Scheduling in Linux
Linux 调度器是以模块方式提供的,这样做的目的是允许不同类型的进程可以有针对性地选择调度算法。
这种模块化结构被称为调度器类(scheduler classes),它允许多种不同的可动态添加的调度算法并存,调度属于自己范畴的进程。
Each thread has an associated scheduling policy and a static scheduling priority, sched_priority.
每一个 task_struct 都属于一个调度器类,表示这个 task 需要使用这个调度算法来运行。
For threads scheduled under one of the normal scheduling policies (SCHED_OTHER, SCHED_IDLE, SCHED_BATCH), sched_priority is not used in scheduling decisions (it must be specified as 0).
一些可以参考的地方:
Documentation/scheduler/sched-design-CFS.rst- CFS Group Scheduling
抢占式 / 非抢占式内核
Linux is fully-preemptive kernel.
In non-preemptive kernels, kernel code runs until completion. That is, the scheduler is not capable of rescheduling a task while it is in the kernel—kernel code is scheduled cooperatively, not preemptively. (感觉有点像协程?)
非抢占式内核是由任务主动放弃 CPU 的使用权。非抢占式调度法也称作合作型多任务,各个任务彼此合作共享一个 CPU。异步事件还是由中断服务来处理。中断服务可以使一个高优先级的任务由挂起状态变为就绪状态。但中断服务以后控制权还是回到原来被中断了的那个任务,直到该任务主动放弃 CPU 的使用权时,那个高优先级的任务才能获得 CPU 的使用权。
抢占式内核和非抢占式内核的主要区别在于允不允许在内核态被抢占(毕竟已经叫做内核了)。因为在用户态都是默认可以被抢占的,无法作为区分的标准:
- A preemptive kernel is where the kernel allows a process to be removed and replaced while it is running in kernel mode.
- A nonpreemptive kernel does not allow a process running in kernel mode to be preempted; a kernel-mode process will run until it exits kernel mode, blocks, or voluntarily yields control of the CPU.
Linux 本来是非抢占式内核,打开下面配置 CONFIG_PREEMPTION=y 会变成抢占式内核:Linux 内核抢占_preempt kernel-CSDN博客
Linux 支持用户态抢占和内核态抢占,所以 Linux 是抢占式内核。为了吞吐量(throughput),服务器内核一般不配置内核抢占(CONFIG_PREEMPT)。 内核态抢占一般都是在桌面端打开的(Low-Latency Desktop)。
-/kernel/Linux内核态抢占机制分析.md at master · IMCG/-
用户态抢占 / 内核态抢占
用户态抢占
在 kernel 返回 userspace 时,并且 need_resched 标志为 1 时,scheduler 被调用,这就是用户态抢占。当 kernel 返回用户态时,系统可以安全的执行当前的任务,或者切换到另外一个任务。当中断处理例程或者系统调用完成后,kernel 返回用户态时,need_reched 标志的值会被检查,假如它为 1,调度器会选择一个新的任务并执行。中断和系统调用的返回路径 (return path) 的实现在 entry.S 中 (entry.S 不仅包括 kernel entry code,也包括 kernel exit code)。
内核态抢占
在 2.6 kernel 以前,kernel code(中断和系统调用属于 kernel code) 会一直运行,直到 code 被完成或者被阻塞 (系统调用可以被阻塞)。在 2.6 kernel 里,Linux kernel 变成可抢占式。当从中断处理例程返回到内核态 (kernel-space) 时,kernel 会检查是否可以抢占和是否需要重新调度。kernel 可以在任何时间点上抢占一个任务 (因为中断可以发生在任何时间点上),只要在这个时间点上 kernel 的状态是安全的、可重新调度的。
内核态抢占也是通过中断来触发的。中断触发内核才有机会运行并检查是否应该抢占当前正在运行的进程,毕竟如果没有中断,那么代码会一直运行,除非主动 schedule() 让出内核。
-/kernel/Linux内核态抢占机制分析.md at master · IMCG/-
sched_debug
cat /proc/sched_debug,目前没有官方文档介绍应该怎么解读这个文件,只能自己来看了。
Contains a detailed snapshot of the current state of the task scheduler. This file can be read to gather information about the scheduling behavior of the system, including details about processes, run queues, task states, and much more. This is particularly useful for debugging and analyzing the performance and behavior of the scheduler.
// 因为是 snapshot,所以记录了状态所处于的时间
ktime : 1107713998.528159
sched_clk : 1107717776.284200
cpu_clk : 1107716916.147034
jiffies : 5402374117
// 用户控制的 sysctl 的参数值
sysctl_sched
.sysctl_sched_latency : 24.000000
.sysctl_sched_min_granularity : 3.000000
.sysctl_sched_wakeup_granularity : 4.000000
.sysctl_sched_child_runs_first : 0
.sysctl_sched_features : 2382255931
.sysctl_sched_tunable_scaling : 1 (logarithmic)
// 记录 0 号 CPU 的一些信息
cpu#0, 2700.000 MHz
// ...
// 记录了 CFS rq 0 上不同 cgroup 的一些信息:
cfs_rq[0]:/infra.slice/walle.service
cfs_rq[0]:/kubepods/burstable/podd95bee59-b5bd-427e-af7a-fce15e6e52e2/6ccc6466e126c26b2df3457c41d7d53f428510bb7c4ce2d44f2ae580472cb4a7
cfs_rq[0]:/agent/staragent
//...
// 记录了 RT rq 上不同的 cgroup 的一些信息:
rt_rq[0]:/kubepods/podeb79fbbe-4a90-48f2-aa75-d0612e7adaac/073ab3f5564d0154fce9a45e2a1ca166efef9c00932f23e6dab5b0e70539f003/system.slice/staragentctl.service
// 记录了 DL rq 上不同的 cgroup 的一些信息:
dl_rq[0]:
runnable tasks:
S task PID tree-key switches prio wait-time sum-exec sum-sleep
-------------------------------------------------------------------------------------------------------------
I kworker/0:0H 6 15827.889926 4 100 0.010135 0.023551 18776.961015 0 0 /
S rcu_tasks_rude_ 9 24.722573 2 120 0.010850 0.001014 0.001148 0 0 /
S rcu_tasks_trace 10 26.722983 2 120 7.641103 0.001079 0.000830 0 0 /
S ksoftirqd/0 11 1605787839.911611 920287 120 40058.007098 55814.813891 1107608478.957886 0 0 /
S migration/0 13 0.000000 226168 0 0.002497 2069.422412 0.001512 0 0 /
S cpuhp/0 14 19642.150188 39 120 0.830647 2.069306 24659.055021 0 0 /
I cryptd 997 15637.578094 2 100 0.000000 0.000000 0.000000 0 0 /
I acpi_thermal_pm 1316 15796.770279 2 100 0.000000 0.020246 0.012492 0 0 /
I kworker/0:1H 1319 1605938959.142368 167562 100 51233.493900 2887.435026 1107631763.935069 0 0 /
I zswap-shrink 1324 15863.906633 2 100 0.000000 0.009667 0.007558 0 0 /
I 0000:ec:01.0 2629 18936.901968 2 100 0.000000 0.008354 0.048604 0 0 /
S rngd 3007 41313.248001 27 120 8.614127 4560.847558 0.000000 0 0 /system.slice
S FixedStackAdp 3603 4404994.708755 1106599 120 24483.360467 10439.152818 1107646261.348002 0 0 /system.slice
S pouchd 26601 804181.912795 5035437 120 36902.900102 775018.327969 1106671544.518812 0 0 /system.slice/pouch.service
S containerd 224869 1606546100.011265 1510005 120 5576.416339 288968.795648 1030790431.521644 0 0 /
D kubelet 214938 6005217.084878 55057 120 2180595.954822 66609.948524 1284794.943557 0 0 /kubereserved/kubelet
D kubelet 215155 6005227.840990 54630 120 2192908.140281 65463.078196 1273482.908395 0 0 /kubereserved/kubelet
R kubelet 215273 6005229.428378 55003 120 2177227.320320 64972.439742 1289521.407241 0 0 /kubereserved/kubelet
// 记录 1 号 CPU 的一些信息,如此循环往复,直到最后一个 CPU
cpu#1, 2700.000 MHz
// ...
struct preempt_notifier Kernel
struct preempt_notifier {
struct hlist_node link;
struct preempt_ops *ops;
};
struct preempt_ops {
void (*sched_in)(struct preempt_notifier *notifier, int cpu);
void (*sched_out)(struct preempt_notifier *notifier,
struct task_struct *next);
};
监听的事件是线程被调度 (sched out) 出去 (例如时间片用完了或者被强占)、线程被重新调度 (sched in)。
schedule
__schedule
context_switch
// 当前进程被调度出去时,通知
prepare_task_switch
fire_sched_out_preempt_notifiers
__fire_sched_out_preempt_notifiers
hlist_for_each_entry(notifier, &curr->preempt_notifiers, link)
notifier->ops->sched_out(notifier, next);
// 新进程被调度进来时,通知
finish_task_switch
fire_sched_in_preempt_notifiers
__fire_sched_in_preempt_notifiers
hlist_for_each_entry(notifier, &curr->preempt_notifiers, link)
notifier->ops->sched_in(notifier, raw_smp_processor_id());
Linux kernel preempt_notifier - L
schedule() / Kernel
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
// 用于检测当前进程是否有 plugged io 需要处理,由于当前进程执行 schedule() 后,
// 有可能 CPU 会进入休眠,所以在休眠之前需要把 plugged io 处理掉放置死锁。
sched_submit_work(tsk);
do {
// 禁止发生调度
preempt_disable();
__schedule(SM_NONE);
sched_preempt_enable_no_resched();
} while (need_resched());
sched_update_worker(tsk);
}
static void __sched notrace __schedule(unsigned int sched_mode)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
unsigned long prev_state;
struct rq_flags rf;
struct rq *rq;
int cpu;
// prev 指向当前正在运行的进程
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
if (sched_feat(HRTICK) || sched_feat(HRTICK_DL))
hrtick_clear(rq);
local_irq_disable();
rcu_note_context_switch(!!sched_mode);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up():
*
* __set_current_state(@state) signal_wake_up()
* schedule() set_tsk_thread_flag(p, TIF_SIGPENDING)
* wake_up_state(p, state)
* LOCK rq->lock LOCK p->pi_state
* smp_mb__after_spinlock() smp_mb__after_spinlock()
* if (signal_pending_state()) if (p->state & @state)
*
* Also, the membarrier system call requires a full memory barrier
* after coming from user-space, before storing to rq->curr.
*/
rq_lock(rq, &rf);
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
/*
* We must load prev->state once (task_struct::state is volatile), such
* that we form a control dependency vs deactivate_task() below.
*/
prev_state = READ_ONCE(prev->__state);
if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
if (signal_pending_state(prev_state, prev)) {
WRITE_ONCE(prev->__state, TASK_RUNNING);
} else {
prev->sched_contributes_to_load =
(prev_state & TASK_UNINTERRUPTIBLE) &&
!(prev_state & TASK_NOLOAD) &&
!(prev_state & TASK_FROZEN);
if (prev->sched_contributes_to_load)
rq->nr_uninterruptible++;
/*
* __schedule() ttwu()
* prev_state = prev->state; if (p->on_rq && ...)
* if (prev_state) goto out;
* p->on_rq = 0; smp_acquire__after_ctrl_dep();
* p->state = TASK_WAKING
*
* Where __schedule() and ttwu() have matching control dependencies.
*
* After this, schedule() must not care about p->state any more.
*/
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
}
switch_count = &prev->nvcsw;
}
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
#ifdef CONFIG_SCHED_DEBUG
rq->last_seen_need_resched_ns = 0;
#endif
if (likely(prev != next)) {
rq->nr_switches++;
/*
* RCU users of rcu_dereference(rq->curr) may not see
* changes to task_struct made by pick_next_task().
*/
RCU_INIT_POINTER(rq->curr, next);
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space.
*
* Here are the schemes providing that barrier on the
* various architectures:
* - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC.
* switch_mm() rely on membarrier_arch_switch_mm() on PowerPC.
* - finish_lock_switch() for weakly-ordered
* architectures where spin_unlock is a full barrier,
* - switch_to() for arm64 (weakly-ordered, spin_unlock
* is a RELEASE barrier),
*/
++*switch_count;
migrate_disable_switch(rq, prev);
psi_sched_switch(prev, next, !task_on_rq_queued(prev));
trace_sched_switch(sched_mode & SM_MASK_PREEMPT, prev, next, prev_state);
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unpin_lock(rq, &rf);
__balance_callbacks(rq);
raw_spin_rq_unlock_irq(rq);
}
}
内核的调度是由内核线程来处理,还是就是由内核比如说中断处理程序或者在 Syscall 的过程中执行?
并不是在内核线程中处理的。因为内核线程只有一个 SCHED_SOFTIRQ 的软中断向量号是用来 load balancing 的。
调度实体(Scheduling entity)/ struct sched_entity
在相当长的一段时间内,Linux 都将 task_struct 作为调度器的工作对象。但这样做存在一个问题,特别是在 CFS 引入之后,对时间公平性的讨论让这个问题更加明显。
进程组 task_group 的引入实际上是增加了一个调度层级,调度器首先完成进程组的时间分配,再处理组内进程之间的时间分配。
这么来看,一个进程可以作为调度的对象,一个进程组也可以作为一个调度的对象,这就衍生出了调度实体的概念。用来对调度对象进行抽象化。目前的调度实体有两种:进程和进程组。
linux调度子系统3 - cfs_rq 与 sched_entity_多核cpu 多个cfs rq-CSDN博客
struct sched_entity {
/* For load-balancing: */
// load->weight 表示权重(注意不是 nice 值),需要将 nice 值通过 sched_prio_to_weight
// 转化过来。和 nice_0_weight 也就是 1024 什么的其实是一种东西。
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
// 这个表示这个调度实体已经在就绪队列上,有可能在运行,有可能没有在运行
// 需要明确一个观点就是,CFS 运行队列里面包含有一个红黑树,但这个红黑树并不是 CFS 运行队列的全部,
// 因为红黑树仅仅是用于选择出下一个调度程序的算法。很简单的一个例子,普通程序运行时,其并不在红黑树中,
// 但是还是处于 CFS 运行队列中,其 on_rq 为真。
// 只有准备退出、即将睡眠等待和转为实时进程的进程其 CFS 运行队列的 on_rq 为假。
// 也就是说 running task + rb tree task = run queue tasks
// dequeue_entity 会置 0,enqueue_entity 会置 1。
unsigned int on_rq;
// 表示这个进程开始运行的时间
u64 exec_start;
u64 sum_exec_runtime;
// 就是 vruntime 虚拟时间
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
/* cached value of my_q->h_nr_running */
unsigned long runnable_weight;
#endif
#ifdef CONFIG_SMP
/*
* Per entity load average tracking.
*
* Put into separate cache line so it does not
* collide with read-mostly values above.
*/
struct sched_avg avg;
#endif
};
调度优先级与 Nice, Weight, Load, Shares / scale_load()
请先看调度策略^。为什么要设置两个东西呢,合并到一起不好吗?
看下 syscall sched_setattr 的参数,在设置的时候也是有两个优先级的 sched_nice, sched_priority:
struct sched_attr {
u32 size; /* Size of this structure */
u32 sched_policy; /* Policy (SCHED_*) */
u64 sched_flags; /* Flags */
s32 sched_nice; /* Nice value (SCHED_OTHER, SCHED_BATCH) */
u32 sched_priority; /* Static priority (SCHED_FIFO, SCHED_RR) */
/* For SCHED_DEADLINE */
u64 sched_runtime;
u64 sched_deadline;
u64 sched_period;
/* Utilization hints */
u32 sched_util_min;
u32 sched_util_max;
};
- The nice value is a number in the range -20 (high priority) to +19 (low priority);
- The allowed range of priorities for these policies can be determined using
sched_get_priority_min(2) andsched_get_priority_max(2).
两者的区别在于他们适用的 schedule policy 不一样。In Linux system priorities are 0 to 139 in which 0 to 99 for real-time and 100 to 139 for users. Nice value — Nice values are user-space values that we can use to control the priority of a process. The nice value range is -20 to +19 where -20 is highest, 0 default and +19 is lowest.
所以说其实 $120 + nice = priority$,可以这么来算。
nice 值和权重之间的关系:
// kernel/sched/core.c
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
- 进程每降低一个 nice 级别,优先级则提高一个级别,相应的进程多获得 10% 的 CPU 时间
- 进程每提升一个 nice 级别,优先级则降低一个级别,相应的进程减小得 10% 的 CPU 时间
Shares 其实和 Weight 是同一个单位。设置 nice 反映到 kernel 里是设置 weight,设置 shares 反映到 kernel 里还是 weight。所以:
- nice value 是针对一个进程的权重设置,a nice value applies to a task, that is a process or threada nice value applies to a task, that is a process or thread;
- shares 是针对一个进程组的权重设置,a "CPU shares" value applies to a task group。
64bit 下,NICE_0_LOAD 就是 1024 * 1024。
scale_load() 函数用来将 weight 转化成 load,有以下等式成立:scale_load(sched_prio_to_weight[NICE_TO_PRIO(0) - MAX_RT_PRIO]) == NICE_0_LOAD 所以说 weight 和 load 还是有区别的,需要通过 scale_load() 函数来进行转化,一般来说是 1024? ## 调度策略(scheduling policies)
Linux 调度策略是基于进程的,每个进程有自己的调度策略。内核在进行进程调度时,多种调度策略的进程在一起,按调度策略和优先级统一进行进程调度。调度策略并不是只有 CFS 才有。
调度策略容易和调度类弄混,其实是一个调度类负责多个进程的调度,每一个进程都有其调度策略。仅此一个调度类里面的进程可以通过调度策略来分类,配合优先级来决定下一次调度应该选择哪一个进程。
实时优先级(priority 值主要工作在这里):
-
SCHED_DEADLINE策略由于按截止时间约束,因此可抢占SCHED_FIFO、SCHED_RR。 -
SCHED_FIFO、SCHED_RR这两个通过priority值确定谁更优先。同优先级的SCHED_RR可交替执行,SCHED_FIFO不主动让出 CPU。当优先级相同的SCHED_FIFO任务和SCHED_RR任务都存在时,SCHED_FIFO任务通常会优先执行,因为SCHED_FIFO没有时间片,一旦开始执行,它将一直运行,而SCHED_RR任务则进行轮转。它们都是固定优先级。
普通优先级(nice 值主要工作在这里):
-
SCHED_OTHER(SCHED_NORMAL, In the Linux kernel source code, theSCHED_OTHERpolicy is actually namedSCHED_NORMAL) 即 CFS,或者说 CFS 算法主要处理这里面的进程。 -
SCHED_BATCH与SCHED_OTHER相似,也是基于 Nice 值的动态优先级调度策略,通常被认为是 CPU 密集型进程,因此与 SCHED_OTHER 相比,SCHED_BATCH 进程更倾向被调度器排到后面。
低优先级:
-
SCHED_IDLE是一种低优先级的轮询策略,用于处理系统空闲时的任务。这些任务只在 CPU 没有其他工作要执行时才会运行。
CFS 实现了 SCHED_NORMAL, SCHED_BATCH 和 SCHED_IDLE 三种策略的调度。
// 文件 include/uapi/linux/sched.h
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
struct task_struct {
//...
