集合通信
Collective Communication / Collective Operation / 集合通信
集合通信:Collective operation - Wikipedia
xCCL(比如 NCCL)里的 CC 指的就是这个。包含了很多元语:Reduce, Gather 等等什么的。
| ![[NCCL.pdf#page=4&rect=4,2,861,482&color=annotate | NCCL, p.4]] |
| ![[NCCL.pdf#page=6&rect=4,3,862,481&color=annotate | NCCL, p.6]] |
| ![[NCCL.pdf#page=7&rect=3,2,862,484&color=annotate | NCCL, p.7]] |
Scatter 这里画的有问题,应该是 B 在 GPU 1 的第二块位置、C 在 GPU 2 的第三块位置、D 在 GPU 4 的第四块位置。
| ![[NCCL.pdf#page=8&rect=3,3,861,482&color=annotate | NCCL, p.8]] |
Gather 这里画的有问题,初始来说应该是 B 在 GPU 1 的第二块位置、C 在 GPU 2 的第三块位置、D 在 GPU 4 的第四块位置。
| ![[NCCL.pdf#page=9&rect=3,2,863,482&color=annotate | NCCL, p.9]] |
All-Gather 这里画的有问题,初始来说应该是 B 在 GPU 1 的第二块位置、C 在 GPU 2 的第三块位置、D 在 GPU 4 的第四块位置。
| ![[NCCL.pdf#page=10&rect=5,2,861,483&color=annotate | NCCL, p.10]] |
| ![[NCCL.pdf#page=11&rect=5,1,863,482&color=annotate | NCCL, p.11]] |
| ![[NCCL.pdf#page=12&rect=5,1,863,483&color=annotate | NCCL, p.12]] |
Reduce Scatter 这里画的有问题,最后结果应该是 $A1 + B1 + C1 + D1$ 在 GPU 1 的第二块位置、$A2 + B2 + C2 + D2$ 在 GPU 2 的第三块位置、以此类推。
| ![[NCCL.pdf#page=13&rect=2,2,861,482&color=annotate | NCCL, p.13]] |
| ![[NCCL.pdf#page=14&rect=3,2,862,482&color=annotate | NCCL, p.14]] |
