Page cache in Linux
Page cache and disk cache are identical. The OS keeps a page cache in otherwise unused portions of the main memory (RAM).
Page cache 还有一个别名,也就是文件页。一个 inode^ 对应一个 page cache。
Page Cache 和 VFS 以及其他文件系统之间的关系很清楚(左边是 page cache,是侧载的):
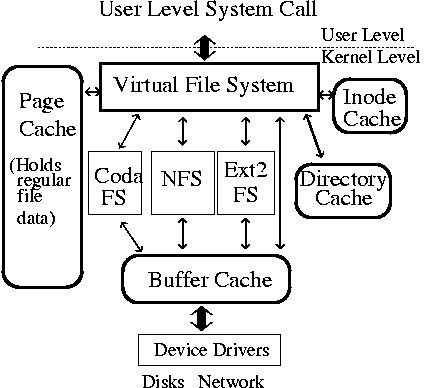
Usually, all physical memory not directly allocated to applications is used by the OS for the page cache.
Page cache 不是进程级的,不是每一个进程都有自己的 page cache,而是所有进程都 share 同一份 page cache。后面 read 的进程可以因为前面进程的 read 而受益。Page cache 是系统资源,不属于某个进程管理,因此无法通过进程内存使用的情况来观察优化效果。
因此,我们以一个 read() 调用来读文件为例,讲述一下可能会有几次拷贝:
- 从硬盘 DMA 到 page cache(page cache 其实就是我们经常说的内核缓冲区,DMA 其实可以不算做是内存拷贝,毕竟不占用 CPU 资源);
- 从 page cache 内存拷贝到用户缓冲区。
可见会有一次内存拷贝。但是如果我们使用了 Direct I/O^,那么就不会有内存拷贝了。因此,使用 page cache 的又叫做 Buffered I/O^。
cgroup 级别的 page cache:Linux kernel - What is the relationship between page cache, struct address_space, and memory cgroups? - Stack Overflow
和 swap cache^ 都是 address_space^。
- 读文件时,如果对应页缓存已存在,那么就直接把页缓存的数据拷贝给用户即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户。
- 写文件时,如果对应页缓存已存在,那么直接把新数据写入到页缓存即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把新数据写入到页缓存中。对于被修改的页缓存,内核会定时把这些页缓存刷新到文件中。
有一本书叫做 Linux Page Cache Mini Book Linux Page Cache for SRE | Viacheslav Biriukov ,可以看看。
Linux Direct I/O / Buffered I/O
使用了 page cache 的其实就是 buffered I/O。Buffered I/O without page-cache thrashing [LWN.net]
Direct I/O 就是不用 page cache,直接读取这个文件。
- 需要指定
O_DIRECTflag; - 需要应用自己管理自己的缓存 —— 这正是数据库软件所希望的;
- 是 zero-copy I/O,因为应用的缓冲数据直接发送到设备,或者直接从设备读取(page cache 就是内核缓冲区,direct I/O 就是绕过了 page cache,自然也不需要内核缓冲区的参与)。
从性能上来说,其实两者还真说不好孰优孰劣,这个其实要看具体的使用场景:
[!PDF|annotate] [[fast24-qian.pdf#page=2&selection=111,0,116,39&color=annotate|fast24-qian, p.2]] Intuitively, buffered I/O should perform better than direct I/O because the read-ahead and write-back optimizations of buffered I/O can bring the performance of buffered I/O mode close to the level of memory access. Using direct I/O therefore typically results in a prolonged process. However, this paper shows that this is not always the case.
| ![[fast24-qian.pdf#page=4&rect=53,604,295,705&color=annotate | fast24-qian, p.4]] |
i_mapping, i_data And mapping
在 struct inode 当中,有两个 struct address_space:
struct inode {
//...
struct address_space *i_mapping;
struct address_space i_data;
//...