// 也就是说一个任务可以有一个自己的 policy
unsigned int policy;
//...
}
调度策略可以通过 userspace 通过 syscall sched_setattr 来设置。可以通过 chrt 来设置。
SYSCALL_DEFINE3(sched_setattr)
sched_setattr
__sched_setscheduler
int oldpolicy = -1, policy = attr->sched_policy;
SCHED_FIFO 是如何调度的
很简单,先进先出。进程在下面的条件下会放弃 CPU:
- 进程在等待,例如 IO 操作。当进程再回到 ready 状态时,它会被放到 runqueue 队尾。
- 进程通过
sched_yieldyield(主动让出) CPU。进程立即进入 runqueue 队尾。
try_to_wake_up() Kernel
其实睡眠状态就是没有加入到 runqueue 中。所以 wakeup 其实可以理解成把进程加入到 runqueue 中去。因此我们需要对一个新创建的进程做 wakeup 操作,因为其创建出来时没有在 runqueue 中。
SCHED_RR 是如何调度的
在这种调度策略中,runqueue 中的每个进程轮流获得时间片(quantum)。
调度器类(或者叫调度类,scheduling Classes, struct sched_class)
多个调度算法可以同属于一个调度器类,但是同一个时刻只有一个调度算法能代表这个调度器类来工作。
新的 CFS 调度器被设计成支持“调度类”,一种调度模块的可扩展层次结构。这些模块封装了调度策略细节,由调度器核心代码处理,且无需对它们做太多假设。
-
sched/fair.c实现了上文描述的 CFS 调度器。 -
sched/rt.c实现了 SCHED_FIFO 和 SCHED_RR 语义,且比之前的原始调度器更简洁。它使用了 100 个运行队列(总共 100 个实时优先级,替代了之前调度器的 140 个),且不需要过期数组(expired array)。
调度类由 sched_class 结构体实现,它包括一些函数钩子,当感兴趣的事件发生时,钩子被调用。
这是(部分)钩子的列表:
-
enqueue_task(…)当任务进入可运行状态时,被调用。在 CFS 中,它将调度实体放到红黑树中,增加nr_running变量的值。 -
dequeue_task(…)当任务不再可运行时,这个函数被调用,在 CFS 中对应的调度实体被移出红黑树。它减少nr_running变量的值。 -
yield_task(…)这个函数的行为基本上是出队,紧接着入队,除非 compat_yield sysctl 被开启。在那种情况下,它将调度实体放在红黑树的最右端。 -
wakeup_preempt(…)这个函数检查进入可运行状态的任务能否抢占当前正在运行的任务。 -
pick_next_task(…)这个函数选择接下来最适合运行的任务。 -
set_next_task(…)这个函数在任务改变调度类,改变任务组时,或者任务被调度时被调用。 -
task_tick(…)这个函数最常被时间滴答函数调用,它可能导致进程切换。这驱动了运行时抢占。
我们来看一些实现了这个 sched_class 结构体的调度器类:
所有的调度器类被放到了下面两个 list 里面,可以看到其实 lowest 里面并没有东西,所有的东西都在 highest 里面,里面调度器类出现的顺序决定了他们之间的优先级:
extern struct sched_class __sched_class_highest[];
extern struct sched_class __sched_class_lowest[];
/*
* The order of the sched class addresses are important, as they are
* used to determine the order of the priority of each sched class in
* relation to each other.
*/
#define SCHED_DATA \
STRUCT_ALIGN(); \
__sched_class_highest = .; \
*(__stop_sched_class) \
*(__dl_sched_class) \
*(__rt_sched_class) \
*(__fair_sched_class) \
*(__idle_sched_class) \
__sched_class_lowest = .;
调度的主要逻辑:
// 通用的调度代码
__schedule
pick_next_task
__pick_next_task(rq, prev, rf)
// 可以看到需要一个 class 的 task 都被调度完了之后,才能
// 进行到下一个 class 里的 task 进行调度。
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
调度器类其实就是调度算法,同一时间一个调度器类只能有一个调度算法来实现。比如说 CFS 就是实现了 fair_sched_class:
// 通用调度源代码文件 kernel/sched/sched.h
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
// kernel/sched/fair.c 实现了 CFS 实现了 fair_sched_class
const struct sched_class fair_sched_class;
如果要使用另一个同属于 fair_sched_class 类的算法,可以实现一个新的调度算法在内核中。
enqueue_task() / enqueue_task_fair() Kernel
/*
* The enqueue_task method is called before nr_running is
* increased. Here we update the fair scheduling stats and
* then put the task into the rbtree:
*/
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int idle_h_nr_running = task_has_idle_policy(p);
int task_new = !(flags & ENQUEUE_WAKEUP);
/*
* The code below (indirectly) updates schedutil which looks at
* the cfs_rq utilization to select a frequency.
* Let's add the task's estimated utilization to the cfs_rq's
* estimated utilization, before we update schedutil.
*/
util_est_enqueue(&rq->cfs, p);
/*
* If in_iowait is set, the code below may not trigger any cpufreq
* utilization updates, so do it here explicitly with the IOWAIT flag
* passed.
*/
if (p->in_iowait)
cpufreq_update_util(rq, SCHED_CPUFREQ_IOWAIT);
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
cfs_rq->h_nr_running++;
cfs_rq->idle_h_nr_running += idle_h_nr_running;
if (cfs_rq_is_idle(cfs_rq))
idle_h_nr_running = 1;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(cfs_rq))
goto enqueue_throttle;
flags = ENQUEUE_WAKEUP;
}
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
update_load_avg(cfs_rq, se, UPDATE_TG);
se_update_runnable(se);
update_cfs_group(se);
cfs_rq->h_nr_running++;
cfs_rq->idle_h_nr_running += idle_h_nr_running;
if (cfs_rq_is_idle(cfs_rq))
idle_h_nr_running = 1;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(cfs_rq))
goto enqueue_throttle;
}
/* At this point se is NULL and we are at root level*/
add_nr_running(rq, 1);
/*
* Since new tasks are assigned an initial util_avg equal to
* half of the spare capacity of their CPU, tiny tasks have the
* ability to cross the overutilized threshold, which will
* result in the load balancer ruining all the task placement
* done by EAS. As a way to mitigate that effect, do not account
* for the first enqueue operation of new tasks during the
* overutilized flag detection.
*
* A better way of solving this problem would be to wait for
* the PELT signals of tasks to converge before taking them
* into account, but that is not straightforward to implement,
* and the following generally works well enough in practice.
*/
if (!task_new)
check_update_overutilized_status(rq);
enqueue_throttle:
assert_list_leaf_cfs_rq(rq);
hrtick_update(rq);
}
yield_task() / yield_task_fair() Kernel
在协程中,yield 函数表示我们主动让出 CPU,和等待 IO 所造成的被调度出去不同,我们并不需要等待什么事件发生才能运行,CPU 是我们主动让出来的,所以我们需要马上就入队。yield_task(…) 这个函数的行为基本上是出队,紧接着入队,除非 compat_yield sysctl 被开启。在那种情况下,它将调度实体放在红黑树的最右端。
.yield_task = yield_task_fair,
static void yield_task_fair(struct rq *rq)
{
struct task_struct *curr = rq->curr;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
struct sched_entity *se = &curr->se;
// Are we the only task in the tree?
// 如果我们是唯一的,那么不需要调度的别人,我们直接继续运行就好了
if (unlikely(rq->nr_running == 1))
return;
// Hierarchical cleanup of itself from next,last,skip so that it's not picked again
clear_buddies(cfs_rq, se);
// 更新下发生调度的时间
update_rq_clok(rq);
// Update run-time statistics of the 'current'.,比如更新下这个进程的 vruntime
update_curr(cfs_rq);
/*
* Tell update_rq_clock() that we've just updated,
* so we don't do microscopic update in schedule()
* and double the fastpath cost.
*/
rq_clock_skip_update(rq);
se->deadline += calc_delta_fair(se->slice, se);
}
CFS
完全公平调度(CFS)是一个针对普通进程的调度类,在 Linux 中称为 SCHED_NORMAL (在 POSIX 中称为 SCHED_OTHER),CFS 算法实现定义在文件 kernel/sched_fair.c 中。这个文件很大,因为除了核心调度逻辑,还包括了:
- 任务组调度;
- CPU 带宽控制;
- SMP 架构下的负载均衡等逻辑。
CFS 的前任是 O(1) scheduler。
内核为每个 CPU 维护了一个运行队列; CFS 有一个可配置的调度周期 sched_latency
所谓抢占,就是停止当前正在执行的任务,换另一个任务来执行。导致这种情况发生的原因很多,例如
- 当前任务已经运行了太长时间,需要让出 CPU;
- 用户修改了任务优先级,导致当前任务应该被换下;
- 或者优先级更高的任务被唤醒,需要立刻开始运行。
但当这种情况发生时,调度器并不会真的立刻切换任务,而是调用 resched_curr() 函数为当前任务设置一个叫着 TIF_NEED_RESCHED 的标记位。这个函数调用的地方非常多。真正切换的时候是???
CFS 相关 sysctl 可调参数
sysctl_sched
.sysctl_sched_latency : 24.000000
.sysctl_sched_min_granularity : 3.000000
.sysctl_sched_wakeup_granularity : 4.000000
.sysctl_sched_child_runs_first : 0
.sysctl_sched_features : 2382255931
.sysctl_sched_tunable_scaling : 1 (logarithmic)
-
kernel.sched_latency_ns: target latency for CFS. The target latency is the expected time period within which every runnable task should get a chance to run on the CPU. 在这个时间周期内,调度器会至少一次地调度所有运行队列中的任务 -
kernel.sched_min_granularity_ns: 一个进程被调度后的最小执行时间。 -
kernel.wakeup_granularity_ns:defines the minimum granularity at which the scheduler will consider preempting a currently running task for a newly awakened task. In simple terms, it sets a threshold below which a waking task will not immediately preempt a currently running task, even if the waking task has a higher priority. 从 wakeup 到 preempt 别人所需要经历的最小时间。
当一个进程正在运行中时,红黑树中有它吗?
没有,已经被移除了:
pick_next_task_fair
do {
se = pick_next_entity(cfs_rq, NULL);
// 将选中的进程从红黑树中移除
set_next_entity
// 在 enqueue task 的时候就已经置为 1 了
if (se->on_rq)
__dequeue_entity
// 从红黑树中移除
rb_erase_cached
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
但是注意 se->on_rq 还是为 true 的,所以不要搞混了运行队列和红黑树的区别,还是有一些微小差别的。
runqueue / struct rq / struct cfs_rq
struct rq 是每个 CPU 上的可运行进程队列,之前就已经存在,并不是 CFS 引入的。struct cfs_rq 是 CFS 调度器对其的一种封装。
实际上 CFS 还维护了 min/max vruntime,
- min vruntime 用途:新进程或重新回到 ready 状态的进程,用 vruntime=min_vruntime 来初始化,放到最左边;这对防止进程饥饿非常关键;
- max vruntime 用途:限额?
需要明确一个观点就是,CFS 运行队列里面包含有一个红黑树,但这个红黑树并不是 CFS 运行队列的全部,因为红黑树仅仅是用于选择出下一个调度程序的算法。很简单的一个例子,程序运行时,其并不在红黑树中,但是还是处于 CFS 运行队列中,其 on_rq 为真。只有准备退出、即将睡眠等待和转为实时进程的进程其 CFS 运行队列的 on_rq 为假。也就是说大致上 running task + rb tree task = run queue tasks。
Linux CFS 调度器:原理、设计与内核实现(2023)
Scheduling deadline
主要是在这个文档下面:Documentation/scheduler/sched-deadline.rst
调度周期/调度延迟(scheduling period/scheduling latency)/ sched_latency_ns / sched_nr_latency / sched_min_granularity
用户通过 sched_latency_ns 来控制调度延迟。调度延迟表示一个进程多久调度一次,调度周期表示所有进程多久调度一次,因此这两个概念其实可以看作是相等的。
从 CFS 的调度原理来考虑的话,CFS 似乎不需要调度周期的概念,因为 CFS 并不是预先给任务分配时间片,而是根据大家当前的运行时间来判断谁应该是下一个该执行的任务,这样所有任务都随着时间的推进齐头并进。但为了用来调度延迟,CFS 也需要引入调度周期。
那么 CFS 里调度延时怎么确定呢,没有时间片如何保证执行时间?
CFS 调度器和以往调度器不同之处在于没有时间片概念,而是分配 CPU 使用时间的比例。根据调度延迟,反推出每一个进程应该运行的时间(根据优先级),然后发现超过时间片后就触发调度(请看触发调度的时期/抢占调度/任务时间片耗尽)。
就是说所有进程被运行一次所需要的时间,所有进程以一定的比例分割其中的时间来运行。所以进程需运行时间 = 调度周期 * 进程权重 / 所有进程权重之和。
如果进程很多,那么可能每个进程每次运行的时间都很短,这浪费了大量的时间进行调度。所以引入了调度最小粒度的概念。除非进程进行了阻塞任务或者主动让出 CPU,否则进程至少执行调度最小粒度的时间。调度最小粒度称为 sysctl_sched_min_granularity,记录在 /proc/sys/sched_min_granulariry_ns 中,以纳秒为单位。
这个比值是一个调度延迟内允许的最大运行数目:
- 如果可运行进程个数小于
sched_nr_latency,调度周期等于调度延迟。 - 如果可运行进程超过了
sched_nr_latency,系统就不去理会调度延迟,转而保证调度最小粒度,这种情况下,调度周期等于最小粒度乘可运行进程个数。这在 kernel/sched/fair.c 中计算调度周期的函数可以看出来。
# 24000000 其实表示的是 24ms
cat /proc/sys/kernel/sched_latency_ns
24000000
echo 48000000 | sudo tee /proc/sys/kernel/sched_latency_ns
2.6.2.3 调度逻辑 - 调度周期 | Linux核心概念详解
调度节拍 / task_tick_fair()
计算机系统随着时钟节拍需要周期性地做很多事情,例如刷新屏幕、数据落盘等,而进程调度是众多任务中最重要的之一。周期性调度也叫调度节拍,它的入口是函数 scheduler_tick()。
该函数的主要任务有两个,一个是更新任务的各种时间信息;另一个是检查当前任务是否已经执行地足够久了,如果是的话就需要对其进行抢占,换其它任务来执行。所以调度节拍也叫做周期性调度,表示一个发生调度的时机。
During each tick, scheduler is called and if process/thread should be switched. But system timer frequency is pretty low (i.e. 1000 HZ, which means once in 1 ms), and if process have only 100us of its timeslice left, it will get extra time (under certain circumstances), while other processes are starve. However, modern CPUs provide more precision hardware timers like HPET on Intel, which are provided by hrtimers subsystem. They can be enabled for be used in scheduler by CONFIG_SCHED_HRTICK option.
请看这里对于初始化过程的说明:【时间子系统】三、时钟中断-定时基础
// start_kernel
// time_init
// x86_late_time_init
// x86_init.timers.timer_init()
// hpet_time_init
dev->event_handler = tick_handle_periodic;
tick_periodic
update_process_times
scheduler_tick()
curr->sched_class->task_tick();
.task_tick = task_tick_fair,
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
update_misfit_status(curr, rq);
check_update_overutilized_status(task_rq(curr));
task_tick_core(rq, curr);
}
实际运行时间(delta_exec)
调度延迟
看起来和调度周期是一个东西?
SCHED_NORMAL(SCHED_OTHER) 在 CFS 中是如何调度的
| SCHED_RR | SCHED_NORMAL | |
|---|---|---|
| 调度的进程类型 | 实时进程 | 普通进程 |
| 时间片 | 静态,不依赖系统中的进程数量 | 动态,根据进程数量会发生变化 |
| 下一个进程的选择 | 从 runqueue 中按 RR 选下一个 | 从红黑树中选 vruntime 小的那一个 |
SCHED_BATCH 在 CFS 中是如何调度的
适合批量任务。不像普通任务那样容易被抢占,因此每个任务运行的时间可以更长,缓存效率更高,但交互性变差。
SCHED_IDLE 在 CFS 中是如何调度的
This is even weaker than nice 19, but its not a true idle timer scheduler in order to avoid to get into priority inversion problems which would deadlock the machine.
struct cfs_rq
注意,cfs_rq 不是一个 CPU 一个,而是和进程组 task_group 绑定的。一个 task_group 在每一个 CPU 上都有一个 cfs_rq 结构体。所以从 CPU 的角度来看,其上面有很多个不同 task_group 的 cfs_rq 结构体。
其他的进程组和进程都包含在此运行队列 cfs_rq 中,当调度器从根 CFS 运行队列中选择了一个进程组进行调度时,进程组会从自己的 cfs_rq 中选择一个调度实体进行调度(这个调度实体可能为进程,也可能又是一个子进程组),就这样一直深入,直到最后选出一个进程进行运行为止。
设计这么个结构体来套住 rq 的原因是:
- Bandwidth Control 需要以此为粒度,但是直接用
rq又有很多不合理的地方。
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running;
unsigned int h_nr_running; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_nr_running; /* SCHED_IDLE */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock;
// CFS 算法里的 min_vruntime
u64 min_vruntime;
#ifdef CONFIG_SCHED_CORE
unsigned int forceidle_seq;
u64 min_vruntime_fi;
#endif
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root_cached tasks_timeline;
// 'curr' points to currently running entity on this cfs_rq.