| ![[NCCL.pdf#page=16&rect=5,3,861,484&color=annotate | NCCL, p.16]] |
All-to-All
All-to-All 常用于需要矩阵转置的算法中:在分布式内存中对一个大矩阵进行转置。因为 All-to-All 的通信模式本身就很像对矩阵进行转置。
All-to-All 在矩阵转置场景的应用:
在矩阵转置的场景下,A0, B0 什么的这些其实可以看作是矩阵的子块,他们并不是矩阵内的一个元素。因此,如果要对整个矩阵做一个转置的话,需要做的事情就是:
- 通信前的本地转置(这个是可选的,如果我们有了通信后的本地转置,那么就不需要这一步了):在本地对小块内部做矩阵的转置操作;
-
All-to-All通信,把块进行转置; - 通信后的本地转置(这个是可选的,如果我们有了通信前的本地转置,那么就不需要这一步了):在本地对小块内部做矩阵的转置操作。
AllReduce
不同机器中的数据整合(reduce)之后再把结果分发给各个机器。
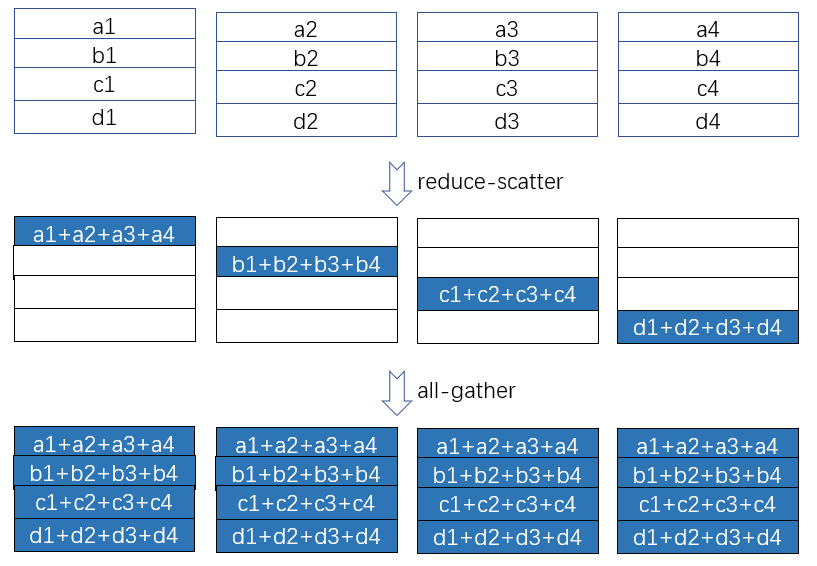
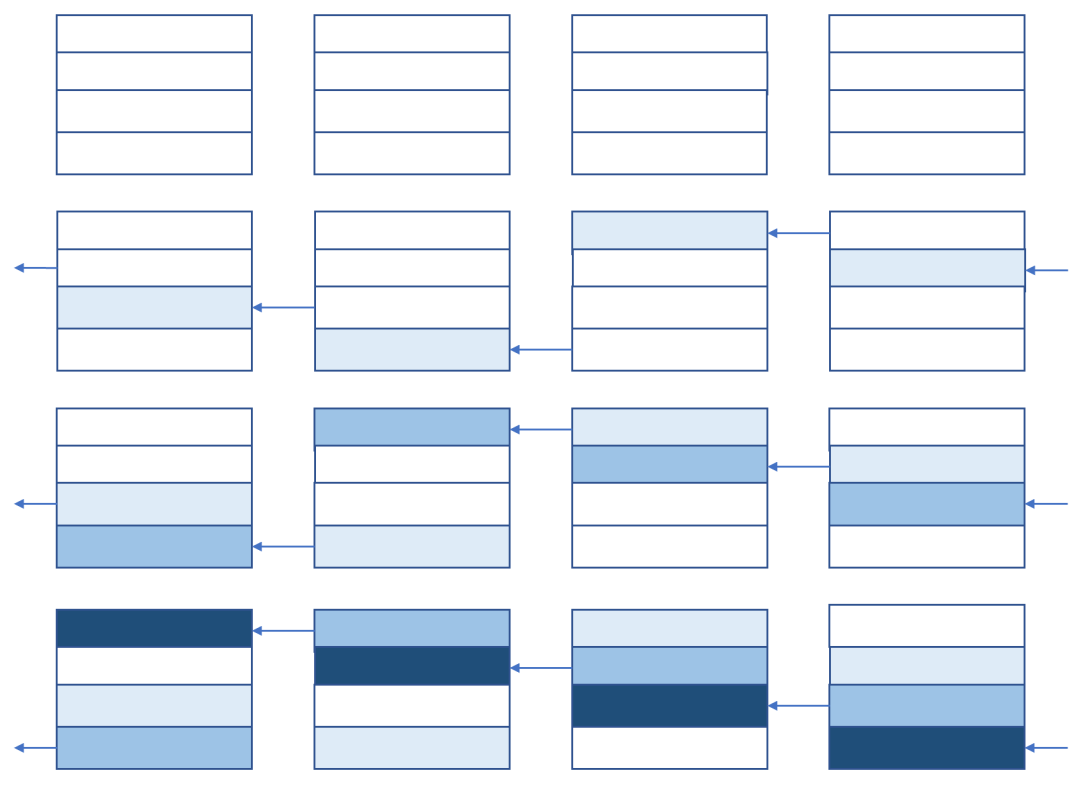
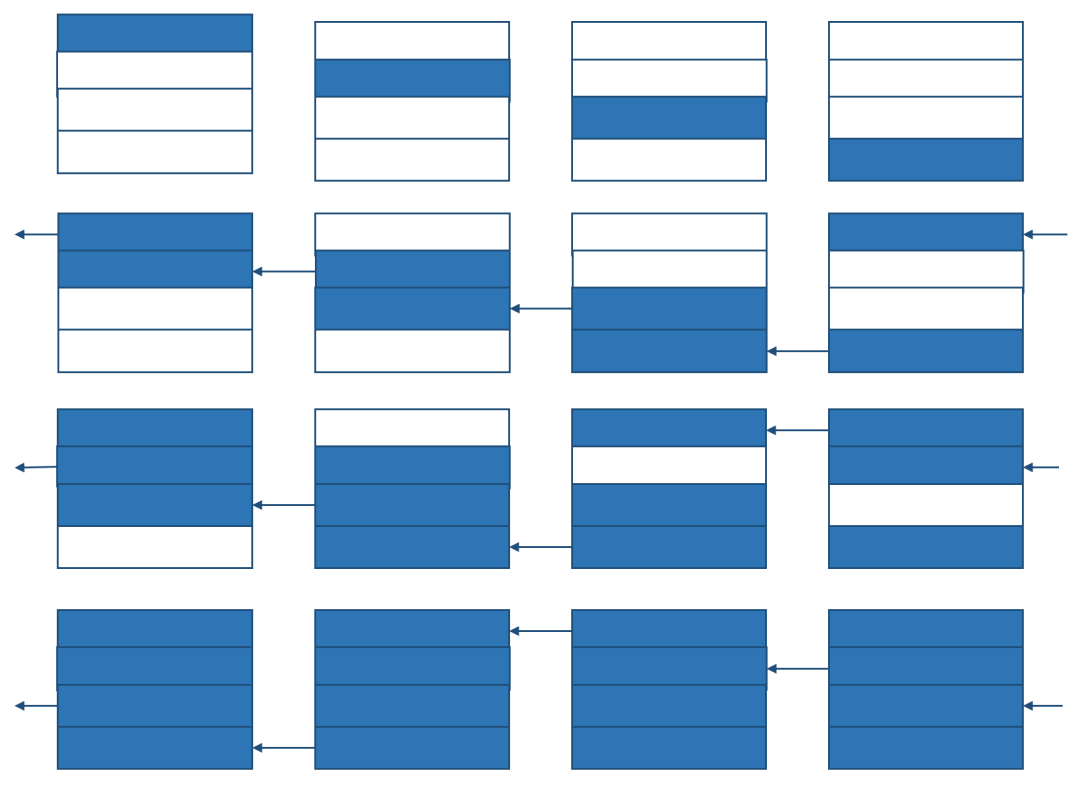
all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。
Ring AllReduce
说白了,就是每一个 GPU,把上一步中接收到的对应区间的数据,在本地做了运算之后,再发送到下一个 GPU 中。因为每一步接收到的区间是不一样的,所以每一步发出去的也不一样。一共需要 $2(n-1)$ 步就能实现,而且 reduce-scatter 和 all-gather 阶段的行为包括数据量什么的都是完全对称的。
有几个 GPU 就把数据切成几份是最优的吗?
- 如果切少了,那么 scatter 完的步骤还是 $n-1$ 步,但是每一步传输的数据量变大了,也就是更久了,不合适。
- 如果切多了,$n - 1$ 步其实是传不完的,还需要多传几步,而且这几步每一步都有可能并不是所有 GPU 都在传输,比如 3 个 GPU 切 4 份这种模式,所以很有可能带宽利用率变低,从而导致整体时间变长。
综合来看,正好是 $n$ 份是最优的。Ring Allreduce 算法的标准实现中,会将每个进程上的数据切分成与 Rank 总数相等的块。
先 reduce-scatter:
再 all-gather:
AllReduce 的实际物理数据通路