}
一个是指针,一个是真的结构体,通常来说,i_mapping 指向 i_data,但是在很少的时候不是。TLDR,永远用 i_mapping 就行了。首先要明白普通 file 和 block device file 的区别^。
But a filesystem can leave the i_data of an inode empty and points the i_mapping to the i_data of another inode, to avoid multiple page caches. 因为 i_mapping 是一个指针,所以其可以指向任何一个 inode 的 i_data。但是不是任何一个 inode 的 i_data 需要是有数据的。比如说如果打开的文件是一个 block device file,那么所有的 inode 的 i_mapping 可以指向同一个 master inode 的 i_data 就可以了。
- 对于普通 file,
i_mapping指向i_data,没有任何的问题; - 对于 block device file,其 page cache 包含的是 raw data of a block device,the
i_mappingfield of the inode of block device file points to theaddress_spaceobject embedded in the master inode,也就是说都指向了同一个 inode 的i_data。
linux kernel - What's the difference between &inode->i_data and inode->i_mapping - Stack Overflow
在 struct page 当中,也有一个 struct address_space:
struct page {
//...
struct address_space *mapping;
//...
}
The ->mapping field of struct page can actually point to three different things, and weirdly enough, two of them are not a struct address_space (despite the type of the field). This is explained in a comment from include/linux/page-flags.h:
- On an anonymous page mapped into a user virtual memory area,
page->mappingpoints to itsanon_vma, not to astruct address_space; with thePAGE_MAPPING_ANONbit set to distinguish it. See rmap.h. - On an anonymous page in a VM_MERGEABLE area, if CONFIG_KSM is enabled, the PAGE_MAPPING_MOVABLE bit may be set along with the PAGE_MAPPING_ANON bit; and then page->mapping points, not to an anon_vma, but to a private structure which KSM associates with that merged page. See ksm.h.
- PAGE_MAPPING_KSM without PAGE_MAPPING_ANON is used for non-lru movable page and then
page->mappingpoints astruct address_space.
linux kernel - What's the difference between &inode->i_data and inode->i_mapping - Stack Overflow
mapping_evict_folio() Kernel
整个函数表示我们要把 page cache 的页扔掉,注意,必须要是 clean 的页,因为我们不负责把 dirty 的页刷回磁盘,这是 writeback 需要做的事情。
long mapping_evict_folio(struct address_space *mapping, struct folio *folio)
{
/* The page may have been truncated before it was locked */
if (!mapping)
return 0;
// 如果这个页是一个脏页,因为脏页刷盘的操作不需要我们来负责,所以我们直接 return 0 就可以了。
if (folio_test_dirty(folio) || folio_test_writeback(folio))
return 0;
// The refcount will be elevated if any page in the folio is mapped
// 如果我们调用了 mmap,那么相当于我们直接映射到了 page cache 的 这个页,所以 refcount 就会更高
// 从而导致这个页是没有办法被 evict 的。
if (folio_ref_count(folio) > folio_nr_pages(folio) + folio_has_private(folio) + 1)
return 0;
if (!filemap_release_folio(folio, 0))
return 0;
return remove_mapping(mapping, folio);
}
Kernel code to reclaim (or evict) the page cache / ksys_sync()
注意 evict inode 和 evict page cache 是不一样的,可以从对于函数 evict_inode() 这里的注释看到:Overview of the Linux Virtual File System — The Linux Kernel documentation
当内存不够的时候,我们需要回收 page cache,这部分代码在哪里?
有一个 syscall 叫做 sync,其功能是:commit filesystem caches to disk。One example of systems that use sync a lot are databases (such as MySQL or PostgreSQL)。这个 sync 只是把所有的 work 提交由另一个内核线程来执行还是说就在这个线程执行,执行完了之后 sync 才会返回?
SYSCALL_DEFINE0(sync)
ksys_sync()
sync_inodes_one_sb
sync_inodes_sb
bdi_split_work_to_wbs
wb_queue_work
__writeback_single_inode
do_writepages
mapping->a_ops->writepages()
struct address_space_operations {
// 这个函数就是负责把 page 写回到 disk
int (*writepage)(struct page *page, struct writeback_control *wbc);
//...