// It is set to NULL otherwise (i.e when none are currently running).
struct sched_entity *curr;
struct sched_entity *next;
struct sched_entity *last;
struct sched_entity *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg;
#ifndef CONFIG_64BIT
u64 last_update_time_copy;
#endif
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_avg;
} removed;
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
long propagate;
long prop_runnable_sum;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
// cfs_rq 依附的 CPU runqueue,每个 CPU 有且仅有一个 rq 运行队列。
struct rq *rq; /* CPU runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.
* This list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
// 所属的 task_group
struct task_group *tg;
/* Locally cached copy of our task_group's idle value */
int idle;
#ifdef CONFIG_CFS_BANDWIDTH
// 是否打开了 Bandwidth Control 功能
int runtime_enabled;
// cfs_rq 从全局时间池申请的时间片剩余时间,
// 当剩余时间小于等于 0 的时候,就需要重新申请时间片,一般来说是 5ms。
s64 runtime_remaining;
u64 throttled_pelt_idle;
#ifndef CONFIG_64BIT
u64 throttled_pelt_idle_copy;
#endif
// 当 cfs_rq 被 throttle 的时候,方便统计被 throttle 的时间,
// 此成员为记录 throttle 开始的时间。
u64 throttled_clock;
u64 throttled_clock_pelt;
u64 throttled_clock_pelt_time;
// 如果此 cfs_rq 被 throttle 后,置 1,反之置 0。
// 置的时机是 throttle_cfs_rq^
int throttled;
// 由于 task_group 支持嵌套,当 parent task_group 的 cfs_rq 被 throttle 的时候,
// 其 child task_group 对应的 cfs_rq 的 throttle_count 成员计数增加。
int throttle_count;
// 被 throttle 的 cfs_rq 挂入 cfs_bandwidth->throttled_cfs_rq 链表。
struct list_head throttled_list;
#ifdef CONFIG_SMP
struct list_head throttled_csd_list;
#endif
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
update_curr() Kernel
当前正在运行的调度实体的 vruntime 主要就是在这里被更新的。
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
// 没有 curr,不需要更新。
if (unlikely(!curr))
return;
// 这个任务实际运行的时间,也就是现在的时间 - 这个任务开始运行的时间
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
// 我们已经有了 delta_exec,所以我们可以更新 exec_start,看作我们重新调度了这个任务
curr->exec_start = now;
// 一些统计相关的
// ...
// 更新这个进程总的实际运行时间
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
// 根据实际运行时间计算 vruntime,大多数情况下还是直接返回 delta_exec 因为大多数线程的 nice 是 0
// 所以 vruntime = 实际运行时间 * 1024 / 进程权重 = 实际运行时间 * 1024 / 1024 = 实际运行时间。
// 当 nice 非 0 时通过上述公式计算。
curr->vruntime += calc_delta_fair(delta_exec, curr);
// 更新 min_vruntime
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
//...
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
触发调度的时机
一个是置上 TIF_NEED_RESCHED,一个是真的调度,注意分清这两并不是同时发生的。
为什么不直接调度而是置上 flag 到后面的调度点再检查呢?我觉的是因为并不是在所有的时候调度都是合适的,或者说在一些时机进行调度是有利的,这样可以减小调度的开销。
抢占调度置 flag 的时机
置上 flag,后面被抢占的进程所在的 CPU 调用了 schedule() 函数后会检查此正在运行的进程是否有 flag 被置上了,如果置上了那么就进行调度。
- 任务运行时间耗尽,并不是直接就调度了,而是在 tick 的时候会检查,检查到耗尽了就会标。因为不是任务主动让出的,所以属于抢占式调度。
scheduler_tick
task_tick_fair
for_each_sched_entity(se) {
entity_tick
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr)
// 任务运行时间耗尽了
if (delta_exec > ideal_runtime) {
// 抢占吧
resched_curr(rq_of(cfs_rq));
set_tsk_need_resched(curr);
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
- 新任务被创建(更高优先级来争夺 CPU),也是仅仅是置上 flag。因为当前运行任务也不是主动让出 CPU 的,所以也属于抢占式调度。
kernel_clone
copy_process
// 检查新创建的任务是否需要抢占当前任务
wake_up_new_task
activate_task
// 将任务放入队列
enqueue_task
check_preempt_curr
// 判断是否需要抢占
sched_class.check_preempt_curr
// CFS's function
check_preempt_wakeup
// 置上 TIF_NEED_RESCHED,下次调度时将当前正在运行的这个任务换下
resched_curr
- 进程被 wakeup:某些任务会因为中断而唤醒,如当 I/O 到来的时候,I/O 进程往往会被唤醒。在这种时候,如果被唤醒的任务优先级高于 CPU 上的当前任务,就会触发抢占。因为正在运行的任务不是主动退出的,所以也是抢占式调度。
try_to_wake_up
ttwu_queue
ttwu_do_activate
// 判断是否抢占当前任务
check_preempt_curr
resched_curr
非抢占调度置 flag 的时机
非抢占调度表示是当前运行任务主动让出 CPU 的,所以其实通过其直接执行 schedule() 函数就可以了,比如进程调用了 sleep() 函数。非抢占调度不需要置 flag 会马上发生调度。
真正发生调度的时机(抢占点) / schedule()
发生在 schedule() 函数中。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
//...
__schedule(SM_NONE);
// 队列中选择下一个任务,会调用调度类中对应的方法
pick_next_task
// 上下文切换
context_switch
//...
// 判断当前正在运行的任务是否应该被抢占
} while (need_resched());
sched_update_worker(tsk);
}
schedule() 函数会在什么时候被调用?实际上会调用 __schedule() 函数共有以下几个时机:
- 系统调用返回用户态:表示在内核态运行的过程中,此进程因为一些原因比如时间片用完了需要被调度,以 64 位为例,系统调用的链路为:
do_syscall_64
syscall_exit_to_user_mode
__syscall_exit_to_user_mode_work
exit_to_user_mode_prepare
exit_to_user_mode_loop
if (ti_work & _TIF_NEED_RESCHED)
schedule();
-
内核态 enable preempt:内核态的执行中,被抢占的时机一般发生在
preempt_enable()中。在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用preempt_disable()关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会。
#ifdef CONFIG_PREEMPTION
#define preempt_enable() \
do { \
barrier(); \
if (unlikely(preempt_count_dec_and_test())) \
__preempt_schedule(); \
} while (0)
#define preempt_count_dec_and_test() \
({ preempt_count_sub(1); should_resched(0); })
should_resched
tif_need_resched
__preempt_schedule
preempt_schedule
preempt_schedule_common
__schedule(true);
-
从中断返回内核态/用户态(取决于是在哪里被中断的):中断处理调用的是
do_IRQ函数,中断完毕后分为两种情况,一个是返回用户态,一个是返回内核态。- 返回用户态会调用
prepare_exit_to_usermode(),最终调用exit_to_usermode_loop(); - 返回内核态会调用
preempt_schedule_irq(),最终调用__schedule()。
- 返回用户态会调用
-
当然,还有任务主动调用的情况。比如说
sleep()函数其实会调用到schedule()函数的。
linux_kernel_wiki/文章/进程管理/任务调度.md at main · 0voice/linux_kernel_wiki
vruntime
在真实 CPU 上,任意时间只能运行一个任务;为了实现“公平”,CFS 引入了 “virtual runtime”(虚拟运行时间)的概念。
-
vruntime表示进程真正在 CPU 上执行的时间,不包括任何形式的等待时间; - 注意机器一般都是多核的,因此
vruntime是在多个 CPU 上执行时间的累加。
哪个进程 vruntime 最小,说明累计执行时间最少,从“公平”的角度来说,就需要执行它。
- CFS 用红黑树来组织这些进程(描述
runqueue),用vruntime做 key, 所以这是一个基于时序的红黑树(time-ordered rbtree), 所有 runnable 的进程都是用p->se.vruntime作为 key 来排序的。 - CFS 每次取出最左边的进程(红黑树特性),执行完成后插入越来越右边,这样每个任务都有机会成为最左边的节点, 在一段确定是时间内总得得到 CPU 资源。
vruntime = 实际运行时间 * 1024 / 进程权重 。1024 其实就是 nice 为 0 的进程的权重。可以看出权重越高,vruntime 增加的速度越慢。
vruntime 的概念本身是不难理解的,但是当加入了其他因素比如抢占,进程 wakeup,进程创建,进程被调度到其他的 core 等等时,其是如何更新的呢?
- 进程在被
fork创建时:进程的状态会被设置为TASK_NEW(不会立即运行),会继承父进程优先级以及调度策略;在task_fork_fair()中会调用update_curr()来更新。
min_vruntime / update_min_vruntime()
最主要的逻辑就是在运行中的任务和当前 vruntime 最小的之间取一个最小值。
这是一个单调递增的值,主要用来计算归一化之后的 vruntime。
在调度时实际参考的时间为进程的 vruntime 减去 cfs_rq 的 min_vruntime
在进程 enqueue 或 dequeue 某一个 cfs_rq 时需要将自己的 vruntime 加减对应 cfs_rq 的 min_vruntime 来反归一化。计算最小运行时间可能采取的值:
- 当前正在运行的进程的最下虚拟时间,因为 CFS 调度器选择最适合运行的进程是选择维护的红黑树中 vruntime 最小的进程;所以当前正在运行的进程尽管已经运行了一段时间,仍有可能是最小的;
- 如果在当前进程运行的过程中,有进程加入就绪队列(当然也可能没有),那么红黑树最左边的进程的虚拟时间同样也有可能是最小的虚拟时间。
cfs_rq->min_vruntime 只在 update_min_vruntime() 这个函数里被更新到了:
static void update_min_vruntime(struct cfs_rq *cfs_rq)
{
// curr 表示当前正在运行的调度实体
struct sched_entity *curr = cfs_rq->curr;
struct rb_node *leftmost = rb_first_cached(&cfs_rq->tasks_timeline);
u64 vruntime = cfs_rq->min_vruntime;
if (curr) {
// 如果当前有任务在运行,那么 vruntime 设置为这个任务的 vruntime 后续比较
// 这个任务是在运行队列中的(难道还存在不在运行队列中的情况?)
if (curr->on_rq)
vruntime = curr->vruntime;
// 会存在正在运行但是 on_rq 不为真的情况吗?
// 理论上应该不可行,但是可能存在状态没有及时更新的情况?
else
curr = NULL;
}
// cfs_rq 红黑树是有内容的,说明队列不空,有可能有新的调度实体加入了运行队列
// 也有可能本来就有
if (leftmost) {
struct sched_entity *se = __node_2_se(leftmost);
// 如果当前没有正在运行的任务,那么直接设置为最左边的节点的 vruntime,红黑树的性质保证其肯定是最小的
if (!curr)
vruntime = se->vruntime;
else
// 如果有任务在运行,还是需要取一个最小值
vruntime = min_vruntime(vruntime, se->vruntime);
}
// ensure we never gain time by being placed backwards.
// 一路往大的地方更新
u64_u32_store(cfs_rq->min_vruntime, max_vruntime(cfs_rq->min_vruntime, vruntime));
}
这个函数在两个地方被调用了:
// 如果我们是 vruntime 最小的进程,我们要 dequeue,那么的确应该更新 min_vruntime
// 需要把 vruntime 调更大一些
dequeue_entity
/*
* When: DEQUEUE_SAVE && !DEQUEUE_MOVE, in this case we'll be
* put back on, and if we advance min_vruntime, we'll be placed back
* further than we started -- ie. we'll be penalized.
*/
if ((flags & (DEQUEUE_SAVE | DEQUEUE_MOVE)) != DEQUEUE_SAVE)
update_min_vruntime(cfs_rq);
// Update the current task's runtime statistics
update_curr
update_min_vruntime(cfs_rq);
Vruntime 的惩罚和奖励机制
-
新创建的进程
vruntime会受到惩罚,防止其恶意抢占:
task_fork_fair
place_entity(initial=1)
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
-
从睡眠中被唤醒的进程的
vruntime会受到奖励(可能是因为这个进程睡眠是主动让出来了 CPU,相比于被抢占更应该得到公平的待遇?):
enqueue_task_fair
enqueue_entity
if (flags & ENQUEUE_WAKEUP)
place_entity(cfs_rq, se, 0);
if (!initial)
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
CFS 配置项
CFS 的时间粒度是 ns,并不依赖任何 jiffies 或 HZ 信息。 有一个可调优的配置,(需要在编译内核时打开 CONFIG_SCHED_DEBUG):
- kernel < 5.15:
/proc/sys/kernel/sched_min_granularity_ns - kernel >= 5.15:
/sys/kernel/debug/sched/min_granularity_ns
可以通过调整这个参数来让调度器从 “desktop”(低延迟)到“server”(高并发)workloads。 默认配置适合的是 desktop workloads。
CONFIG_CFS_BANDWIDTH
给 CPU cgroup 引入了两个新配置项:
-
cpu.cfs_period_us: 周期(period),每个周期单独计算,周期结束之后状态(quota 等)清零;默认 100ms -
cpu.cfs_quota_us: 在一个周期里的份额(quota),默认 5ms。
CFS 调度负载均衡 / trigger_load_balance()
这个文章系列讲的非常好:
这个也不错:2.8 负载均衡 | Linux核心概念详解
从对于不同递进进程状态的处理,明确几个负载均衡的场景:
- 任务放置(task placement,刚刚 runnable 的机器):当阻塞的任务被唤醒的时候,确定该任务应该放置在哪个 CPU 上执行;
- 负载均衡(load balance,已经 runnable 还没有 running 的任务):通过搬移 cpu
runqueue上的任务,让各个 CPU 上的负载匹配 CPU 算力; - Active balance(running 的机器):指把当前正在运行的任务迁移到 dest cpu 上。也就是说经过前面一番折腾,runnable 的任务都无法迁移到 dest cpu,从而达到均衡,那么就考虑当前正在运行的任务。
可以理解为:
- 一个是第三者来执行 LB(tick)
- 一个是空闲的 CPU 主动拉;
- 一个是繁忙的 CPU 主动推。
分为三种情况:
-
周期性调度时会触发周期性负载均衡,负载均衡是一个比较耗时的操作,所以会让
softirq来处理。
scheduler_tick
#ifdef CONFIG_SMP
trigger_load_balance
// 周期性调度的负载均衡
void trigger_load_balance(struct rq *rq)
{
// Don't need to rebalance while attached to NULL domain or runqueue CPU is not active
// 如果我们没有 attach 任何 domain,那么不需要做 LB
if (unlikely(on_null_domain(rq) || !cpu_active(cpu_of(rq))))
return;
// 并不是每一个 tick 都要执行一次负载均衡,而是说我们需要一段时间比如说 60*HZ 之后执行一次
// 让 softirq 来处理
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
// 和 nohz 有关的。
nohz_balancer_kick(rq);
}
- new idle balance。调度器在 pick next 的时候,当前 CFS runqueue 中没有 runnable,只能执行 idle 线程,让 CPU 进入 idle 状态,这个时候可以主动一点拉别的 CPU 的线程过来:
pick_next_task
__pick_next_task_fair
pick_next_task_fair
newidle_balance
load_balance
- nohz idle load balance:其他的 CPU 已经进入 idle(当时此 CPU 变 idle 的时候并没有拉取到任务来跑),本 CPU 任务太重,需要通过 IPI 将其 idle 的 CPU 唤醒来进行负载均衡。2.8.5 触发时机 | Linux核心概念详解 这篇文章讲的很好。为什么叫 NOHZ load balance 呢?那是因为这个 balancer 只有在内核配置了 NOHZ(即 tickless mode)下才会生效。如果 CPU 进入 idle 之后仍然有周期性的 tick,那么通过 tick load balance 就能完成负载均衡了,不需要 IPI 来唤醒 idle 的 cpu。和周期性均衡一样,NOHZ idle load balance 也是通过 busy cpu 上 tick 驱动的。
sched_init
// 初始化 NOHZ 负载均衡的 IPI 处理函数,该函数会在函数 kick_ilb 中被调用
INIT_CSD(&rq->nohz_csd, nohz_csd_func, rq);
// timer 中断
scheduler_tick
trigger_load_balance
nohz_balancer_kick
kick_ilb
// 发送 IPI 到 idle CPU
smp_call_function_single_async
// IPI handle
nohz_csd_func
raise_softirq_irqoff
// softirq 处理,和周期性负载均衡的链路是一样的
什么是 CPU 负载(Load)?
现代调度器往往使用 CPU runqueue 上 task load 之和来表示 CPU load。这样,对 CPU 负载的跟踪就变成了对任务负载的跟踪。内核引入了 PELT 算法来跟踪每一个 sched entity 的负载,把负载跟踪的算法从 per-CPU 进化到 per-entity。PELT 算法不但能知道 CPU 的负载,而且知道负载来自哪一个调度实体,从而可以更精准的进行负载均衡。
什么是均衡
考虑系统中各个 CPU 的算力,让 CPU 获得和其算力匹配的负载,比如大小核架构。
什么是算力(CPU Capacity)
struct rq {
// ...
// 这个算力需要把 CPU 用于执行 rt、dl、irq 的算力以及温控损失的算力去掉
// update_cpu_capacity 会更新
// 系统中处理能力最强的 CPU 运行在最高频率的算力是 1024,其他的 CPU 算力根据微架构和最大运行频率相应的进行调整。
unsigned long cpu_capacity; // 可以用于 CFS 任务的算力
unsigned long cpu_capacity_orig; // 该 CPU 的原始算力,和微架构及其最大频率相关
}
LB 相关 sysctl / sched_nr_migrate / sched_migration_cost
-
kernel.sched_nr_migrate:每次最多同时迁移的任务数量; -
kernel.sched_migration_cost:如果为 -1,进程 Cache 恒为热,为 0 进程 Cache 恒为冷。如果进程开始执行的时间到当前时间的间隔小于sysctl_sched_migration_cost说明 Cache 是热的(虽然后面停止了,但是 cache 还是有一部分在的)。为什么叫做 migration cost 呢,因为时间越长,可能 cache 累积的越多,因此 migrate 起来的消耗就越大。如果平均 idle 时间都小于这个值,那么就没必要 load balance 了,因为 load balance 过程还没完新的任务就要来了。这个为什么是一个可以配置的值呢,不应该是内核根据经验来动态更新吗?
task_hot
if (sysctl_sched_migration_cost == -1)
return 1;
if (sysctl_sched_migration_cost == 0)
return 0;
return delta < (s64)sysctl_sched_migration_cost;
-
kernel.sched_domain.cpu108.domain2.max_newidle_lb_costtracks the maximum cost, per domain, of idle load balancing.