我们以双机共 32 卡为例,每一台机器 16 张 GPU 以及 8 张网卡,那么整体的链路应该是 0-15 走机内的 PCIe 或者 Fabric Link,15-16 走网卡,16-31 继续走机内的 PCIe 或者 Fabric Link,31-0 走网卡。
但是实际上我们可以指定多个环(或者叫作多个 NCCL Channel),每一个环在出到另一台机器的断点位置(也就是网卡)不一样,这样就能充分利用所有的网卡进行传输,如下图:
https://my.feishu.cn/wiki/XqESwN2zJijGDhkIewrc7JD6nrM#share-URfJdL25iobN5yxCj3TcBrJGnMh
因为 AllReduce 可以拆成两个原子的集合通信,一个是 ReduceScatter,另外一个是 All Gather。Reduce Scatter 要保证最后所有的 reduce 之后的 chunk 都分散在不同的 rank 上。因为上面不同的 channel 中有的 rank 的上一个 rank 和其他 channel 有区别,所以 NCCL 为了保证 reduce scatter 最后 chunk 结果分散位置的正确性,需要提前去计算,算出来这个 chunk 在这个 channel 应该从哪一个 rank 开始进行 reduce 计算。
但是这种设计存在下面缺陷(比如我们让 Channel 1 来传 Chunk 31,让 Channel 3 来传 Chunk 15,可以看到在 Step 1,C31 和 C35 都同时占用了 GPU0 -> GPU1 中间的这块通路,这就造成了阻塞。所以整体来看,NVLink/PCIe 和网卡,小的那个是瓶颈,怎么处理 channel 感觉是一个学问):
NCCL
NCCL 依赖 CUDA,并且内部大量使用 CUDA API,两者不是平行关系,而是“上层库与底层平台”的层级关系。
NVIDIA Collective Communications^ Library (NCCL pronounced “Nickel”)。NCCL 和其他集合通信库一样,都需要抽象“节点”这个概念,不过 NCCL 里一个节点应该是一个 GPU Rank 而不是一个机器。
Collective Communication / Collective Operation 请搜索^。
NVIDIA 的技术 PDF:NCCL
NCCL 下面也依赖不同的物理层通信协议来通信:
- 在绝大多数情况下都可以通过服务器内的 PCIe、NVLink、NVSwitch 等
- 服务器间的 RoCEv2、IB、TCP 网络实现高带宽和低延迟。
