set by clocksource in modules
*
* Note: This struct is not used in hotpathes of the timekeeping code
* because the timekeeper caches the hot path fields in its own data
* structure, so no cache line alignment is required,
*
* The pointer to the clocksource itself is handed to the read
* callback. If you need extra information there you can wrap struct
* clocksource into your own struct. Depending on the amount of
* information you need you should consider to cache line align that
* structure.
*/
struct clocksource {
u64 (*read)(struct clocksource *cs);
u64 mask;
u32 mult;
u32 shift;
u64 max_idle_ns;
u32 maxadj;
u32 uncertainty_margin;
#ifdef CONFIG_ARCH_CLOCKSOURCE_DATA
struct arch_clocksource_data archdata;
#endif
u64 max_cycles;
const char *name;
struct list_head list;
int rating;
enum clocksource_ids id;
enum vdso_clock_mode vdso_clock_mode;
unsigned long flags;
int (*enable)(struct clocksource *cs);
void (*disable)(struct clocksource *cs);
void (*suspend)(struct clocksource *cs);
void (*resume)(struct clocksource *cs);
void (*mark_unstable)(struct clocksource *cs);
void (*tick_stable)(struct clocksource *cs);
/* private: */
#ifdef CONFIG_CLOCKSOURCE_WATCHDOG
/* Watchdog related data, used by the framework */
struct list_head wd_list;
u64 cs_last;
u64 wd_last;
#endif
struct module *owner;
};
Rating 字段
同一个设备下,可以有多个时钟源,每个时钟源的精度由驱动它的时钟频率决定。
clocksource 结构中有一个 rating 字段,代表着该时钟源的精度范围,它的取值范围如下:
- 1-99: 不适合于用作实际的时钟源,只用于启动过程或用于测试;
- 100-199:基本可用,可用作真实的时钟源,但不推荐;
- 200-299:精度较好,可用作真实的时钟源;
- 300-399:很好,精确的时钟源;
- 400-499:理想的时钟源,如有可能就必须选择它作为时钟源;
Linux时间子系统之一:clock source - kk Blog —— 通用基础
Bootloader (Grub/grub2)
grub2 is configured through /etc/default/grub file.
The grub.cfg file is the GRUB configuration file. It is generated by the grub2-mkconfig program using a set of primary configuration files and the grub default file as a source for user configuration specifications.
Note that any manual changes to /etc/default/grub require rebuilding the grub.cfg file by grub2-mkconfig.
update-grub , at least in Debian and its relatives like Ubuntu, is basically just a wrapper around grub-mkconfig.
boot/grub/grubenv 作用:
- 如果在
/etc/default/grub中设定 GRUB_DEFAULT=saved,则按这一段,把本次启动项记录下来,做为下次默认启动项; - 把 default=x 记录下来,下次启动时调用为 set default=x 而不是默认的 set default=0;
- 如果由于软、硬件原因不能启动的,把 recordfail=1 记录下来,下次启动就会据此设定
set timeout=-1,就是出现菜单后不会进入默认启动,要手动按 enter 才进入启动。
/boot/grub2/grubenv is a regular file on Non-uEFI machine. (NOTE: it's a symlink to /boot/efi/EFI/redhat/grubenv on uEFI machine).
Why after grub2-mkconfig and reboot, cat /proc/cmdline is not updated?
Why do we need a bootloader?
A BIOS would need to know how to load a kernel, and this would make the BIOS over complicated: imagine a BIOS that needs to know how to load the many different operating systems available, how to pass kernel parameters to them etc… BIOS is a firmware in ROM and not flexible to replace, which means we cannot change the kernel parameters easily…
Why BIOS is a firmware not flexible to replace?
我觉得可能是因为 BIOS 本来就是一个很底层的东西,一旦坏了就只能去找厂家修了(但是如果 OS 坏了可以重新刷系统),所以最好不要去经常更改 BIOS 的内容(除非要 update),能不更改就不更改是最好的。所以如果我们要改内核参数,还是设计一个中间层比如 bootloader 来改比较好,作为一个将 BIOS 和 OS 解耦的工具。
Thus, it only initializes the hardware and jumps to a known place where the bootloader is stored; then, the control is passed to it.
bios - Why do we need a boot loader? - Super User
How does BIOS find the bootloader?
For MBR: BIOS search for Master Boot Record (MBR) which contains the bootloader.
For EFI, the ESP will be mounted by EFI firmware, The ESP should be in FAT32 file system. Actually, you can switch bootloaders by changing the boot sequence in my BIOS, just like you can switch kernel when you in a bootloader menu.
ESP/EFI/boot/bootx64.efi, For EFI, This is the only bootloader pathname that the UEFI firmware on 64-bit X86 systems will look for. On Ubuntu, we can find ESP/EFI/ubuntu/grubx64.efi, this is actually the EFI application^. On UEFI based systems, GRUB works by installing an EFI application into ESP/EFI/<id>/grubx64.efi, and id is replaced with an identifier specified in the grub-install command line. GRUB will create an entry in the EFI variables^ containing the path ESP/EFI/<id>/grubx64.efi so the EFI firmware can find grubx64.efi and load it.