Misfit task
Mis-fit task,表示这个 task 放错地方了。
当它从 runqueue 中取出并开始执行时,便处于运行状态,若该状态下的任务负载不是当前 CPU 所能承受的,那么调度器会将其标记为 misfit task,周期性地触发主动迁移(active upmigration),将 misfit task 布置到更高算力的 CPU。
如何判断 CPU 能不能承受任务负载呢?
rebalance_domains() Kernel
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
run_rebalance_domains
// 如果 domain 之间不均衡,那么就触发 balance
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
// 因为 lb 有很多不同的 level,这个表示只在当前 level 做 load balancing
// 还是说一路往上面的每一个 level 都要做 load balancing
int continue_balancing = 1;
int cpu = rq->cpu;
int busy = idle != CPU_IDLE && !sched_idle_cpu(cpu);
unsigned long interval;
struct sched_domain *sd;
// 这次做了 balance,下一次做 balance 的间隔时间
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
int need_serialize, need_decay = 0;
u64 max_cost = 0;
//...
// 遍历的顺序是一路从 base domain 遍历到最上面的 root domain
// 越是上层的 domain,其覆盖的 cpu 就越多,如果每一个 CPU 的周期性负载均衡都对高层 domain 进行均衡
// 那么高层 domain 被撸的遍数也太多了,所以这里通过 continue_balancing 控制均衡的 level。
for_each_domain(cpu, sd) {
// max_newidle_lb_cost 是 domain 上的最大 newidle load balance 的开销。
// 这个开销会随着时间进行衰减,每秒衰减 1%(每次在这里检查有没有超过 1s)。
// 衰减的原因是我们不想让很久之前的任务影响现在的纪录,所以衰减可以看作是一种对于过去 cost 的记忆的淡化。
// need_decay 表示是否这次触发了 decay 衰减。
need_decay = update_newidle_cost(sd, 0);
max_cost += sd->max_newidle_lb_cost;
/*
* Stop the load balance at this level. There is another
* CPU in our sched group which is doing load balancing more actively.
*/
if (!continue_balancing) {
if (need_decay)
continue;
break;
}
interval = get_sd_balance_interval(sd, busy);
need_serialize = sd->flags & SD_SERIALIZE;
if (need_serialize) {
if (!spin_trylock(&balancing))
goto out;
}
// 上次发生 load balance 的时间
if (time_after_eq(jiffies, sd->last_balance + interval)) {
// 做 load balance
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
busy = idle != CPU_IDLE && !sched_idle_cpu(cpu);
}
sd->last_balance = jiffies;
interval = get_sd_balance_interval(sd, busy);
}
if (need_serialize)
spin_unlock(&balancing);
out:
if (time_after(next_balance, sd->last_balance + interval)) {
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
if (need_decay) {
/*
* Ensure the rq-wide value also decays but keep it at a
* reasonable floor to avoid funnies with rq->avg_idle.
*/
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
//...
/*
* next_balance will be updated only when there is a need.
* When the cpu is attached to null domain for ex, it will not be
* updated.
*/
if (likely(update_next_balance))
rq->next_balance = next_balance;
}
sysctl -a | grep lb_cost 可以用来抓负载均衡的 cost。
kernel.sched_domain.cpu108.domain2.max_newidle_lb_cost tracks the maximum cost, per domain, of idle load balancing.
load_balance() / Kernel
load_balance函数代码详解:这一篇文章讲这个函数真的太好了,每一行都有解释,值得一读。
返回值为负载均衡迁移的任务总数。参数为:
-
this_cpu:本次要进行负载均衡的 CPU。需要注意的是:对于 new idle balance 和 tick balance 而言,this_cpu等于 current cpu,在 nohz idle balance 场景中,this_cpu 未必等于 current cpu。 -
sd:本次均衡的范围,即本次均衡要保证该 domain 上各个 group 处于负载平衡状态 -
idle:this_cpu在发起均衡的时候所处的状态,通过这个状态可以识别 new idle load balance 和 tick balance。 -
continue_balancing:负载均衡是从发起 CPU 的 base domain 开始,不断向上,直到顶层的 domain。continue_balancing 是用来控制是否继续进行上层 domain 的均衡
// Check this_cpu to ensure it is balanced within domain. Attempt to move tasks if there is an imbalance.
// 本次要进行负载均衡的 CPU。需要注意的是:对于 new idle balance 和 tick balance 而言,this_cpu 等于 current cpu,在 nohz idle balance 场景中,this_cpu 未必等于 current cpu。
// sd: 本次均衡的范围,即本次均衡要保证该sched domain上各个group处于负载平衡状态
// idle:this_cpu 在发起均衡的时候所处的状态,通过这个状态可以识别 new idle load balance 和 tick balance。
// continue_balancing:负载均衡是从发起 CPU 的 base domain 开始,不断向上,直到顶层的 domain。continue_balancing 是用来控制是否继续进行上层 domain 的均衡
static int load_balance(int this_cpu, struct rq *this_rq, struct sched_domain *sd, enum cpu_idle_type idle,
int *continue_balancing)
{
int ld_moved, cur_ld_moved, active_balance = 0;
struct sched_domain *sd_parent = sd->parent;
struct sched_group *group;
struct rq *busiest;
struct rq_flags rf;
struct cpumask *cpus = this_cpu_cpumask_var_ptr(load_balance_mask);
struct lb_env env = {
.sd = sd,
.dst_cpu = this_cpu,
.dst_rq = this_rq,
.dst_grpmask = group_balance_mask(sd->groups),
.idle = idle,
.loop_break = SCHED_NR_MIGRATE_BREAK,
.cpus = cpus,
.fbq_type = all,
.tasks = LIST_HEAD_INIT(env.tasks),
};
// 确定本轮负载均衡涉及的 cpu,因为是第一轮均衡,所以 domain 中的所有 cpu 都参与均衡
cpumask_and(cpus, sched_domain_span(sd), cpu_active_mask);
//
schedstat_inc(sd->lb_count[idle]);
redo:
// 判断 dst_cpu 这个 CPU 是否适合做 domain 的均衡。如果被认定不适合发起 balance,
// 那么后续更高层 level 的均衡也不必进行了(设置 continue_balancing 等于 0)。
// 在 base domain,每个 group 都只有一个CPU,因此所有的 cpu 都可以发起均衡。
// 在 non-base domain,每个 group 有多个 CPU,如果每一个cpu都可以进行均衡,那么均衡就太密集了,
// 白白消耗 CPU 资源,所以限制只有第一个 idle 的 cpu 可以发起均衡,如果没有 idle 的 CPU,那么 group 中的第一个
// CPU 可以发起均衡。当然,对于 new idle balance 没有这样的限制,所以的 cpu 都可以发起均衡。
if (!should_we_balance(&env)) {
*continue_balancing = 0;
goto out_balanced;
}
// 在该 sched domain 中寻找最繁忙的 sched group。具体逻辑后文会详细描述。
// 如果没有找到 busiest group,那么退出本 level 的均衡
group = find_busiest_group(&env);
if (!group) {
schedstat_inc(sd->lb_nobusyg[idle]);
goto out_balanced;
}
// 在最繁忙的 sched group 寻找最繁忙的 CPU。具体逻辑后文会详细描述。
// 如果没有找到 busiest cpu,那么退出本 level 的均衡
busiest = find_busiest_queue(&env, group);
if (!busiest) {
schedstat_inc(sd->lb_nobusyq[idle]);
goto out_balanced;
}
// src 和 dst 不可以相等
WARN_ON_ONCE(busiest == env.dst_rq);
schedstat_add(sd->lb_imbalance[idle], env.imbalance);
// 将 busiest 设置为 source
env.src_cpu = busiest->cpu;
env.src_rq = busiest;
ld_moved = 0;
// Clear this flag as soon as we find a pullable task
env.flags |= LBF_ALL_PINNED;
// 至此已经找到了source CPU,dest cpu 就是发起均衡的 this cpu,那么就可以开始第一轮的任务迁移了,
// 如果要从 busiest cpu 迁移任务到 this cpu,那么至少要有可以拉取的任务,
// 只有一个任务也不行,因为拉过去之后还是不平衡。
if (busiest->nr_running > 1) {
/*
* Attempt to move tasks. If find_busiest_group has found
* an imbalance but busiest->nr_running <= 1, the group is
* still unbalanced. ld_moved simply stays zero, so it is
* correctly treated as an imbalance.
*/
// 遍历 src rq 上的任务,看看哪些任务最适合被迁移到 this cpu rq
// loop_max 就是扫描 src rq 上 runnable任务的次数(每扫一次确定一个要迁移的任务)。
// 一般而言,任务迁移上限就是 busiest runqueue 上的任务个数,
// 确保了每一个任务都被扫描到,但是一次均衡操作不适合迁移太多的任务(关中断区间太长),
// 因此,即便 busiest runqueue 上的任务个数非常多,一次任务迁移不能大于 sysctl_sched_nr_migrate 个(目前设定是32个)。
env.loop_max = min(sysctl_sched_nr_migrate, busiest->nr_running);
// 新一轮迁移不需要寻找 busiest cpu,只是继续扫描 busiest rq 上的任务列表,寻找适合迁移的任务。
more_balance:
// 关中断
rq_lock_irqsave(busiest, &rf);
update_rq_clock(busiest);
/*
* cur_ld_moved - load moved in current iteration
* ld_moved - cumulative load moved across iterations
*/
// detach_tasks 函数用来从 busiest rq 中摘取适合的任务。
// 由于关中断时长的问题,detach_tasks 函数也不会一次性把所有任务迁移到 dest cpu 上。
cur_ld_moved = detach_tasks(&env);
/*
* We've detached some tasks from busiest_rq. Every
* task is masked "TASK_ON_RQ_MIGRATING", so we can safely
* unlock busiest->lock, and we are able to be sure
* that nobody can manipulate the tasks in parallel.
* See task_rq_lock() family for the details.
*/
rq_unlock(busiest, &rf);
// 一个 int,表示我们有任务被摘下来了
if (cur_ld_moved) {
// 将 detach_tasks() 函数摘下的任务(存到 env 里了?)加入到 dst rq 上去。
// 由于 detach_tasks、attach_tasks 会进行多轮,ld_moved 记录了**总共**迁移的任务数量
attach_tasks(&env);
ld_moved += cur_ld_moved;
}
// 开中断
local_irq_restore(rf.flags);
if (env.flags & LBF_NEED_BREAK) {
env.flags &= ~LBF_NEED_BREAK;
// Stop if we tried all running tasks
// 在任务迁移过程中,src cpu 的中断是关闭的,
// 为了降低这个关中断时间,迁移大量任务的时候需要 break 一下。
if (env.loop < busiest->nr_running)
goto more_balance;
}
// 至此已经对 dest rq 上的任务列表完成了 loop_max 次扫描,要看情况是否要发起下一轮次的均衡。
/*
* Revisit (affine) tasks on src_cpu that couldn't be moved to
* us and move them to an alternate dst_cpu in our sched_group
* where they can run. The upper limit on how many times we
* iterate on same src_cpu is dependent on number of CPUs in our
* sched_group.
*
* This changes load balance semantics a bit on who can move
* load to a given_cpu. In addition to the given_cpu itself
* (or a ilb_cpu acting on its behalf where given_cpu is
* nohz-idle), we now have balance_cpu in a position to move
* load to given_cpu. In rare situations, this may cause
* conflicts (balance_cpu and given_cpu/ilb_cpu deciding
* _independently_ and at _same_ time to move some load to
* given_cpu) causing excess load to be moved to given_cpu.
* This however should not happen so much in practice and
* moreover subsequent load balance cycles should correct the
* excess load moved.
*/
if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) {
/* Prevent to re-select dst_cpu via env's CPUs */
__cpumask_clear_cpu(env.dst_cpu, env.cpus);
env.dst_rq = cpu_rq(env.new_dst_cpu);
env.dst_cpu = env.new_dst_cpu;
env.flags &= ~LBF_DST_PINNED;
env.loop = 0;
env.loop_break = SCHED_NR_MIGRATE_BREAK;
/*
* Go back to "more_balance" rather than "redo" since we
* need to continue with same src_cpu.
*/
// 如果 sched domain 仍然未达均衡状态,并且在之前的均衡过程中,
// 有因为 affinity 的原因导致任务无法迁移到 dest cpu,这时候要继续在 src rq 上搜索任务,
// 迁移到备选的 dest cpu,因此,这里再次发起均衡操作。
// 这里的均衡上下文的 dest cpu 设定为备选的 cpu,loop 也被清零,重新开始扫描。
goto more_balance;
}
/*
* We failed to reach balance because of affinity.
*/
// 本层次的 sched domain 因为 affinity 而无法达到均衡状态,
// 我们需要把这个状态标记到上层 sched domain 的 group 中去,在上层 sched domain 进行均衡的时候,
// 该 group 会被判定为 group_imbalanced,从而有更大的机会选定为 busiest group,从而解决该 domain 的均衡问题。
if (sd_parent) {
int *group_imbalance = &sd_parent->groups->sgc->imbalance;
if ((env.flags & LBF_SOME_PINNED) && env.imbalance > 0)
*group_imbalance = 1;
}
/* All tasks on this runqueue were pinned by CPU affinity */
if (unlikely(env.flags & LBF_ALL_PINNED)) {
__cpumask_clear_cpu(cpu_of(busiest), cpus);
/*
* Attempting to continue load balancing at the current
* sched_domain level only makes sense if there are
* active CPUs remaining as possible busiest CPUs to
* pull load from which are not contained within the
* destination group that is receiving any migrated
* load.
*/
if (!cpumask_subset(cpus, env.dst_grpmask)) {
env.loop = 0;
env.loop_break = SCHED_NR_MIGRATE_BREAK;
// 如果选中的 busiest cpu 上的任务全部都是通过 affinity 锁定在了该 cpu 上,
// 那么清除该 cpu(为了确保下轮均衡不考虑该 cpu ),再次发起均衡。这种情况下,
// 需要重新搜索 source cpu,因此跳转到 redo。
goto redo;
}
goto out_all_pinned;
}
}
// 至此,src rq 上的 cfs 任务链表已经被遍历(也可能遍历多次),
// 基本上对 runnable 任务的扫描已经到位了,如果不行就只能考虑 **running** task 了,
// 也就是把正在跑的 task 的具体代码逻辑如下:
if (!ld_moved) {
schedstat_inc(sd->lb_failed[idle]);
/*
* Increment the failure counter only on periodic balance.
* We do not want newidle balance, which can be very
* frequent, pollute the failure counter causing
* excessive cache_hot migrations and active balances.
*/
if (idle != CPU_NEWLY_IDLE)
// 经过上面的一系列操作,没有完成任何任务的迁移,那么就需要累计 sched domain 的均衡失败次数。
// 这个失败次数会导致后续进行更激进的均衡,例如迁移 cache hot 的任务、启动 active balance。
// 此外,这里过滤掉了 new idle balance 的失败,仅统计周期性均衡失败的次数,
// 这是因为系统中 new idle balance 次数太多,
// 累计其失败次数会导致 nr_balance_failed 过大,容易触发后续激进的均衡。
sd->nr_balance_failed++;
// 判断是否要启动 active balance^
if (need_active_balance(&env)) {
unsigned long flags;
raw_spin_rq_lock_irqsave(busiest, flags);
/*
* Don't kick the active_load_balance_cpu_stop,
* if the curr task on busiest CPU can't be
* moved to this_cpu:
*/
if (!cpumask_test_cpu(this_cpu, busiest->curr->cpus_ptr)) {
raw_spin_rq_unlock_irqrestore(busiest, flags);
// 在启动 active balance 之前,先看看 busiest cpu 上当前正在运行的任务,
// 是否可以运行在 dest cpu 上。如果不可以的话,那么不再试图执行均衡操作,跳转到 out_one_pinned
goto out_one_pinned;
}
/* Record that we found at least one task that could run on this_cpu */
env.flags &= ~LBF_ALL_PINNED;
/*
* ->active_balance synchronizes accesses to
* ->active_balance_work. Once set, it's cleared
* only after active load balance is finished.
*/
// Busiest cpu runqueue 上设置 active balance 的标记
if (!busiest->active_balance) {
busiest->active_balance = 1;
busiest->push_cpu = this_cpu;
active_balance = 1;
}
raw_spin_rq_unlock_irqrestore(busiest, flags);
// 发起主动迁移
if (active_balance) {
stop_one_cpu_nowait(cpu_of(busiest),
active_load_balance_cpu_stop, busiest,
&busiest->active_balance_work);
}
}
} else {
// 完成了至少一个任务迁移,重置均衡失败计数
sd->nr_balance_failed = 0;
}
// 后面部分程序逻辑主要是进行一些清理工作和设定balance_interval的工作,逻辑比较简单,不再详述
if (likely(!active_balance) || need_active_balance(&env)) {
/* We were unbalanced, so reset the balancing interval */
sd->balance_interval = sd->min_interval;
}
goto out;
out_balanced:
/*
* We reach balance although we may have faced some affinity
* constraints. Clear the imbalance flag only if other tasks got
* a chance to move and fix the imbalance.
*/
if (sd_parent && !(env.flags & LBF_ALL_PINNED)) {
int *group_imbalance = &sd_parent->groups->sgc->imbalance;
if (*group_imbalance)
*group_imbalance = 0;
}
out_all_pinned:
/*
* We reach balance because all tasks are pinned at this level so
* we can't migrate them. Let the imbalance flag set so parent level
* can try to migrate them.