}
对于 ksys_sync() 这个函数,我们还是可以看这里的注释:
void ksys_sync(void)
{
int nowait = 0, wait = 1;
// waking flusher threads so that most of writeback runs on all devices in parallel
wakeup_flusher_threads(WB_REASON_SYNC);
// sync all inodes reliably which effectively also waits for all flusher threads to finish doing writeback.
iterate_supers(sync_inodes_one_sb, NULL);
// At this point all data is on disk so metadata should be stable and we tell filesystems to sync their metadata via ->sync_fs() calls.
iterate_supers(sync_fs_one_sb, &nowait);
iterate_supers(sync_fs_one_sb, &wait);
sync_bdevs(false);
sync_bdevs(true);
if (unlikely(laptop_mode))
laptop_sync_completion();
}
Kernel thread writeback
The kernel thread “writeback” is based on a workqueue, The goal of the kernel thread is to serve all async writeback tasks.
// 表示这个函数在 driver initialize 之后会被调用
subsys_initcall(default_bdi_init);
default_bdi_init
alloc_workqueue("writeback")
Are all page caches can be evicted by kernel?
Evict 指的就是把 page cache 回收掉,并不是指刷到 disk 中的 file。
Will page cache be used when mmaping a file? / Difference between read() and mmap() a file
区别在于 read() 多了一次对 page cache 的拷贝。
When a process(let's call it process1) calls mmap on a regular file, that file is first copied to the page cache. Then the region of page cache which contains the file is mapped to virtual address space of the process1(This memory region is called memory-mapped file). 也就是说其实 mmap 一个文件,访问的时候直接访问的是其 page cache;而如果是直接 read() 一个文件的话,其实是需要从 page cache 当中再 copy 一份 page 到 userspace,mmap() 之后,对文件 fd 的操作是直接作用在 page cache 之上的。
可以推断出,一个文件一旦被 mmap() 了,那么其 page cache 就不能被内核轻易回收了,这是因为相关的 VA -> PA 转换已经写入到了对应进程的页表之中,如果一旦 page cache 回收对应的物理页用到了别的地方,那么这个页表转换将成为 invalid 的,映射到了一个未知的区域,甚至有可能造成系统的崩溃。
SYSCALL_DEFINE6(mmap)
ksys_mmap_pgoff
vm_mmap_pgoff
do_mmap
mmap() 在调用的时候并不会主动地去更新页表,仅仅是更新一下进程的 VMA 信息,一旦访问会发生 page fault,根据 VMA 信息我们知道这个 page fault 应该对应一个 page cache,如果 page cache 已经存在了,那么我们把 page cache 的物理地址作为页表映射的值就可以了。
这么看来 mmap() 相比于 read() 只有好处没有坏处,为什么大部分程序还要继续用 read() 呢?
For smaller files, the read method is faster when compared to the mmap method. That changes with large files - mmap is faster for around 15%. david-slatinek/c-read-vs.-mmap: Performance differences with read when compared to mmap.
- 兼容性考虑:
mmap()只在 POSIX 规范的系统上支持比如 MacOS 和 Linux,Windows 上其实是不支持的。 -
mmap()不一定会让程序更快,比如mmap()需要做内部的 counting。只有当程序的确是 heavy on I/O 的时候才是更快的,因为此时内存拷贝成为瓶颈,mmap()可以大量减少内存拷贝量。
当多个 thread 同时 mmap 了同一个 file 的时候,大家访问的其实是同一份 page cache。如果只是申请共享内存,不 map 到任何文件上,也是一样的:It is also used to provide the pages which are mapped into userspace by a call to mmap.
caching - Does mmap directly access the page cache, or a copy of the page cache? - Stack Overflow 这个问题以自问自答的形式解释了为什么多个 thread 访问 mmap 的文件比单个慢(明明都是 mmap 到了同一个 page cache),他认为原因是 page table 是懒加载的,所以每一个 thread 的 page table 都需要被 populate,这就导致了性能很差。
Does sockfs have page cache?
sockfs 是网络文件系统,它是否也有自己的 page cache?
static const struct super_operations sockfs_ops = {
.alloc_inode = sock_alloc_inode,
//...