Which EFI variable does grub create or modify to let EFI can find the grubx64.efi?
When Grub installs itself on an EFI system, it typically creates or modifies the BootOrder and BootXXXX EFI variables to allow the system firmware to locate and boot the Grub EFI bootloader (grubx64.efi).
The BootOrder variable is a global variable that specifies the order in which the firmware should attempt to boot the available EFI boot loaders. The BootOrder variable contains a list of one or more BootXXXX variables, where XXXX is a four-digit hexadecimal identifier. Each BootXXXX variable specifies a unique boot option, which includes information about the EFI boot loader to be executed and the device from which it should be loaded. 也就是说 BootXXXX 和 boot loader 是一对一的。
When Grub installs itself, it typically creates a new BootXXXX variable with a unique identifier, and sets the DevicePath and FilePath fields of the variable to point to the location of the grubx64.efi bootloader on the EFI system partition. Grub also updates the BootOrder variable to include the new BootXXXX entry, so that the firmware will attempt to boot Grub before any other boot options.
Once the BootOrder variable has been updated, the firmware will automatically attempt to boot the Grub bootloader the next time the system is started. If Grub is successfully loaded, it will then present the user with a boot menu and allow them to select from the available operating systems or boot options.
host_initialized, msr_data, msr_info
host_initialized means the MSR request is issued from host userspace, not from guest.
struct msr_data {
bool host_initiated; // this access is initiated by host.
u32 index; // the index of the MSR, i.e., the address
u64 data; // the value of the MSR
};
How does host_initialized be set and used?
For a MSR write request:
kvm_arch_vcpu_ioctl
case KVM_SET_MSRS:
do_set_msr
kvm_set_msr_ignored_check
__kvm_set_msr // host_initiated is set here
vmx_set_msr // host_initiated is used here to allow taking difference actions on different value
For a MSR read request:
kvm_arch_vcpu_ioctl
case KVM_GET_MSRS:
do_get_msr
kvm_get_msr_ignored_check
__kvm_get_msr // host_initiated is set here
vmx_get_msr // host_initiated is used here to allow taking difference actions on different value
In case of reading an MSR, there are 2 functions which both call function kvm_get_msr_ignored_check(…, bool host_initiated):
-
kvm_get/set_msr(host_initiatedis false) -
do_get_msr(host_initiatedis true)
Call trace for kvm_get_msr (reversed):
kvm_get_msr
emulator_get_msr
ops->get_msr()
It is accessed by KVM instruction emulator (emulate_ops), so the access if from guest.
Call trace for do_get_msr (reversed):
do_get_msr
kvm_arch_vcpu_ioctl
kvm_arch_dev_ioctl
That's why the host_initiated is true, because it is called by host userspace.
Get Free Page flags (GFP flags)
Linux provides a variety of APIs for memory allocation. kmalloc, vmalloc, etc.
Most of the memory allocation APIs use GFP flags to express how that memory should be allocated. The GFP acronym stands for “get free pages”, the underlying memory allocation function.
- Most of the time GFP_KERNEL is what you need. GFP_KERNEL implies GFP_RECLAIM, which means that direct reclaim may be triggered under memory pressure; the calling context must be allowed to sleep. There is the handy
GFP_KERNEL_ACCOUNTshortcut for GFP_KERNEL allocations that should be accounted. - If the allocation is performed from an atomic context, e.g interrupt handler, use GFP_NOWAIT. under memory pressure GFP_NOWAIT allocation is likely to fail.
- More…
Memory Allocation Guide — The Linux Kernel documentation
GFP_DMA
When you allocate memory with the GFP_DMA flag set, the kernel prioritizes memory zones suitable for DMA transfers. These zones typically meet the following criteria:
- Physically Contiguous: The allocated memory should consist of physically contiguous pages. This means the memory pages reside in a continuous block of physical addresses, crucial for efficient DMA operations.
- Below 16 GB (Legacy Systems): In older 32-bit systems, the DMA zone might be restricted to physical memory below a 16 GB address boundary due to limitations in addressing capabilities. However, this restriction is less relevant in modern 64-bit systems.
dma_alloc_coherent() returns address range for which proper memory attributes are already set so cache effect is handled naturally. We need not to do any cache operation for these addresses.
If we use address allocated by kmalloc() for DMA operation then we need to do extra cache operation like cache clean and cache invalidate based on direction of transfer.
Who Uses GFP_DMA?
Device Drivers: Device drivers that require DMA functionality for data transfer with their respective devices often use the GFP_DMA flag during memory allocation. This ensures the allocated memory buffers are suitable for DMA operations.
linux kernel - GFP_KERNEL vs GFP_DMA and kmalloc() vs dma_alloc_coherent() - Stack Overflow
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。