*/
schedstat_inc(sd->lb_balanced[idle]);
sd->nr_balance_failed = 0;
out_one_pinned:
ld_moved = 0;
/*
* newidle_balance() disregards balance intervals, so we could
* repeatedly reach this code, which would lead to balance_interval
* skyrocketing in a short amount of time. Skip the balance_interval
* increase logic to avoid that.
*/
if (env.idle == CPU_NEWLY_IDLE)
goto out;
/* tune up the balancing interval */
if ((env.flags & LBF_ALL_PINNED &&
sd->balance_interval < MAX_PINNED_INTERVAL) ||
sd->balance_interval < sd->max_interval)
sd->balance_interval *= 2;
out:
return ld_moved;
}
What is newidle balance
Load-balancing performed when a CPU just became idle. 表示我们 idle 了,所以这个 core 要从别的地方抢活来做。
queue_balance_callback() Kernel
调度域(Schedule domain)/ 调度组(Schedule group)/ CPU Cluster / MC
调度域是调度器进行负载均衡的基础。每一个 CPU 关联一个最底层的调度域。
NUMA -> Socket -> Core-> HT.
越往后调度成本越低,所以我们优先将一个 task 调度到同一个 Core 的不同 HT,然后同一个 Socket 的不同 Core,以此类推。
// 将调度域建立起来的代码
sched_init_smp
sched_init_domains
build_sched_domains
系统的调度域拓扑用 sched_domain_topology_level[] 数组表示,保存在全局变量 sched_domain_topology 中,数组的每一个元素代表一个层级。
static struct sched_domain_topology_level *sched_domain_topology = default_topology;
static struct sched_domain_topology_level default_topology[] = {
// SMT level, smt mask 应该包含了超线程的两个核
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
// 所有 share l2 cache 的叫做一个 cluster
// 一些处理器可能使用混合设计,即某些核心之间共享 L2 缓存,而其他核心则有自己的专用 L2 缓存
{ cpu_clustergroup_mask, cpu_cluster_flags, SD_INIT_NAME(CLS) },
// 一个 MC(multi core)
// cpu_coregroup_mask 指定了 CPU mask 位图,其实就是
// cpu_llc_shared_mask,这些 mask 是 share l3 CPU 的。
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
// 一个 die,或者说所有的 CPU?
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
// NUMA
{ NULL, },
};
// 描述一层调度域拓扑
struct sched_domain_topology_level {
sched_domain_mask_f mask;
sched_domain_flags_f sd_flags;
int flags;
int numa_level;
struct sd_data data;
//...
};
有 3 个数据结构和调度域相关:
-
struct sched_domain:调度域代表可以共享属性和调度参数的一组 CPU。每个 CPU 在每一个调度域拓扑层级中都有一个sched_domain对象。 -
struct sched_group:调度域可以由一个或多个调度组构成,每个调度组也代表可以共享属性和调度参数的一组 CPU,属于同一个调度域的调度组的集合组成了调度域代表的 CPU。调度域进行负载均衡的目的就是要保证其内部各个调度组之间的负载均衡。 -
struct sched_capacity:包含了调度组的 captacity 内容,和调度组管理的 CPU 的能力强相关。
为什么要设置一个调度组 sched_group 的概念呢?负载均衡调度的最小单元是调度组,每个调度域进行分组。因为这是一个树形的结构,从一层上往下看,其实只能看到下面的调度域,所以我觉得可以把一个调度域的子调度域看作是调度组。
- The union of cpumasks of these groups MUST be the same as the domain’s span.
- The intersection of cpumasks from any two of these groups MUST be the empty set.
简而言之,调度组是对调度域的一个划分。
Groups may be shared among CPUs as they contain read only data after they have been set up. only when the load of a group becomes out of balance are tasks moved between groups.
那么为什么要设置调度组呢?所有的调度域已经以树型结构组织起来了,直接遍历子树不就相当于调度组了吗?我觉得可能偏向是不同的,因为调度域主要关注的是纵向的关系,调度组关注的是横向的关系(调度组并不存在父子的结构,而是横向的结构,因为 load balancer 仅仅关注调度组之间的负载均衡):
struct sched_domain {
/* These fields must be setup */
struct sched_domain __rcu *parent; /* top domain must be null terminated */
struct sched_domain __rcu *child; /* bottom domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
// tracks the maximum cost, per domain, of idle load balancing.
// 在这个 domain 内部进行负载均衡的开销
// 每次在这个域内做负载均衡所花的时间都会被记录下来,如果
// CPU idle 时间 < 花在 idle balancing + the max cost of idle balancing in the sched domain
// 我们就不会去做 load balance 了
// 也就是说,如果 load balancing 本身的 cost 比较大,我们 idle 本身就是想要 load balance 从
// 别的地方拿活,如果拿到的活 + load balance 本身让我们也不堪重负了,那么就不需要再抢活做了
u64 max_newidle_lb_cost;
// SD_LOAD_BALANCE: 表示这个 domain 允许进行负载均衡
// SD_BALANCE_NEWIDLE:允许进入 idle 时负载均衡
// SD_BALANCE_EXEC:exec 时进行均衡
// SD_BALANCE_FORK:fork 时均衡
// SD_BALANCE_WAKE:任务唤醒时均衡
// SD_WAKE_AFFINE:任务唤醒时放到临近 CPU
int flags;
// 这个 domain 覆盖的 CPU 的数量
unsigned int span_weight;
// 该字段用来描述当前 sd 覆盖了哪些 CPU,父调度域的 span 应该是其所有子调度域的超集。
unsigned long span[];
// 检查负载均衡的最小时间间隔,过于频繁的检查会造成系统产生额外开销
unsigned long min_interval;
// 检查负载均衡的最大时间间隔,太长时间不检查容易导致负载偏差太大
unsigned long max_interval;
//...
}
struct sched_group {
struct sched_group *next; /* Must be a circular list */
//...
};
注意调度组和组调度的区别,调度组是 sched_group,组调度是 cgroup。
Scheduler Domains — The Linux Kernel documentation
can_migrate_task() / Kernel
// can_migrate_task - may task p from runqueue rq be migrated to this_cpu?
static int can_migrate_task(struct task_struct *p, struct lb_env *env)
{
int tsk_cache_hot;
//...
/*
* We do not migrate tasks that are:
* 1) throttled_lb_pair, or
* 2) cannot be migrated to this CPU due to cpus_ptr, or
* 3) running (obviously), or
* 4) are cache-hot on their current CPU.
*/
if (throttled_lb_pair(task_group(p), env->src_cpu, env->dst_cpu))
return 0;
/* Disregard pcpu kthreads; they are where they need to be. */
if (kthread_is_per_cpu(p))
return 0;
if (!cpumask_test_cpu(env->dst_cpu, p->cpus_ptr)) {
int cpu;
schedstat_inc(p->stats.nr_failed_migrations_affine);
env->flags |= LBF_SOME_PINNED;
/*
* Remember if this task can be migrated to any other CPU in
* our sched_group. We may want to revisit it if we couldn't
* meet load balance goals by pulling other tasks on src_cpu.
*
* Avoid computing new_dst_cpu
* - for NEWLY_IDLE
* - if we have already computed one in current iteration
* - if it's an active balance
*/
if (env->idle == CPU_NEWLY_IDLE ||
env->flags & (LBF_DST_PINNED | LBF_ACTIVE_LB))
return 0;
/* Prevent to re-select dst_cpu via env's CPUs: */
for_each_cpu_and(cpu, env->dst_grpmask, env->cpus) {
if (cpumask_test_cpu(cpu, p->cpus_ptr)) {
env->flags |= LBF_DST_PINNED;
env->new_dst_cpu = cpu;
break;
}
}
return 0;
}
/* Record that we found at least one task that could run on dst_cpu */
env->flags &= ~LBF_ALL_PINNED;
if (task_on_cpu(env->src_rq, p)) {
schedstat_inc(p->stats.nr_failed_migrations_running);
return 0;
}
/*
* Aggressive migration if:
* 1) active balance
* 2) destination numa is preferred
* 3) task is cache cold, or
* 4) too many balance attempts have failed.
*/
if (env->flags & LBF_ACTIVE_LB)
return 1;
tsk_cache_hot = migrate_degrades_locality(p, env);
if (tsk_cache_hot == -1)
tsk_cache_hot = task_hot(p, env);
if (tsk_cache_hot <= 0 || env->sd->nr_balance_failed > env->sd->cache_nice_tries) {
if (tsk_cache_hot == 1) {
schedstat_inc(env->sd->lb_hot_gained[env->idle]);
schedstat_inc(p->stats.nr_forced_migrations);
}
return 1;
}
schedstat_inc(p->stats.nr_failed_migrations_hot);
return 0;
}
balance_callback() Kernel
这个函数的作用到底是啥?
static inline void balance_callback(struct rq *rq)
{
if (unlikely(rq->balance_callback))
__balance_callback(rq);
}
static noinline void __balance_callback(struct rq *rq)
{
struct callback_head *head, *next;
void (*func)(struct rq *rq);
unsigned long flags;
raw_spin_rq_lock_irqsave(rq, flags);
head = rq->balance_callback;
rq->balance_callback = NULL;
while (head) {
func = (void (*)(struct rq *))head->func;
next = head->next;
head->next = NULL;
head = next;
// 调了链表里的所有的函数,
func(rq);
}
raw_spin_rq_unlock_irqrestore(rq, flags);
}
migrate_degrades_locality() Kernel
- Returns 1, if task migration degrades locality
- Returns 0, if task migration improves locality i.e migration preferred.
- Returns -1, if task migration is not affected by locality.
static int migrate_degrades_locality(struct task_struct *p, struct lb_env *env)
{
struct numa_group *numa_group = rcu_dereference(p->numa_group);
unsigned long src_weight, dst_weight;
int src_nid, dst_nid, dist;
if (!static_branch_likely(&sched_numa_balancing))
return -1;
if (!p->numa_faults || !(env->sd->flags & SD_NUMA))
return -1;
src_nid = cpu_to_node(env->src_cpu);
dst_nid = cpu_to_node(env->dst_cpu);
if (src_nid == dst_nid)
return -1;
// Migrating away from the preferred node is always bad.
if (src_nid == p->numa_preferred_nid) {
// 如果本来就已经跑在了 prefer 的 node 上,同时
// src rq 是有任务希望跑在 rq 对面的 numa node 上的,这说明我们
// 我们要迁移的这个任务更希望跑在现在的 node 上,这说明我们更应该
// 选那些不在的来。
if (env->src_rq->nr_running > env->src_rq->nr_preferred_running)
return 1;
else
return -1;
}
// Encourage migration to the preferred node.
// 这个任务偏向于跑在这个 numa node
if (dst_nid == p->numa_preferred_nid)
return 0;
/* Leaving a core idle is often worse than degrading locality. */
if (env->idle == CPU_IDLE)
return -1;
dist = node_distance(src_nid, dst_nid);
if (numa_group) {
src_weight = group_weight(p, src_nid, dist);
dst_weight = group_weight(p, dst_nid, dist);
} else {
src_weight = task_weight(p, src_nid, dist);
dst_weight = task_weight(p, dst_nid, dist);
}
return dst_weight < src_weight;
}
CFS 负载均衡相关数据结构
struct lb_env / Kernel
struct lb_env {
// 要进行负载均衡的 domain,注意是 src 所在的 domain,dst 应该不一定在这个 domain 里?
struct sched_domain *sd;
// 该 domain 中最忙的 CPU 以及 runqueue。
struct rq *src_rq;
int src_cpu;
// 均衡的目标 CPU,均衡操作试图从该 domain 的最忙的 cpu 的 runqueue 拉取任务到 dest CPU rq,
// 从而完成本次均衡动作。第一轮均衡的 dst cpu 和 dst rq 一般设置为发起均衡的 cpu 及其 runqueue
//(因为发起者比较闲,可以承接任务),后续如果需要,可以重新设定为 local group 中的其他 cpu。
int dst_cpu;
struct rq *dst_rq;
// dst CPU 所在的 cpu group 中包含的 CPU 的范围(dst 和 src 不是一个 domain,)
struct cpumask *dst_grpmask;
// 一般而言,均衡的 dst cpu 是发起均衡的 cpu,但是,如果因为 affinity 的原因,
// src 上有任务无法迁移到 dst cpu,从而不能完成均衡操作的时候,我们会选择一个新的(仍然在 local group 内)
// CPU 作为 dst cpu,发起第二轮均衡。
int new_dst_cpu;
// 在进行均衡的时候,dst_cpu 的 idle 状态,这个状态会影响均衡的走向
enum cpu_idle_type idle;
long imbalance;
// Load_balance 的过程中会有多轮的均衡操作,不同轮次的均衡会涉及不同的 cpus,
// 这个成员指明了本次均衡有哪些CPUs参与。
struct cpumask *cpus;
// 如果确定需要通过迁移任务来保持负载均衡,那么 load_balance 函数会通过循环遍历 src rq 上的 cfs task
// 链表来确定迁移的任务数量。Loop 会跟踪循环的次数,其值不能大于 Loop_max。
unsigned int flags;
unsigned int loop;
unsigned int loop_break;
unsigned int loop_max;
enum fbq_type fbq_type;
// 负载均衡的方式
enum migration_type migration_type;
// 需要进行迁移的任务链表
struct list_head tasks;
};
enum migration_type 迁移的类型
enum migration_type {
// 迁移一定的负载(什么是负载?)
migrate_load = 0,
// 迁移一定量的 utility
migrate_util,
// 迁移一定数量的任务
migrate_task,
// 迁移 misfit task
migrate_misfit
};
struct sd_lb_stats
在负载均衡的时候,通过 sd_lb_stats 数据结构来表示 domain 的负载统计信息:
// sd_lb_stats - Structure to store the statistics of a sched_domain during load balancing.
struct sd_lb_stats {
struct sched_group *busiest; // Busiest group in this domain
struct sched_group *local; // Dst 所在的 group
unsigned long total_load; // Total load of all groups in sd
unsigned long total_capacity; // Total capacity of all groups in sd,CPU 算力之和
unsigned long avg_load; // Average load across all groups in sd
unsigned int prefer_sibling; // tasks should go to sibling first
struct sg_lb_stats busiest_stat; // Statistics of the busiest group
struct sg_lb_stats local_stat; // Statistics of the local group
};
struct sg_lb_stats
/*
* sg_lb_stats - stats of a sched_group required for load_balancing
*/
struct sg_lb_stats {
unsigned long avg_load; // Avg load across the CPUs of the group
unsigned long group_load; // Total load over the CPUs of the group
unsigned long group_capacity; // 所有 CPU 算力之和
unsigned long group_util; // 所有 CPU 利用率之和
unsigned long group_runnable; // 所有 CPU 运行负载之和
unsigned int sum_nr_running; // group 里所有任务数量
unsigned int sum_h_nr_running; // 所有 cfs 任务的数量
unsigned int idle_cpus;
unsigned int group_weight;
enum group_type group_type;
unsigned int group_asym_packing; /* Tasks should be moved to preferred CPU */
unsigned long group_misfit_task_load; /* A CPU has a task too big for its capacity */
#ifdef CONFIG_NUMA_BALANCING
unsigned int nr_numa_running;
unsigned int nr_preferred_running;
#endif
};
struct sched_group_capacity
描述 group 的算力信息。
struct sched_group_capacity {
atomic_t ref;
// CPU capacity of this group, SCHED_CAPACITY_SCALE being max capacity for a single CPU.
// 该 group 中可以用于 cfs 任务的总算力(各个 CPU 算力之和)
unsigned long capacity;
unsigned long min_capacity; /* Min per-CPU capacity in group */
unsigned long max_capacity; /* Max per-CPU capacity in group */
unsigned long next_update;
int imbalance; /* XXX unrelated to capacity but shared group state */
//...