};
static struct inode *sock_alloc_inode(struct super_block *sb)
{
struct socket_alloc *ei;
ei = alloc_inode_sb(sb, sock_inode_cachep, GFP_KERNEL);
init_waitqueue_head(&ei->socket.wq.wait);
ei->socket.wq.fasync_list = NULL;
ei->socket.wq.flags = 0;
ei->socket.state = SS_UNCONNECTED;
ei->socket.flags = 0;
ei->socket.ops = NULL;
ei->socket.sk = NULL;
ei->socket.file = NULL;
return &ei->vfs_inode;
}
Difference between page cache and kernel buffer(内核缓冲区)
我们知道 read() 需要从硬盘拷贝到内核缓冲区,再从内核缓冲区拷贝到用户缓冲区,那么 page cache 是如何参与其中的?
内核缓冲区指的就是 page cache^,下面两篇文章都证明了这一观点:
Page cache 的回写机制
假如 Page Cache 中的 Page 经过了修改,它的 flags 会被置为 PG_dirty. 在 Linux 内核中,假如没有打开 O_DIRECT 标志,写操作实际上会被延迟刷盘,以下几种策略可以将脏页刷盘:
struct address_space / Kernel
和虚拟化没关系,这个是在文件 include/linux/fs.h 中定义的结构体。
它是用于管理文件(struct inode)映射到内存的页面(struct page)的,其实就是每个 file 都有这么一个结构,将文件系统中这个 file 的数据与对应的内存绑定到一起。
一个文件在打开后,内核会在内存中为之建立一个 struct inode 结构(该 inode 结构也会在对应的 file 结构体中引用),其中的 i_mapping 域指向一个 address_space 结构。这样,一个文件就对应一个 address_space 结构,一个 address_space 与一个偏移量能够确定一个 page cache 或 swap cache 中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及偏移量而在内存中找到相应的 page。
linux内核中的address_space 结构解析_linux kernel address_space_operations readahead-CSDN博客
address_space 可以用来表示一个 page cache^,也可以是 swap cache^。从何说起?
我们可以粗略地把 memory page 分成两类:
- 表示文件内容,那么这个页的 backend 是 disk 上的某一个文件。这就是
address_space用在 page cache 的地方。 - 表示其他数据比如进程内存空间。那么因为 swap 的存在,这个页的 backend 是 disk 上的 swap file。这就是
address_space用在 swap cache 的地方。
反过来说,一个被访问的文件的物理页面都驻留在 page cache(普通文件)或 swap cache(swap 文件)中。
这个和用户 read 读到的内存没有关系,read 读到的内存是在用户内存中,并非 page cache 等。
struct address_space {
// 指向了这个地址空间的宿主,也就是数据源
// 一个 inode 指向 address_space,那么同样,一个 address_space 也能指向 inode
// address_space 和 inode 并不是严格的一对一的关系,但是大差不差。
struct inode *host;
// 页缓存的基数树。这样就可以通过 inode --> address_space -->i_pages 找到文件对应缓存页
struct xarray i_pages;
struct rw_semaphore invalidate_lock;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
unsigned long nrpages;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
// See enum mapping_flags
unsigned long flags;
struct rw_semaphore i_mmap_rwsem;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;
i_pages / Why i_pages using radix trie?
XArray 是基于基数树实现的,对于一个 inode,或者说一个文件,其所对应的 page cache,为什么要用基数树呢?
这个 XArray 的 index 是一个 offset,表示的是第几个 page,比如文件页 page0 指向 4K 内存保存的是文件 0~4K 地址的数据,文件页 page1 指向的 4K 内存保存的是 test 文件 4K~8K 地址的数据,以此类推。
memory - Why we use radix-tree(or xarray) for storing page caches? - Stack Overflow
void *get_shadow_from_swap_cache(swp_entry_t entry)
{
struct address_space *address_space = swap_address_space(entry);
pgoff_t idx = swap_cache_index(entry);
void *shadow;
shadow = xa_load(&address_space->i_pages, idx);
if (xa_is_value(shadow))
return shadow;
return NULL;
}
我们可以看到,在 inode 和 page 中都有 address_space 结构体存在。
struct inode {
//...
struct address_space *i_mapping;
//...
}
struct address_space_operations Kernel
每一个文件系统定义了自己的 struct address_space_operations,里面定义了自己独有的处理方式。
The address space operations are used to map parts of files (maybe on the disk) into pages in Linux's page cache.