因此:NCCL 屏蔽了底层复杂的细节,向上提供 API 供训练框架调用,向下连接机内机间的 GPU 以完成模型参数的高效传输。
相关笔记及文档:
- [[2025-11-03-分布式训推#分布式训练通信后端]]
通信组
通信组是 NCCL 提供的概念。只有在一个通信组里的 GPU 才能进行集合通信,通信组在 nccl 中以 ncclComm_t 表示,可以说集合通信在通信组里才有意义(我们可以把下面代码看成一个 nccl-tests 程序,其实生态位是一样的。在 nccl-tests 中,如果要支持 MPI,那么在编译时就要加上 MPI 的条件编译):
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include <cuda_runtime.h>
#include <nccl.h>
int main(int argc, char *argv[]) {
int mpi_rank, mpi_size;
int gpu_per_node = 4;
ncclUniqueId nccl_id;
ncclComm_t comm;
cudaStream_t stream;
// 1. 初始化 MPI
MPI_Init(&argc, &argv);
// mpi_rank 通过 MPI 拿到自己的 rank 值
MPI_Comm_rank(MPI_COMM_WORLD, &mpi_rank);
// mpi_size 为 8,告诉自己一共几个要做集合通信
MPI_Comm_size(MPI_COMM_WORLD, &mpi_size); // 预期 8
// 2. 每个进程绑定本节点的 GPU
// 节点 0: rank 0-3 -> GPU 0-3
// 节点 1: rank 4-7 -> GPU 0-3
int local_rank = mpi_rank % gpu_per_node;
cudaSetDevice(local_rank);
cudaStreamCreate(&stream);
// 3. 生成并广播 NCCL UniqueId
// nccl_id 内部封装了rank 0 主机的 IP + TCP 监听端口
if (mpi_rank == 0) ncclGetUniqueId(&nccl_id);
// MPI_Bcast 利用 MPI 已有的跨节点通信能力,把 128 位数据广播出去。
// 所有 8 个进程的 nccl_id 都会变成相同的值。
MPI_Bcast(&nccl_id, sizeof(ncclUniqueId), MPI_BYTE, 0, MPI_COMM_WORLD);
// !!!这一步是关键!!!