unsigned long cpumask[]; /* Balance mask */
};
任务放置(task placement)/ select_task_rq() / select_task_rq_fair() / Kernel
对于一个要执行的任务,为它选择一个 CPU。
The core scheduler invokes this function to figure out which CPU to assign a task to.This is used for distributing processes accross multiple CPUs; the core scheduler will call enqueue_task, passing the runqueue corresponding to the CPU that is returned by this function. CPU assignment obviously occurs when a process is first forked, but CPU reassignment can happen for a large variety of reasons. Here are some instances where select_task_rq is called:
任务放置主要发生在:
- 唤醒一个新 fork 的线程
- 唤醒一个阻塞的进程
- Exec 一个线程的时候(可以放置的原因是之前的 cache 变冷了,所以可以放置到一个新的 CPU 上了 )
在上面的三个场景中都会调用 select_task_rq 来为 task 选择一个适合的 CPU core。
select_task_rq_fair() 中涉及到三个重要的选核函数(任务放置的三条路径):
find_energy_efficient_cpu()find_idlest_cpu()select_idle_sibling()
表示 task placement 的各个场景,根据不同条件,最终都会进入其中某一条路径,得到任务放置 CPU 并结束此次的 task placement 过程。现在让我们来理一理这三条路径的常见进入条件以及基本的 CPU 选择考量:
if SD_BALANCE_WAKE
// 注重能耗
cpu = sched_energy_present()
if cpu == -1 and wake affine
// 快速路径,之所以快是因为可以直接从以前跑的 CPU 或者 cache hot CPU 里选
// 只有当 wake 时,说明有之前跑的统计信息,为 wake affine 时,说明对选核有偏好
return select_idle_sibling()
// 慢速路径,之所以慢是因为需要遍历所有 CPU 找最 idle 的
return find_idlest_cpu()
第一条路径:EAS 选核 find_energy_efficient_cpu()
当传入参数 sd_flag in wake_flags 为 SD_BALANCE_WAKE,并且系统配置值 sched_energy_present(即考虑性能和功耗的均衡),调度器就会进入 EAS 选核路径进行 CPU 的查找。这里涉及到内核中 Energy Aware Scheduling(EAS)机制,总之,EAS 路径在保证任务能正常运行的前提下,为任务选取使系统整体能耗最小的 CPU。如果当前平台不是异构系统,或者系统中存在超载(Over-utilization)的 CPU,EAS 就直接返回 -1,fallback 到其他路径。
EAS 机制还是参考这个:CFS任务的负载均衡(任务放置)
第二条路径:慢速路径 find_idlest_cpu()
有两种常见的情况会进入慢速路径:
- 传入
sd_flag为SD_BALANCE_WAKE,且 EAS 没有使能或者返回 -1 时,如果该任务不是 wake affine 类型,就会进入慢速路径; - 传入参数
sd_flag为SD_BALANCE_FORK、SD_BALANCE_EXEC时,由于此时的任务负载是不可信任的,无法预测其对系统能耗的影响,也会进入慢速路径。
慢速路径使用 find_idlest_cpu() 方法找到系统中最空闲的 CPU,作为放置任务的 CPU 并返回。基本的搜索流程是:
- 首先确定放置的 target domain(从 waker 的 base domain 向上,找到最底层配置相应
sd_flag的 domain), - 然后从 target domain 中找到负载最小的调度组,进而在调度组中找到负载最小的 CPU。
这种选核方式对于刚创建的任务来说,算是一种相对稳妥的做法。
第三条路径:快速路径 select_idle_sibling() / Wake affine
先说一下什么是 wake affine 类型的任务:
将此任务打包在临近的 CPU 上(如唤醒者的 CPU、上次执行的 CPU(cache 友好)、共享 cache 的 CPU):
- 既可以提高 cache 命中率,改善性能,
- 又能避免唤醒其它可能正处于 idle 状态的 CPU,节省功耗。
试图将 wakee(被唤醒者) 拉近 waker(唤醒者),这样考虑的原因是: 有唤醒关系的进程是相互关联的, 尽可能地运行在具有 cache 共享的调度域中, 这样可以获得一些 chache-hit 带来的性能提升。
传入参数 sd_flag 为 SD_BALANCE_WAKE,但 EAS 又无法发挥作用时,若该任务为 wake affine 类型任务,调度器就会进入快速路径,该路径在 CPU 的选择上,主要考虑共享 cache 且 idle 的 CPU。在满足条件的情况下:
- 优先选择任务上一次运行的 CPU(prev cpu),hot cache 的 CPU 是 wake affine 类型任务所青睐的。
- 其次是唤醒任务的 CPU(wake cpu),即 waker 所在的 CPU。当该次唤醒为 sync 唤醒时(传入参数 wake_flags 为
WF_SYNC),对 wake cpu 的 idle 状态判定将会放宽,比如 waker 为 wake cpu 唯一的任务,由于 sync 唤醒下的 waker 很快就进入阻塞状态,也可当做 idle 处理。
如果 prev cpu 或者 wake cpu 无法满足条件,那么调度器会尝试从它们的 LLC domain 中去搜索 idle 的 CPU。
// sd_flag 是 wake_flags 的一部分
// 返回值为 cpu nr
static int select_task_rq_fair(struct task_struct *p, int prev_cpu, int wake_flags)
{
int sync = (wake_flags & WF_SYNC) && !(current->flags & PF_EXITING);
struct sched_domain *tmp, *sd = NULL;
int cpu = smp_processor_id();
int new_cpu = prev_cpu;
int want_affine = 0;
/* SD_flags and WF_flags share the first nibble */
int sd_flag = wake_flags & 0xF;
/*
* required for stable ->cpus_allowed
*/
lockdep_assert_held(&p->pi_lock);
if (wake_flags & WF_TTWU) {
record_wakee(p);
if (sched_energy_enabled()) {
//
new_cpu = find_energy_efficient_cpu(p, prev_cpu);
if (new_cpu >= 0)
return new_cpu;
new_cpu = prev_cpu;
}
want_affine = !wake_wide(p) && cpumask_test_cpu(cpu, p->cpus_ptr);
}
rcu_read_lock();
for_each_domain(cpu, tmp) {
/*
* If both 'cpu' and 'prev_cpu' are part of this domain,
* cpu is a valid SD_WAKE_AFFINE target.
*/
if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) {
if (cpu != prev_cpu)
new_cpu = wake_affine(tmp, p, cpu, prev_cpu, sync);
sd = NULL; /* Prefer wake_affine over balance flags */
break;
}
/*
* Usually only true for WF_EXEC and WF_FORK, as sched_domains
* usually do not have SD_BALANCE_WAKE set. That means wakeup
* will usually go to the fast path.
*/
if (tmp->flags & sd_flag)
sd = tmp;
else if (!want_affine)
break;
}
if (unlikely(sd)) {
/* Slow path */
new_cpu = find_idlest_cpu(sd, p, cpu, prev_cpu, sd_flag);
} else if (wake_flags & WF_TTWU) { /* XXX always ? */
/* Fast path */
new_cpu = select_idle_sibling(p, prev_cpu, new_cpu);
}
rcu_read_unlock();
return new_cpu;
}
CFS Bandwidth Control
CFS调度器(5)-带宽控制 这篇文章写的非常好,值得参考。
决定的是任务组而非单个任务的上限。
不同的调度策略进程都可以进行带宽控制。这里仅讨论 SCHED_NORMAL 进程的,也就是 CFS 带宽控制。
需要开启的 config:
CONFIG_CGROUP_SCHEDCONFIG_FAIR_GROUP_SCHEDCONFIG_CFS_BANDWIDTH
CFS bandwidth control is a CONFIG_FAIR_GROUP_SCHED extension which allows the specification of the maximum CPU bandwidth available to a group or hierarchy. 所以只能针对一个 group 来设置 quota?group 内的各个子进程是不是只能再对这个 quota 进行分了?是这样的。
内核采取了一种中心式架构模型:
- 任务组
task_group就是中心端,管理 CPU 时间资源池。 - 这个
task_group在每个核上的cfs_rq作为子节点,有运行需求前需要检查本地持有的时间资源,如果不足就向中心端task_group索取直到超过 quota 那么所有这个 group 下面都会被 throttle。
The bandwidth allowed for a group is specified using a quota and period. Within each given “period” (microseconds), a task group is allocated up to “quota” microseconds of CPU time. 也就是说 control 并不是说通过限制频率为多少达成的,而是通过限制一段时间内最多跑多长时间来决定的。Throttled threads will not be able to run again until the next period when the quota is replenished. 一个 cfs_rq 在一个 period 内对于资源的申请可以是多次的,比如说每次是 5ms(默认值),如果运行完了就再申请 5ms,直到不需要申请或者 period 过了或者 quota 到了。
严格来讲,申请方是 cfs_rq,一个 task_group 在一个 CPU 上有一个 cfs_rq。
在每一个 period 结束,所有 cfs_rq 申请但是还没有用完的时间不会被置为 0,这也可以理解为是一种 burst?因为每一个 cfs_rq 是以 5ms 为单位来申请的,所以每一个 period,最多可以积攒 $5ms \times cores$ 的时间,如果 share pool 有 120 个核,那么就能有 600ms 的时间,考虑到还有时间片返还机制,应该远不会有这么多。
核心的主要流程:
// 周期性触发 cfs_rq slice 申请以及 task_group quota 检查。
// 比如说如果 CONFIG_HZ 是 1000,那么 1ms 就可以触发一次,但是如果机器是 250HZ 的话,那么只能 4ms 触发一次
// 一次申请时间片是 5ms,会不会存在不及时的情况?
// bpf 跟一下这个函数一秒钟调用多少次(大概 50 次,20ms 才一次,如果一次申请只有 5ms,够用吗?)
task_tick_fair
for_each_sched_entity(se)
update_curr
account_cfs_rq_runtime
// 这个函数其实就是为了 cfs bandwidth control 而设计的
if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)
return;
// 请看 assign_cfs_rq_runtime 的解释
__account_cfs_rq_runtime
// 减少剩下时间
cfs_rq->runtime_remaining -= delta_exec;
// 如果申请的时间片还没有用完,那么不需要做任何事
if (likely(cfs_rq->runtime_remaining > 0))
return;
// 如果申请时间片用完了,并且这个 cfs_rq 也被 throttle 了,那就这样吧。
if (cfs_rq->throttled)
return;
// 先从 task_group 那里拿时间片,如果没拿到,说明 quota 用完了,同时我们还有任务在跑
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))
// 马上把这个任务调度走,不能再让它用时间片了
resched_curr(rq_of(cfs_rq));
如何限制一个用户组中的进程呢?我们可以简单的将 task_group 管理的调度实体从对应的就绪队列上删除即可,然后标记 se 对应的 cfs_rq 的标志位。每当用户组中的进程运行一段时间时,对应的 runtime 时间也在减少。系统会启动一个高精度定时器,周期时间是 period,在定时器时间到达后重置剩余限额时间 runtime 为 quota,开始下一个轮时间跟踪。所有的用户组进程运行的时间累加在一起,保证总的运行时间小于 quota。每个用户组会管理 CPU 个数的就绪队列 cfs_rq。每个 cfs_rq 中也有限额时间,该限额时间是从全局用户组 quota 中申请。例如,周期 period 值 100ms,限额 quota 值 50ms,2 个 CPU 系统。CPU0 上 cfs_rq 首先从全局限额时间中申请 5ms 时间(此实 runtime 值为 45),然后运行进程。当 5ms 时间消耗完时,继续从全局时间限额 quota 中申请 5ms(此时 runtime 值为 40)。CPU1 上的情况也同样如此,先以就绪队列 cfs_rq 的身份从 quota 中申请一个时间片,然后供进程运行消耗。当全局 quota 剩余时间不足以满足 CPU0 或者 CPU1 申请时,就需要 throttle 对应的 cfs_rq。在定时器时间到达后,unthrottle 所有已经 throttle 的 cfs_rq。
总结一下就是,cfs_bandwidth 就像是一个全局时间池。每个 cfs_rq 如果想让其管理的红黑树上的调度实体调度,必须首先向全局时间池中申请固定的时间片,然后供其进程消耗。当时间片消耗完,继续从全局时间池中申请时间片。终有一刻,时间池中已经没有时间可供申请。此时就是 throttle cfs_rq 的大好时机。
为什么没有针对单一 task 的机制,而是直接针对了 task_group?
其实只有一个 task_group 里只有一个 task 就相当于针对单个 task 做限制了,为什么要再开发针对进程的代码呢。
进程组(struct task_group)
不要把进程组(struct task_group) 和调度组(struct sched_group) 弄混。task_group 对应一个容器吗?task_group 是可以嵌套的,这也对应了 cgroup 的逻辑。
进程组是分布式的中心,每一个 CPU 上的 cfs_rq 都指向一个进程组,表示这个 cfs_rq 属于这个进程组。task_group 在每一个 CPU 上都有一个 cfs_rq。
// Task group related information
struct task_group {
// cgroup v1 场景下,一个 css 才能看作是一个 cgroup,task_group 和这个对应还是挺合理的。
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
// 因为一个进程组可以看作一个调度实体,这个是每一个 CPU 上对于这个 task_group 的调度实体
struct sched_entity **se;
// 指向每一个 CPU 上的 runqueue
struct cfs_rq **cfs_rq;
// the task group cpu.shares, scaled by 1024 for fixed point computation.
// 表示总的 CPU 资源数量
// 和用户空间 cpu.shares 值的区别在于 scale 了一下,乘以了 1024
unsigned long shares;
// A positive value indicates that this is a SCHED_IDLE group.
int idle;
#ifdef CONFIG_SMP
/*
* load_avg can be heavily contended at clock tick time, so put
* it in its own cacheline separated from the fields above which
* will also be accessed at each tick.
*/
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
// 父 task_group
struct task_group *parent;
// 邻居 task_group
struct list_head siblings;
// 孩子 task_group 组成的链表
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
// 这个 task 相关的 bandwidth 使用情况
struct cfs_bandwidth cfs_bandwidth;
#ifdef CONFIG_UCLAMP_TASK_GROUP
/* The two decimal precision [%] value requested from user-space */
unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */
struct uclamp_se uclamp_req[UCLAMP_CNT];
/* Effective clamp values used for a task group */
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
};
struct cfs_bandwidth Kernel
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
// 这些都是直接设置好的静态的数据
ktime_t period;
// 静态限额时间
u64 quota;
// 剩余限额时间,因为会一直更新,所以是动态的
// 每当用户组中的进程运行一段时间时,对应的 runtime 时间也在减少。
// 系统会启动一个高精度定时器,周期 period,在定时器时间到达后
// 重置剩余限额时间 runtime 为 quota,开始下一个轮时间跟踪。
// 因为是多个 CPU,所以其实 quota 是可以超过 period 的。
u64 runtime;
// 用户设置的 burst 的值
u64 burst;
u64 runtime_snap;
s64 hierarchical_quota;
u8 idle;
// 用来查看某一次 slice 申请是不是这个 period 第一次申请
// i.e., 开启了这个 period。
u8 period_active;
u8 slack_started;
// 高精度定时器
struct hrtimer period_timer;
struct hrtimer slack_timer;
// 所有被 throttle 的 cfs_rq 挂入此链表
// 在定时器的回调函数中遍历链表执行 unthrottle cfs_rq 操作。
struct list_head throttled_cfs_rq;
/* Statistics: */
int nr_periods;
int nr_throttled;
int nr_burst;
u64 throttled_time;
// 统计数据,burst 的时间?
u64 burst_time;
#endif
};
从 task_group 分配时间片到 cfs_rq / assign_cfs_rq_runtime() Kernel
每一个 cfs_rq 上都有一个 task tick,周期性检查这个 CPU 对应的 cfs_rq 的时间片是否已经用完了。用完了即调用此函数进行申请。
assign_cfs_rq_runtime
// 上锁,防止别的 CPU 也同时来申请资源
raw_spin_lock(&cfs_b->lock);
// sched_cfs_bandwidth_slice() 函数返回一次申请的 slice 大小
ret = __assign_cfs_rq_runtime(cfs_b, cfs_rq, sched_cfs_bandwidth_slice());
// 解锁
raw_spin_unlock(&cfs_b->lock);
// returns 0 on failure to allocate runtime
static int __assign_cfs_rq_runtime(struct cfs_bandwidth *cfs_b, struct cfs_rq *cfs_rq, u64 target_runtime)
{
u64 min_amount, amount = 0;
// note: this is a positive sum as runtime_remaining <= 0
// runtime_remaining 是 < 0 的,说明上一次我们跑多了
// 这个值是大于 target_runtime 也就是 slice 的
min_amount = target_runtime - cfs_rq->runtime_remaining;
// 我们就没设置 quota,直接申请好了
if (cfs_b->quota == RUNTIME_INF)
amount = min_amount;
else {
// 这次申请是否开启了一个新的 period?
// 如果是那么就设置 timer
start_cfs_bandwidth(cfs_b);
if (cfs_b->runtime > 0) {
// task_group 的 quota 就剩这么点了,地主家也没余粮了,都拿了吧
amount = min(cfs_b->runtime, min_amount);
// 更新地主家余粮
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
// 拿了地主家的余粮,更新自己家的余粮
cfs_rq->runtime_remaining += amount;
// 这次申请是否真的申请到了时间片?
return cfs_rq->runtime_remaining > 0;
}
throttle_cfs_rq() / Throttle cfs_rq
我们首先要明白什么叫做 throttle 一个 cfs_rq,这个表示这个 cfs_rq 上所有的属于这个 task_group 的进程在这个 period 内都无法运行。
- 所有的
cfs_rq并不是同时被 throttle 的,而是在它自己所在的 CPU 要发生调度的时候。throttle 并不是一旦发现task_group里的 quota 用完了就会通知所有cfs_rq变成 throttle,而是在每一个cfs_rq申请时间片的时候主动进行 throttle。 - 所有被 throttle 的
cfs_rq会被串成一个链表。
// 在 enqueue 一个 task 的时候也会去检查是否要 throttle 一个时间片
enqueue_task_fair
enqueue_entity
// 我们刚刚 enqueue 的 task 是第一个 task
if (cfs_rq->nr_running == 1)
check_enqueue_throttle
throttle_cfs_rq
// tick task 周期性检查的时候,有可能会触发对于这个 cfs_rq 的 throttling
//(想要分配时间片但是 quota 用完了,分配不出来时间片)
!assign_cfs_rq_runtime()
resched_curr
TIF_NEED_RESCHED
// later on 到了调度时机
__schedule
pick_next_task
pick_next_task_fair
put_prev_task
put_prev_task_fair
put_prev_entity
check_cfs_rq_runtime
throttle_cfs_rq
// throttle 一个 cfs_rq(其实应该 throttle 这个 task_group 对应的所有 cfs_rq)
static bool throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, idle_task_delta, dequeue = 1;
/* This will start the period timer if necessary */
// 如果我们能分配 1ns runtime 成功,表示此时可能和 quota 更新的 timer race condition 了
// timer 应该刚刚更新所以我们不能 throttle,因为可能导致我们在接下来的一个 period 里都是处于 throttle 的状态。
if (__assign_cfs_rq_runtime(cfs_b, cfs_rq, 1)) {
/*
* We have raced with bandwidth becoming available, and if we
* actually throttled the timer might not unthrottle us for an
* entire period. We additionally needed to make sure that any
* subsequent check_cfs_rq_runtime calls agree not to throttle
* us, as we may commit to do cfs put_prev+pick_next, so we ask
* for 1ns of runtime rather than just check cfs_b.