注意不要和 file_operations 弄混了,两者是不同的东西。
struct address_space_operations {
//...
// 什么是 error page?
// Clean (or cleaned) page cache page.
// me_pagecache_clean
// truncate_error_page
// .error_remove_page()
// error 不是重点,remove_page 是重点。这个函数的作用是清楚一个在 page cache 里的 page。
int (*error_remove_page)(struct address_space *, struct page *);
};
文件预读 / readahead in linux kernel
指的是把没有访问到的文件内容先预先读到 page cache 当中,这样如果后面用户程序真的读到了文件内容就可以加快速度。在 mm/readahead.c 的前面的一大段注释中讲的很清楚:
Readahead only ever attempts to read folios that are not yet in the page cache. If a folio is present but not up-to-date, readahead will not try to read it. In that case a simple ->read_folio() will be requested.
Readahead is triggered when
- an application read request (whether a system call or a page fault) finds that the requested folio is not in the page cache, or that
- it is in the page cache and has the
readaheadflag set. This flag indicates that the folio was read as part of a previous readahead request and now that it has been accessed, it is time for the next readahead.
mm/readahead.c 导出的内核 API 的主要部分:
readahead_expand()file_ra_state_init()page_cache_ra_unbounded()page_cache_sync_ra()page_cache_async_ra()
The main part of the API exported by mm/readahead.c is two functions: page_cache_sync_ra() and page_cache_async_ra(). This functionality is also available with a slightly simpler interface as page_cache_sync_readahead() and page_cache_async_readahead().
Each filesystem can provide an address_space_operations method, named readahead(), to initiate a read; it is on this basis that the term "readahead request" is used in the documentation. it doesn't just "read ahead" but also issue reads that have explicitly been requested.
Once one realizes that the functionality of readahead() is just to submit read requests, some of which the caller will wait for ("sync") and some of which the caller won't wait for ("async"), the intention of the code starts to become a lot clearer.
LWN:我希望看到的关于readahead的文档!-CSDN博客
下面这篇文章也是很值得一看的:Readahead: the documentation I wanted to read [LWN.net]
相关代码文件在 mm/readahead.c 中。readahead 是一个系统调用,允许用户程序告诉内核先把数据预读到内核缓冲区(page cache)中去。所以看起来是用户自己触发的,其实内部调用了 fadvise():
// in mm/readahead.c
SYSCALL_DEFINE3(readahead, int, fd, loff_t, offset, size_t, count)
{
return ksys_readahead(fd, offset, count);
}
// ksys_readahead 主要做的一件事就是 vfs_fadvise(),建议这些页是后面需要的
ksys_readahead
vfs_fadvise(f.file, offset, count, POSIX_FADV_WILLNEED);
// 如果文件系统没有定义自己的 fadvise 钩子函数的话,会调用这个
generic_fadvise
switch (advice) {
case POSIX_FADV_WILLNEED:
force_page_cache_readahead
force_page_cache_ra
// 这个函数会根据 i_pages 来看 folio 有没有已经 load 进来了
// 没有就从硬盘 load。
page_cache_ra_unbounded
内核可以在发现可以预读的时候代替用户空间来触发预读吗?可以的,应该说这是具体的文件系统代码(目前只在 btrfs 以及 ext4 中发现了类似代码)调用:
page_cache_sync_readahead()page_cache_async_readahead()
这两个函数会做的。
Cgroup and address_space
Since an address_space corresponds to a single inode (file) and not to a single cgroup, it isn't the case that all pages in this struct are charged to the same cgroup and therefore reside on the same cgroup LRU lists. For instance, imagine that one process in cgroup 1 reads the beginning of a large file, but another process in cgroup 2 reads the end of that file. The pages each process accessed are from the same inode and struct address_space, but some of these pages will be in cgroup 1's LRU lists and others in cgroup 2's.
So it is not possible to find a cgroup from a struct address_space. Instead, in theory, you could iterate through the address_space pages and then find the cgroup that corresponds to each individual page (page->mem_cgroup->css.cgroup).
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。