// 4. 初始化 NCCL 通信器(8 个 rank 共用同一个 id)
// nccl_id 表示大家都是同一个通信组。
// 这个函数是以 nccl_id 为起点,逐步构建出一个完整的、可直接用于集合通信的 ncclComm_t 对象。
// comm 内部包含很多信息,包含了一切通信所需的长久状态:
// 1. 所有成员 rank 列表
// 2. 每个 rank 的网络连接句柄(例如每个 pair 的 InfiniBand QP、TCP socket)
// 3. 节点/GPU 拓扑信息(NVLink、PCIe、网络路径)
// 4. 每个通道(channel)的具体传输连接
// 5. 为不同集合操作(AllReduce、ReduceScatter 等)选好的算法与路径
// 一旦 comm 被创建好,NCCL 就完全接管了 GPU 间的数据通道,
// 后面的集合通信完全不需要、也不应该再经过 MPI 了(不用再通过 MPI_Bcast 等等 API 了)。
ncclCommInitRank(&comm, mpi_size, nccl_id, mpi_rank);
// 5. 准备 GPU 数据
const int N = 1024;
float *d_send, *d_recv;
cudaMalloc(&d_send, N * sizeof(float));
cudaMalloc(&d_recv, N * sizeof(float));
float *h_send = (float*)malloc(N * sizeof(float));
for (int i = 0; i < N; i++) h_send[i] = (float)mpi_rank;
cudaMemcpyAsync(d_send, h_send, N * sizeof(float),
cudaMemcpyHostToDevice, stream);
free(h_send);
// 6. 执行 AllReduce(跨节点 GPU 集合通信)
ncclAllReduce(d_send, d_recv, N, ncclFloat, ncclSum, comm, stream);
cudaStreamSynchronize(stream);
// 7. 清理资源
ncclCommDestroy(comm);
cudaFree(d_send);
cudaFree(d_recv);
cudaStreamDestroy(stream);
MPI_Finalize();
return 0;
}
不同节点的 GPU 如何组成同一个通信组?
看上面代码,上面代码是在每一个 Rank 上都会跑的。举个例子,nccl-tests 代码因为 include 了 MPI,它可以直接获取到当前 Rank 值,然后我们通过 ncclUniqueId 来标识一个通信组。
NCCL, nccl-tests 和 MPI 库之间的关系
一图以蔽之(注意 NCCL 和 MPI 之间没有任何调用关系,具体可以看通信组^的概念):
NCCL 和 MPI 一个控制 GPU 之间的通信,一个控制 CPU 之间的通信。 两者没有半毛钱关系。
NCCL can be easily used in conjunction with MPI. NCCL collectives are similar to MPI collectives, therefore, creating a NCCL communicator out of an MPI communicator is straightforward. It is therefore easy to use MPI for CPU-to-CPU communication and NCCL for GPU-to-GPU communication.
nccl-tests 直接 include 了 mpi.h,同时也使用了 NCCL。所以当没有 GDR/NVLink/GPU P2P 时,NCCL 基本上就退化成 MPI 通信的方式了。注意 NCCL 本身并没有 import mpi.h,只是方式退化成了和 mpi.h 类似的通信方式:
- 先从 GPU 显存拷贝到 CPU(这一步显然 MPI 库是做不到的);
- 然后 CPU 再通过网络发送到对端网卡,对端网卡再到 CPU(这一步 MPI 库可以做到);
- 然后对端 CPU 再发送到 GPU 显存上(这一步显然 MPI 库也是做不到的)。
有没有可能中间第二步的时候,也是使用了 MPI 库的呢?并没有,可以 clone 下来 NCCL 仓库然后 grep 一下 mpi.h,并不能找到对应代码引入了这个头文件。所以 CPU 通过网络发送并接收的这一步应该也是 NCCL 自己实现的。
实际上,NCCL 的网络层是自己实现的,NCCL 有一个插件机制,可以引入一个网络插件,NCCL 的自研网络层:NCCL 实现了自己的网络抽象层 (ncclNet 插件)。对于标准的以太网(TCP/IP)和 InfiniBand/ RoCE (使用 Verbs API),NCCL 提供了内置的、不依赖 MPI 的实现:
- TCP/IP:NCCL 直接使用 OS 提供的 socket API (
socket,connect,bind,listen,accept,send,recv等) 来实现基于 TCP 的网络通信。 - InfiniBand / RoCE:NCCL 直接使用
libibverbs库提供的底层 Verbs API (ibv_post_send,ibv_post_recv,ibv_poll_cq等) 来实现 RDMA 通信。
因为 nccl-tests include 了 mpi.h,所以 nccl-tests 其实是能够感知到那些 MPI 的环境变量设置的,因此我们可以通过 mpirun 来运行 nccl-tests 的程序。
Build 一个支持 MPI 的 nccl-tests:
make -j MPI=1 NCCL_HOME=/root/nccl-master/build/ MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi/
如何查看 NCCL 是否已经安装以及版本?/ NCCL 安装路径 / 如何检查 NCCL 环境已经设置好了?