*/
dequeue = 0;
} else {
list_add_tail_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq); }
// race condition
if (!dequeue)
return false; /* Throttle no longer required. */
// throttle 对应的 cfs_rq 可以将对应的 group se 从其就绪队列的红黑树上删除,
// 这样在 pick_next_task 的时候,顺着根 cfs_rq 的红黑树往下遍历,就不会找到已经 throttle 的 se,也就是没有机会运行。
// se 是一个列表,里面包含了这个 task_group 在这个 cfs_rq 上的所有 schedule entity
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];
// freeze hierarchy runnable averages while throttled
rcu_read_lock();
// task_group 不是还可以包含 task_group 吗,所以我们要一直遍历下去
// 在往下一个节点寻找的时候,我们调用 tg_throttle_down(),因为是回溯算法
// 所以往上寻找的时候不需要做什么,tg_throttle_down 负责增加 cfs_rq->throttle_count 计数。
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq);
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
idle_task_delta = cfs_rq->idle_h_nr_running;
// #define for_each_sched_entity(se) \
// for (; se; se = se->parent)
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
// 如果已经不在 rq 上了,那么直接 done 就可出了
// 怎么保证其他的 entity 也已经 done 了?
if (!se->on_rq)
goto done;
// 将这个 entity 从 cfs_rq 里移除,让其睡眠
// se->on_rq 应该会置 false。
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);
if (cfs_rq_is_idle(group_cfs_rq(se)))
idle_task_delta = cfs_rq->h_nr_running;
qcfs_rq->h_nr_running -= task_delta;
qcfs_rq->idle_h_nr_running -= idle_task_delta;
// 如果 qcfs_rq 运行的进程只有即将被 dequeue 的 se 一个的话,
// 那么 parent se 也需要 dequeue。如果 qcfs_rq->load.weight 不为 0,
// 说明 qcfs_rq 就绪队列上的进程不止 se 一个,那么 parent se 理所应当不能被 dequeue。
if (qcfs_rq->load.weight) {
/* Avoid re-evaluating load for this entity: */
se = parent_entity(se);
break;
}
}
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
if (!se->on_rq)
goto done;
update_load_avg(qcfs_rq, se, 0);
se_update_runnable(se);
if (cfs_rq_is_idle(group_cfs_rq(se)))
idle_task_delta = cfs_rq->h_nr_running;
qcfs_rq->h_nr_running -= task_delta;
qcfs_rq->idle_h_nr_running -= idle_task_delta;
}
/* At this point se is NULL and we are at root level*/
sub_nr_running(rq, task_delta);
done:
/*
* Note: distribution will already see us throttled via the
* throttled-list. rq->lock protects completion.
*/
// 设置 throttle 标志位。
cfs_rq->throttled = 1;
// 记录 throttle 的时刻。
cfs_rq->throttled_clock = rq_clock(rq);
return true;
}
unthrottle_cfs_rq() / Unthrottle cfs_rq
此操作会在两个定时器 timeout 时进行:
- period 定时器到期:更新 quota 理所应当;
- slack 定时器到期:有人还了时间,所以我们 unthrottle 那些因为时间不够而 throttle 的
cfs_rq。
// period timer 到期,更新 quota
do_sched_cfs_period_timer / do_sched_cfs_slack_timer
// 分发 runtime
distribute_cfs_runtime
unthrottle_cfs_rq
void unthrottle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, idle_task_delta;
// unthrottle 操作的做 cfs_rq 对应的调度实体们,调度实体在 parent cfs_rq 上才有机会运行。
se = cfs_rq->tg->se[cpu_of(rq)];
// unthrottle 这个 cfs_rq,所以清零。
cfs_rq->throttled = 0;
update_rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
// throttled_time 记录 cfs_rq 被 throttle 的总时间,
// throttled_clock 在 throttle_cfs_rq() 函数中记录开始 throttle 时刻。
// 因此减去就是 throttle 的总时间
cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock;
// 删除自己表示自己不再被 throttle 了
list_del_rcu(&cfs_rq->throttled_list);
raw_spin_unlock(&cfs_b->lock);
/* update hierarchical throttle state */
// 递减 cfs_rq->throttle_count 计数。
walk_tg_tree_from(cfs_rq->tg, tg_nop, tg_unthrottle_up, (void *)rq);
// 如果 unthrottle 的 cfs_rq 上没有进程,那么无需进行 enqueue 操作。
// cfs_rq->load.weight 为 0 就代表就绪队列上没有可运行的进程。
if (!cfs_rq->load.weight) {
if (!cfs_rq->on_list)
return;
/*
* Nothing to run but something to decay (on_list)?
* Complete the branch.
*/
for_each_sched_entity(se) {
if (list_add_leaf_cfs_rq(cfs_rq_of(se)))
break;
}
goto unthrottle_throttle;
}
task_delta = cfs_rq->h_nr_running;
idle_task_delta = cfs_rq->idle_h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
if (se->on_rq)
break;
// 将调度实体入队,以 wakeup 的形式
enqueue_entity(qcfs_rq, se, ENQUEUE_WAKEUP);
if (cfs_rq_is_idle(group_cfs_rq(se)))
idle_task_delta = cfs_rq->h_nr_running;
qcfs_rq->h_nr_running += task_delta;
qcfs_rq->idle_h_nr_running += idle_task_delta;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(qcfs_rq))
goto unthrottle_throttle;
}
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
update_load_avg(qcfs_rq, se, UPDATE_TG);
se_update_runnable(se);
if (cfs_rq_is_idle(group_cfs_rq(se)))
idle_task_delta = cfs_rq->h_nr_running;
qcfs_rq->h_nr_running += task_delta;
qcfs_rq->idle_h_nr_running += idle_task_delta;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(qcfs_rq))
goto unthrottle_throttle;
}
/* At this point se is NULL and we are at root level*/
add_nr_running(rq, task_delta);
unthrottle_throttle:
assert_list_leaf_cfs_rq(rq);
/* Determine whether we need to wake up potentially idle CPU: */
if (rq->curr == rq->idle && rq->cfs.nr_running)
resched_curr(rq);
}
周期 period 更新 quota
带宽的限制是以 task_group 为单位,每一个 task_group 内嵌 cfs_bandwidth 结构体。周期性的更新 quota 利用的是高精度定时器,周期是 period。定时器的初始化函数是 init_cfs_bandwidth()。
void init_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
raw_spin_lock_init(&cfs_b->lock);
cfs_b->runtime = 0;
cfs_b->quota = RUNTIME_INF;
cfs_b->period = ns_to_ktime(default_cfs_period());
cfs_b->burst = 0;
// period timer
INIT_LIST_HEAD(&cfs_b->throttled_cfs_rq);
hrtimer_init(&cfs_b->period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_PINNED);
cfs_b->period_timer.function = sched_cfs_period_timer;
// Add a random offset so that timers interleave
hrtimer_set_expires(&cfs_b->period_timer, get_random_u32_below(cfs_b->period));
// slack timer
hrtimer_init(&cfs_b->slack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->slack_timer.function = sched_cfs_slack_timer;
// 只是初始化了定时器的结构体以及回调函数,并没有开始计时
cfs_b->slack_started = false;
}
初始化两个 hrtimer,分别是 period_timer 和 slack_timer。period_timer 的回调函数是 sched_cfs_period_timer()。回调函数中刷新 quota,并调用 distribute_cfs_runtime() 函数 unthrottle cfs_rq。
Period timer / period_timer
在 period 到期的时候,不一定所有 cfs_rq 都是处于 throttle 的状态:
- 可能 quota 还没有用完;
- quota 可能用完了,但是可能有的
cfs_rq还有 remaining 的时间片没有用完,所以没有被 throttle。
对于每一个 throttle 的 cfs_rq:
- 如果是在我们这个 CPU,那么我们自己来 unthrottle;
- 如果属于别的 CPU,那么让别的 CPU 来 async unthrottle。
distribute_cfs_runtime()
分发已有的时间片给 throttled 的 cfs_rq,让其重新获得时间。
sched_cfs_period_timer
do_sched_cfs_period_timer
distribute_cfs_runtime
static bool distribute_cfs_runtime(struct cfs_bandwidth *cfs_b)
{
struct cfs_rq *local_unthrottle = NULL;
int this_cpu = smp_processor_id();
u64 runtime, remaining = 1;
bool throttled = false;
struct cfs_rq *cfs_rq;
struct rq_flags rf;
struct rq *rq;
rcu_read_lock();
// 循环遍历所有已经 throttle cfs_rq
list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs_rq, throttled_list) {
rq = rq_of(cfs_rq);
// 分到这个 cfs_rq 的时候,剩余时间已经分完了吗?
if (!remaining) {
throttled = true;
break;
}
rq_lock_irqsave(rq, &rf);
// 如果这个 rq 是没有被 throttle 的,说明上一个 period 分给它的时间片还没有用完
// 那就继续用好了。
if (!cfs_rq_throttled(cfs_rq))
goto next;
// 已经走 async unthrottle 这个 path 了,所以不需要在这里继续了。
if (!list_empty(&cfs_rq->throttled_csd_list))
goto next;
/* By the above checks, this should never be true */
// 这个 cfs_rq 剩余的 runtime 应该是 <= 0 的,毕竟应该是被 throttle 的
SCHED_WARN_ON(cfs_rq->runtime_remaining > 0);
raw_spin_lock(&cfs_b->lock);
// runtime_remaining 应该是一个负数,这里表示这个 cfs_rq 上一个 period 超出使用的时间
runtime = -cfs_rq->runtime_remaining + 1;
// 把上一个 period 超额使用的时间从我们的 quota 中减去
if (runtime > cfs_b->runtime)
runtime = cfs_b->runtime;
cfs_b->runtime -= runtime;
// 剩下的时间
remaining = cfs_b->runtime;
raw_spin_unlock(&cfs_b->lock);
// 把分配的时间给 cfs_rq
cfs_rq->runtime_remaining += runtime;
// 我们被分了新时间片
if (cfs_rq->runtime_remaining > 0) {
// 因为这个 rq 不属于我们这个 CPU,让对应的 CPU async 来 unthrottle
if (cpu_of(rq) != this_cpu || SCHED_WARN_ON(local_unthrottle))
unthrottle_cfs_rq_async(cfs_rq);
else
// 我们的 CPU 只有一个对应的 cfs_rq,所以记录下来就好了
// 不需要每遇到一个存到 list 里面
local_unthrottle = cfs_rq;
} else {
// 上一轮的债没有还完,这个 cfs_rq 仍然应该被 throttle。
throttled = true;
}
next:
rq_unlock_irqrestore(rq, &rf);
}
rcu_read_unlock();
if (local_unthrottle) {
rq = cpu_rq(this_cpu);
rq_lock_irqsave(rq, &rf);
// 我们只负责 unthrottle 我们自己 CPU 上的这个 cfs_rq
if (cfs_rq_throttled(local_unthrottle))
unthrottle_cfs_rq(local_unthrottle);
rq_unlock_irqrestore(rq, &rf);
}
return throttled;
}
时间片返还 / Slack timer / slack_timer
另外一个 slack_timer 的作用是什么呢?我们先思考另外一个问题,如果 cfs_rq 从全局时间池申请 5ms 时间片,该 cfs_rq 上只有一个进程,该进程运行 0.5ms 后就睡眠了,按照 CFS 的代码逻辑,整个 cfs_rq 对应的 group se 都会被 dequeue。
那么剩余的 4.5ms 是否应该归返给全局时间池呢? 如果不归返,可能这个进程睡眠很久,而其他 CPU 的 cfs_rq 很有可能申请不到 5ms 时间片(比如全局时间池时间剩余 4ms)导致 throttle,但是实际上可用时间是 8.5ms > 5ms。因此,我们针对这种情况会归返部分时间,可以用在其他 CPU 上消耗。这步处理的函数调用流程是 dequeue_entity()->return_cfs_rq_runtime()->__return_cfs_rq_runtime()。
- 时间片返还是在
cfs_rq上的最后一个 running 的进程 go to sleep 时触发的。 - 时间片返还的值是剩余时间减去 1ms,也就是会给自己留下 1ms 的时间,也就是并不是把所有的时间都返还,可能是为了防止有进程开始执行。
// 当一个进程 sleep 或者要从 queue 中移除的时候
dequeue_task_fair
dequeue_entity
return_cfs_rq_runtime
// 要保证没有 running 当中的进程,这样我们自己才是最后一个
// running 的,才能把没有用完的时间片进行返还。
if (!cfs_rq->runtime_enabled || cfs_rq->nr_running)
return;
__return_cfs_rq_runtime
// we know any runtime found here is valid as update_curr() precedes return
static void __return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
// min_cfs_rq_runtime 的值是 1ms,我们选择至少保留 1ms 时间给自己,剩下的时间归返全局时间池。
// 全部归返的做法也是不明智的,有可能该 cfs_rq 上很快就会有进程运行。
// 如果全部归返,进程运行的时候需要立刻去全局时间池申请,效率低。
s64 slack_runtime = cfs_rq->runtime_remaining - min_cfs_rq_runtime;
if (slack_runtime <= 0)
return;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota != RUNTIME_INF) {
// 归返全局时间池 slack_runtime 时间。
cfs_b->runtime += slack_runtime;
/* we are under rq->lock, defer unthrottling using a timer */
if (cfs_b->runtime > sched_cfs_bandwidth_slice() && !list_empty(&cfs_b->throttled_cfs_rq))
// 开启 slack_timer 定时器条件有 2 个(从注释可以得知,使用定时器而不是直接 unthrottle 的原因是
// 当前持有 rq->lock 锁,因此需要等着部分代码退出后再进行分配)。
// - 返还之后全局时间池的时间大于 5ms,这样才有可能供其他 cfs_rq 申请时间片(最小申请时间片大小是 5ms)。
// - 已经存在 throttle 的 cfs_rq(因为这个原因被饿到了),现在开启 slack_timer,
// 在回调函数中尝试分配时间片,并 unthrottle cfs_rq。
start_cfs_slack_bandwidth(cfs_b);
}
raw_spin_unlock(&cfs_b->lock);
// cfs_rq 剩余可用时间减少,因为已经返还了
cfs_rq->runtime_remaining -= slack_runtime;
}
// timer expire 会触发此函数,主要用来分配时间并 unthrottle 进程
sched_cfs_slack_timer
do_sched_cfs_slack_timer
// This is done with a timer (instead of inline with bandwidth return) since
// it's necessary to juggle rq->locks to unthrottle their respective cfs_rqs.
static void do_sched_cfs_slack_timer(struct cfs_bandwidth *cfs_b)
{
u64 runtime = 0, slice = sched_cfs_bandwidth_slice();
unsigned long flags;
// confirm we're still not at a refresh boundary
raw_spin_lock_irqsave(&cfs_b->lock, flags);
cfs_b->slack_started = false;
// 检查 period_timer 定时时间是否即将到来,如果 period_timer 时间到了会刷新全局时间池。
// 因此借助于 period_timer 即可 unthrottle cfs_rq。反之,那么需要借助当前函数 unthrottle cfs_rq。
if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) {
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
return;
}
// 全局时间池剩余可运行时间必须大于 slice(默认5ms),因为 cfs_rq 申请时间片的单位是5ms。
if (cfs_b->quota != RUNTIME_INF && cfs_b->runtime > slice)
runtime = cfs_b->runtime;
raw_spin_unlock_irqrestore(&cfs_b->lock, flags);
if (!runtime)
return;
// 可以 unthrottle 多少个 cfs_rq,就 unthrottle 几个 cfs_rq,尽力而为。
distribute_cfs_runtime(cfs_b);
}
Burst in CFS Bandwidth Control
Work better for bursty, latency-sensitive workloads.The burstable CFS bandwidth controller [LWN.net]
最后被 merge 进去的 Patchset: [PATCH v6 0/3] sched/fair: Burstable CFS bandwidth controller - Huaixin Chang 这个 patchset 代码行数非常少,并且只需要看第一个 patch 就可以了。
前面所有 period 没用完的都可以累加,从代码中可以看出来。
for example, setting quota to 50000 and period to 100000 will enable the group to consume 50ms of CPU time in every 100ms period. Halving those values allows 25ms of CPU time every 50ms. In both cases, the group has been empowered to consume 50% of one CPU, but in the latter case that time will come more frequently, in smaller chunks.
The distinction between those two cases is important here. Imagine a control group containing a single process that needs to run for 30ms.
- In the first case, 30ms is less than the allowed 50ms, so the process will be able to complete its task without being throttled.(相当于延迟是 30ms)
- In the second case, the process will be cut off after running for 25ms; it will then have to wait for the next 50ms period to start before it can finish its job.(相当于延迟是 55ms)
A given process may use far less than its quota during most periods, but occasionally a burst of work may come along that requires more CPU time than the quota allows.
- In cases where latency doesn't matter, making that process wait for the next period to finish its work may not be a problem;
- if latency does matter, though, this delay can be a real concern.
目前的解决方式有两种:
- One, of course, is to just give the process in question a quota that is large enough to handle the workload bursts, but doing that will enable the process to consume more CPU time overall. System administrators may not like that result, especially if there is money involved and only so much time is actually being paid for.
- The alternative would be to increase both the quota and the period, but that, too, can increase latency if the process ends up waiting for the next period anyway.
Chang's patch set enables a different approach: allow control groups to carry over some of their unused quota from one period to the next. A new parameter, cpu.cfs_burst_us, sets the maximum amount of time that can be accumulated that way. As an example, let's return to the group with a quota of 25ms and a period of 50ms. If cpu.cfs_burst_us is set to 40000 (40ms), then processes in that group can run for up to 40ms in a given period, but only if they have carried over the 15ms beyond their normal quota from previous periods.(也就是最高 burst 到 40ms,即使 quota 是 25ms 我们可以从之前的 period 借 15ms) This allows the group to respond to a burst of work while still keeping it within the quota in the longer term.
给 cfs_bandwidth 这个数据结构新加了一个属性,叫做 burst。 用户通过 command line 设置之后在内核中会存在 cfs_b->burst 里面。
static u64 cpu_cfs_burst_read_u64(struct cgroup_subsys_state *css, struct cftype *cft)
{
// 正常的 get burst 值
return tg_get_cfs_burst(css_tg(css));
}
static int cpu_cfs_burst_write_u64(struct cgroup_subsys_state *css, struct cftype *cftype, u64 cfs_burst_us)
{
// 正常的 set burst 值
return tg_set_cfs_burst(css_tg(css), cfs_burst_us);
}
每一次 period 结束要重新 fill quota 的时候,
void __refill_cfs_bandwidth_runtime(struct cfs_bandwidth *cfs_b)
{
//...
// 本来是 cfs_b->runtime = cfs_b->quota;
// 现在成了 +=,表示前面所有 period 没跑完的可以留到下一个 period 跑了
// 就这么一直累计下去。cfs_b->runtime 包含了上一周期,上上周期,上上上周期等等等等
// 攒下来的可用值。
cfs_b->runtime += cfs_b->quota;
//...
// runtime 表示剩余能用的量,下面就是把 runtime
// 在 runtime 和 quota + burst 当中取最小值,防止超过 burst 所能 burst 的最大值
cfs_b->runtime = min(cfs_b->runtime, cfs_b->quota + cfs_b->burst);
//...
}
代码没了,就这些。
How to use CFS Bandwidth Control from user's point of view?
CFS bandwidth control 提供的接口是以 cgroupfs 的形式呈现。提供以下三个文件。
-
cpu.cfs_quota_us: quota -
cpu.cfs_period_us: period -
cpu.stat: 相关状态信息
默认情况下 cpu.cfs_quota_us=-1,cpu.cfs_period_us=100ms。quota 的值为 -1,代表不限制带宽。quota 和 period 合法值范围是 1ms~1000ms。除此之外还需要考虑层级关系。
cfs_rq 向全局时间池申请时间片固定大小默认是 5ms,当然该值也是可以更改的。文件路径如下:/proc/sys/kernel/sched_cfs_bandwidth_slice_us。
cpu.stat 文件会输出以下 3 点信息:
-
nr_periods: 目前已经经历 period 数; -
nr_throttled: 发生 throttle 的次数; -
throttled_time: 调度实体总的限制时间和。
任务组层级限制:cpu.cfs_quota_us 和 cpu.cfs_period_us 接口可以将一个 task_group 带宽控制在:$max(c_i) <= C$(这里 $C$ 代表 parent task_group 带宽,$c_i$ 代表它的 children taskgroup)。
- 所有的 children task_group 中最大带宽不能超过 parent task_group 带宽。
- 但是,允许所有的 children task_group 带宽总额大于 parent task_group 带宽。即:$sum(c_i) >= C$。这是因为不一定所有的 child group 都能跑满带宽。
所以,task_group 被 throttle 有两种可能原因:
- task_group 在一个周期时间内消耗完自己的 quota
- parent task_group 在一个周期时间内消耗完自己的 quota
第 2 种情况下,虽然 child task_group 仍然剩余 quota 没有消耗,但是 child task_group 也必须等到 parent task_group 下个周期时间到来。
调度里的时钟
代码主要在这个文件中:kernel/sched/clock.c。
EEVDF 调度算法
EEVDF 现在已经融入到 CFS 的 code 当中了,相当于是一种对于 CFS 的补完和重写。都在 kernel/sched/fair.c 下面。可见有了 EEVDF 就没有办法用 CFS 了。EEVDF released in kernel version 6.6,所以如果我们想查看 CFS 的代码,就切回 6.5 去看。
Core Scheduling
可以是出于安全的考虑,也可以是出于性能的考虑,让互相信任的进程能够跑在同一个 Core 的 SMT 对端。
Forcing a sibling to not run any tasks if it cannot find a runnable trusted task in the same group as the other sibling.
Core scheduling was merged for the 5.14 kernel release.
In abstract terms, each process is assigned a "cookie" that identifies it in some way; one approach might be to give each user a unique cookie. The scheduler then enforces a regime where processes can share an SMT core only if they have the same cookie value — only if they trust each other, in other words.
Core scheduling lands in 5.14 [LWN.net]
组调度
组调度(task_group)对应 Linux cgroup(control group) 的 CPU 子系统来实现的,可以将进程进行分组,按组来分配 CPU 资源等。
组调度和带宽控制联系很紧密。
struct task_struct * pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) {
struct cfs_rq *cfs_rq = &rq->cfs;
//...
// 一层一层向下选,直到选到的 se 没有 cfs_rq,也就是 是一个 task 为止。
do {
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
// task 转成 process
p = task_of(se);
//...
}
CFS 调度器管理的是 sched_entity 调度实体,task_struct(代表进程)和 task_group(代表进程组)中分别包含 sched_entity,进而来参与调度;
- 内核维护了一个全局链表
task_groups,创建的task_group会添加到这个链表中; - 内核定义了
root_task_group全局结构,充当task_group的根节点,以它为根构建树状结构; -
struct cfs_rq包含了红黑树结构,sched_entity调度实体参与调度时,都会挂入到红黑树中,task_struct和task_group都属于被调度对象;
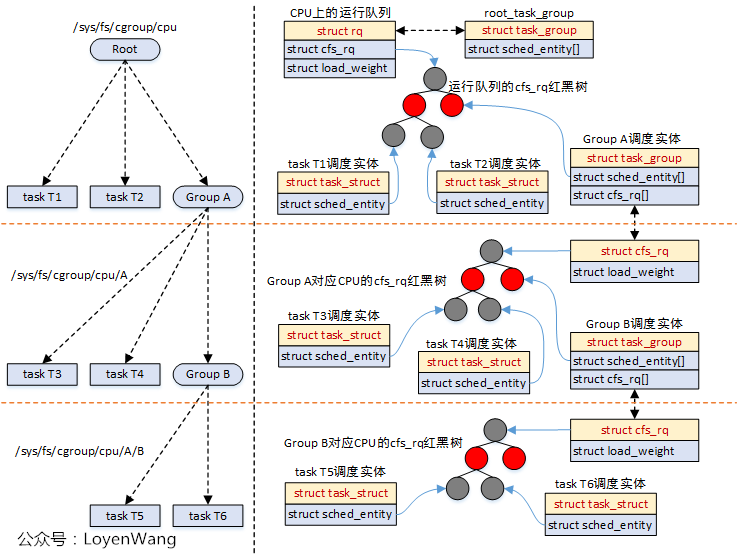
【原创】(四)Linux进程调度-组调度及带宽控制 - LoyenWang - 博客园
Schedule Features sched_feat
kernel/sched/features.h 这个文件里面:
SCHED_FEAT(GENTLE_FAIR_SLEEPERS, true)
SCHED_FEAT(START_DEBIT, true)
SCHED_FEAT(NEXT_BUDDY, false)
//...
虚拟化场景下的调度
KVM 的 vCPU 的整个生命周期都在 QEMU 线程的上下文中,在 Kernel(root 模式)、User(root 模式)、Guest(non-root 模式)下互相切换。其中每个 vCPU 对应一个 QEMU 线程,直接使用 host 内核中的调度器进行调度。
vruntime 的统计本质上还是基于时钟中断。时钟中断处理程序中会分析当前 CPU 处于 ring0 还是 ring3(不区分 root 和 non root),继而更新进程时间统计量。
Virtual-machine scheduling and scheduling in virtual machines [LWN.net]
跨 NUMA 调度 vCPU 线程的性能影响
LNCS 8299 - A User-Level NUMA-Aware Scheduler for Optimizing Virtual Machine Performance
vCPU 迁移到另一个物理核和把 vCPU 上跑的进程迁移到另一个 vCPU
这两者之间性能差距大概有多少?
当一个 vcpu 要被宿主机调度到其他线程的时候,可不可以通过某种 pv 的机制 ping guest,让 guest 主动把 vcpu 里的线程调度到其他 vcpu,而不是说直接调度 vcpu 线程?
Guest 进程调度和 Host 进程调度的差异
KVM 绑核策略
一个物理 CPU 可以有多个 vCPU (VMCS),QEMU 启动的时候可以绑定 QEMU vCPU 线程到每一个独立的物理 CPU 从而让 VM 性能最大化(不会发生争抢)。
VMCS Migration / vCPU Scheduling
当 vCPU 线程被调度到其他的 pCPU 上时,其实 VMCS 不需要也 migrate 过去,因为 VMCS 是内存中的一片区域,在任何一个物理的 CPU 上都能访问到这一片内存区域。
被调度出去的 vCPU 线程(KVM 线程)在被调度到一个新的 CPU 上后会执行 VMPTRLD 指令把自己内存中的 VMCS 地址写入,这个指令 Marks the current-VMCS pointer valid and loads it with the physical address in the instruction operand,后面再运行 VMRESUME 的时候就能保证是我们之前的 VMCS 了。
首先发生调度的时候,肯定会发生 VMExit,所以能够保证 VM 是处于 root mode 的。
// 初始化了一个 preempt_notifier^,当发生调度的时候会调度到这里
preempt_notifier_init(&vcpu->preempt_notifier, &kvm_preempt_ops);
// 两个钩子函数,当此线程发生调度的时候,我们可以在调度进来和调度出去时触发对应的函数进行处理。
kvm_preempt_ops.sched_in = kvm_sched_in;
kvm_preempt_ops.sched_out = kvm_sched_out;
// 当我们这个线程被调度进来时,我们需要 vmptrld
// 指令来重新在新的物理 CPU 上 load 一下之前的 VMCS pointer
kvm_sched_in
kvm_arch_vcpu_load
kvm_x86_ops.vcpu_load(vcpu, cpu);
.vcpu_load = vmx_vcpu_load
vmx_vcpu_load
// 将 VMCS 从之前的 cpu 解绑,将 VMCS 绑定到被调度到的 CPU 上。
vmx_vcpu_load_vmcs
bool already_loaded = vmx->loaded_vmcs->cpu == cpu;
// VMCS 之前所在的 CPU 和我们要 load 上的 CPU 不是同一个 CPU
if (!already_loaded)
// 从之前的 CPU 上 clear 掉我们自己的 VMCS
vmclear 指令
// 每一个 CPU 只能有一个 current 的 VMCS,找到
// 我们要 load 的 CPU 当前对应的 current VMCS。
prev = per_cpu(current_vmcs, cpu);
// 表示当前 CPU load 的 VMCS 和我们要 load 的不一样
if (prev != vmx->loaded_vmcs->vmcs)
vmcs_load
vmx_asm1(vmptrld, "m"(phys_addr), vmcs, phys_addr);
vCPU 线程调度出去其实不需要更多的特殊处理,与普通线程调度无异。唯一的区别在于有 kvm_sched_in() 和 kvm_sched_out() 这两个钩子需要执行(其实可以看作 vCPU 线程自己的 context switch)。
vCPU scheduling cost
VM 中一个 vCPU 遇到 Spinlock 等待另一个被 throttle 的 vCPU ,如何进行调度?/ PLE / Pause Loop Exiting
前置知识:PAUSE 指令^。
When excessive spinning is detected, an Intel processor raises an event called Pause Loop Exit (PLE), and the control is transferred to the hypervisor. The hypervisor gains a chance to reschedule vCPUs to solve the root cause of excessive vCPU spinning.
由于 KVM 中不会使能 "PAUSE exiting" feature,因此单一的 PAUSE 指令不会导致 vmexit,KVM 中只使用 "PAUSE-loop exiting" feature,即循环 (loop-wait) 中的 PAUSE 指令会导致 vmexit,具体情境为:当一个循环中的两次 PAUSE 之间的时间差不超过 PLE_gap 常量,且该循环中某次 PAUSE 指令与第一次 PAUSE 指令的时间差超过了 PLE_window,那么就会产生一个 vmexit,触发原因 field 会填为 PAUSE 指令。
当然也有一些缺陷,具体请看这一篇论文:Revisiting VM-Agnostic KVM vCPU Scheduler for Mitigating Excessive vCPU Spinning | IEEE Journals & Magazine | IEEE Xplore
"PAUSE-loop exiting" 和 pv_spinlock 的区别?
- 一个是主动的,软件上的,在 spinlock 的时候主动进行 PV 出来,
- 一个是被动的,硬件上的,当 hardware 监测到很多 PAUSE 的时候会 exit 出来。
If you have pv spinlocks, the processor in the end will never or almost never do a pause-loop exit. PLE is mostly for legacy guests that doesn't have pv spinlocks.
PV sched yield
When sending a call-function IPI-many to vCPUs, yield(by hypercall) if any of the IPI target vCPU was preempted, yield to(让步于) the first preempted target vCPU which we found.
如果 IPI 的 source vCPU 不 yield to the preempted target vCPU 的话,source vCPU 在 Non-root mode 下依然会 busy waiting(参考 smp_call_function_many_cond 函数),直到 preempted target vCPU 被调度到 Non-root mode 后才结束;还不如直接 yield source vCPU,yield to the preempted target vCPU(将执行权交给这个 vCPU)。
怎么打开这个 feature 呢?
Notes about PV sched yield - L
pv_spinlock
instead of spining while the vCPU can’t get the spinlock, it will execute halt instruction and let the other vCPU got scheduled. When the vCPU can get the spinlock, allows a vCPU to kick the target vCPU out of halt state.
是比 PLE 更高级的,If you have pv spinlocks, the processor in the end will never or almost never do a pause-loop exit. PLE is mostly for legacy guests that doesn't have pv spinlocks.
Notes about Paravirtualized ticket spinlocks - L
VM 里的进程由谁来调度?
我们先看看进程切换在 host 上需要什么:需要 save 很多寄存器(包含 RIP, CR3 等等),然后 load 别的进程的对应的寄存器。 并没有一个指令能够完成进程的切换,这些都是软件完成的。
Host scheduler 和 guest scheduler 是用不同的 APIC timer 来调度的。
- 当 host APIC 发生 timer interrupt 的时候,如果此时 guest 在运行(处于 non-root mode),那么 guest 一定会 vmexit 出来(KVM 默认是把
external-interrupt exiting置 1 的,所以一定会 exit 出来,你会说不是还有 VT-x posted interrupt 吗?怎么确定不会直接注入到 vcpu 里了呢进去呢?首先请复习一下 posted interupt,因为注入的话是需要填 PID.PIR 以及发 notification vector 的,这个和 timer interrupt 发生时的 irq 号是不一样的,代码中可以保证):
#ifdef CONFIG_HAVE_KVM
#define POSTED_INTR_VECTOR 0xf2
#define POSTED_INTR_WAKEUP_VECTOR 0xf1
#define POSTED_INTR_NESTED_VECTOR 0xf0
#endif
- Guest 刚开始没有 APIC-timer virtualization 的时候,guest 一直用的是 APIC 的 one-shot 模式而不是 periodical 模式,这样每次 non-root kernel mode 写 TSC DEADLINE MSR 的时候,都会 VM exit 出来从而能让 KVM 介入;
- 有了 APIC-timer virtualization 之后,对
IA32_TSC_DEADLINE的写不会触发 VM-exit, 硬件会利用 guest deadline 与 physical TSC 相比,当 physical TSC 大于等于 guest deadline 时,就会给 non-root mode 的 vCPU 注入 timer 中断。
应该是由 guest kernel 来进行调度的。因为从 host kernel 看来,只有 vCPU 线程,虽然 guest 里 RIP, CR3 在做 guest 内进程切换的时候在 non-root mode 变来变去, 这些在 VMexit 的时候不管 RIP 是多少都会保存到 guest state area 里面,在这里可以看到,guest state area 其实是有 RIP 域的:cpu-internals/VMCS-Layout.pdf at master · LordNoteworthy/cpu-internals,因此在 host 看来,vCPU 所对应的 QEMU vCPU thread 在 kernel 里其实也仅仅是一个 task_struct 而已,即使 exit 出来,KVM 或者 QEMU userspace handle,也都是这个线程内部在做的事情。如果 host 调度时:
- 应该不可能是在 guest (non-root mode) 里面的,因为发生调度说明 host 在运行,此时即使 guest 在跑也早已经 vmexit 出来了,不然如果跑在 non-root 模式的话我们 host 上的程序是没有机会跑的。毕竟一个 CPU 同时只能跑一个程序。
- 如果是在 root mode 的 kernel(KVM) 或者 userspace(QEMU),那么简单,像平时一样 save and restore 其实就好了。
virtual machine - How does process switch take place in VM? - Super User 这个问题是相关的,但是没有解释清楚。
KVM HLT Polling 对调度的影响
BVT(Borrowed Virtual Time) 调度算法
虚拟机调度. 法。
起初的 Patch 在这里,看代码实现非常简单:Borrowed Virtual Time patch against Linux 3.5.0 但是因为是很久之前的了,很多代码在内核中已经找不到了。
如果一个进程一直在睡眠,那么它的 vruntime 是非常小的,当睡眠中的进程被唤醒时,基于 CFS 的调度逻辑,会一直持续运行当前进程,直到 vruntime 不是最小的时候,才会选择下一个进程来调度。
内核为了解决 sleep 进程获得过长时间的问题,增加了一个阈值限制,当进程被唤醒时,取当前运行队列的最小 vruntime,并 + 上一个偏移量,这个偏移量默认是 1/2 个调度周期,12ms,将这个值设计为刚刚唤醒的 task 的 vruntime 的最小值,不能小于这个值。
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
// 当前运行队列最小的 vruntime
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
// sleeps up to a single latency don't count.
// 唤醒的进程,而不是新 fork 出来的一个新进程。
if (!initial) {
unsigned long thresh;
if (se_is_idle(se))
thresh = sysctl_sched_min_granularity;
else
thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
// 1/2 个调度周期
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/*
* Pull vruntime of the entity being placed to the base level of
* cfs_rq, to prevent boosting it if placed backwards.
* However, min_vruntime can advance much faster than real time, with
* the extreme being when an entity with the minimal weight always runs
* on the cfs_rq. If the waking entity slept for a long time, its
* vruntime difference from min_vruntime may overflow s64 and their
* comparison may get inversed, so ignore the entity's original
* vruntime in that case.
* The maximal vruntime speedup is given by the ratio of normal to
* minimal weight: scale_load_down(NICE_0_LOAD) / MIN_SHARES.
* When placing a migrated waking entity, its exec_start has been set
* from a different rq. In order to take into account a possible
* divergence between new and prev rq's clocks task because of irq and
* stolen time, we take an additional margin.
* So, cutting off on the sleep time of
* 2^63 / scale_load_down(NICE_0_LOAD) ~ 104 days
* should be safe.
*/
if (entity_is_long_sleeper(se))
se->vruntime = vruntime;
else
// 保证了最小不能小于这个值。
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
Revisting 论文解读
云厂商喜欢超卖 vCPU,比如说一个物理 CPU 上放置多个 vCPU。
现在的 KVM 在调度上面临着三个问题:
- Scheduler mismatch: KVM vCPU scheduler gives a hint to the host OS scheduler, but scheduler mismatch occurs if the host OS scheduler eventually ignores the hint because it contradicts the host scheduling policy.
- Aggressive candidate limiting: KVM does not always correctly identify the exact root cause of excessive vCPU spinning. The KVM vCPU scheduler attempts to limit candidate vCPUs to avoid boosting vCPUs that are less likely to be a root cause. Aggressive candidate limiting occurs if the vCPU scheduler misjudges the root cause and excludes the root-cause vCPU from the candidates.
- IPI context misuse: IPI context misuse is a major cause of this phenomenon.
求物之妙,如系风捕景,能使是物了然于心者,千万人而不一遇也。