查看动态链接库是否已经包含了 nccl:
ldconfig -p | grep libnccl
可以问一下 deepseek 看一下有什么输出:
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make
查看 NCCL 版本:
cat /usr/include/nccl.h | grep "NCCL_VERSION_CODE"
NCCL 如何使用 RDMA 进行测试(GDR)?
NCCL 默认会优先选择高性能协议(如 RDMA/InfiniBand),若不可用则回退到 TCP。也可以通过环境变量强制指定协议。
# 如果要使用 RDMA
export NCCL_DEBUG=INFO # 查看 NCCL 通信详细信息 (debug RDMA)
export NCCL_IB_GID_INDEX=3
export NCCL_IBEXT_DISABLE=0
export NCCL_IB_DISABLE=0
# 使用 GDR
export NCCL_NET_GDR_LEVEL=SYS
# 如果就是不想使用 RDMA
export NCCL_IBEXT_DISABLE=1
export NCCL_IB_DISABLE=1
algbw / busbw
推荐都是用 busbw 而不是 algbw,理由如下:
algbw 计算很简单:数据量除以时间:algbw = S/t。这个结果可能受 Rank 数量的影响。我们以环形 AllReduce 为例:
NCCL Plugin / NCCL-RDMA-SHARP / SHArP (Scalable Hierarchical Aggregation Protocol)
是同一个东西。是提升通信性能的关键工具,它通过优化数据在网络中的传输方式,显著提高了大规模 GPU 集群的通信效率。
将集合操作部分卸载到交换机中进行,进行网内计算。将集合通信(Reduce、Allreduce、Barrier)卸载到网络(交换机)上进行。
NCCL 环境变量解读
NCCL_SOCKET_IFNAME
主要用于指定 NCCL 控制面 通信(TCP/IP 套接字)所使用的网络接口(网卡)。它通常不直接控制数据面(高性能数据传输,如 RDMA/IB)所使用的网卡。
NCCL 的双层通信机制:
- 控制面 (Control Plane):负责节点间的握手、交换地址信息、协调集合操作、错误处理等管理任务。这部分通信通常使用标准的 TCP/IP 套接字。
- 数据面 (Data Plane):负责实际的、高性能的集合通信数据传输(如 AllReduce, AllGather, Broadcast 等)。这部分通信会优先使用最高性能的传输方式,如:
- InfiniBand Verbs (IB/RoCE):通过 RDMA 实现零拷贝、低延迟、高带宽传输。
- NVIDIA GPUDirect RDMA:允许 GPU 内存直接与网卡进行 RDMA 操作,绕过 CPU 和系统内存。
- TCP/IP:当高性能传输不可用时作为后备方案(性能较差)。
NCCL_IB_HCA
控制 GPU 之间通信所使用的网卡。
这个参数和 btl_openib_if_include 之间的区别可以看 RDMA 集合通信测试^。简单来说,一个控制 GPU <-> GPU 之间的通信,一个控制 CPU <-> CPU 之间的通信。
NCCL_MIN_CTAS
DeepEP
DeepEP 和 NCCL 一样,都是通信库生态位。NCCL 定义了一些集合通信原语,DeepEP 还加了一些原语比如 Dispatch/Combine 专门用来优化 All-to-All。也可以说 DeepEP 也是基于 NCCL 实现了一些原语,一部分也依赖了 NCCL。
DeepEP 如何优化 All-2-All 通信呢?
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。